 الحوار 2020 ، انتهى مؤتمرا علميا دوليا حول اللغويات الحاسوبية والتكنولوجيا الذكية. لأول مرة ، أصبحت مدرسة Phystech للرياضيات التطبيقية والمعلوماتية (FPMI) التابعة لـ MIPT شريكًا في المؤتمر . تقليديا ، أحد الأحداث الرئيسية للحوار هو تقييم الحوار ، وهي منافسة بين مطوري الأنظمة الآلية لتحليل النص اللغوي. لقد تحدثنا بالفعل على حبري حول المهام التي المشاركين في مسابقة حل العام الماضي، على سبيل المثال، عن توليد عناوين و العثور على الكلمات في عداد المفقودين في النص. تحدثنا اليوم مع الفائزين في مسارين لتقييم الحوار لهذا العام - فلاديسلاف كورزون ودانييل أناستاسييف - حول سبب قرارهم المشاركة في المسابقات التكنولوجية ، وما هي المشاكل وطرق حلها ، وما يهتم به الرجال ، وأين درسوا وما الذي يخططون للقيام به في المستقبل. مرحبا بكم في القط!
الحوار 2020 ، انتهى مؤتمرا علميا دوليا حول اللغويات الحاسوبية والتكنولوجيا الذكية. لأول مرة ، أصبحت مدرسة Phystech للرياضيات التطبيقية والمعلوماتية (FPMI) التابعة لـ MIPT شريكًا في المؤتمر . تقليديا ، أحد الأحداث الرئيسية للحوار هو تقييم الحوار ، وهي منافسة بين مطوري الأنظمة الآلية لتحليل النص اللغوي. لقد تحدثنا بالفعل على حبري حول المهام التي المشاركين في مسابقة حل العام الماضي، على سبيل المثال، عن توليد عناوين و العثور على الكلمات في عداد المفقودين في النص. تحدثنا اليوم مع الفائزين في مسارين لتقييم الحوار لهذا العام - فلاديسلاف كورزون ودانييل أناستاسييف - حول سبب قرارهم المشاركة في المسابقات التكنولوجية ، وما هي المشاكل وطرق حلها ، وما يهتم به الرجال ، وأين درسوا وما الذي يخططون للقيام به في المستقبل. مرحبا بكم في القط!
فلاديسلاف كورزون ، الفائز بمسار تقييم الحوار RuREBus-2020

ماذا تعمل؟
أنا مطور في NLP Advanced Research Group في ABBYY. نعمل حاليًا على حل مهمة تعلم من طلقة واحدة لاستخراج الكيانات. بمعنى ، مع وجود عينة تدريب صغيرة (5-10 مستندات) ، تحتاج إلى معرفة كيفية استخراج كيانات محددة من مستندات مماثلة. لهذا ، سنستخدم مخرجات نموذج NER المدرب على أنواع الكيانات القياسية (الشخص والموقع والمؤسسة) كميزات لحل هذه المشكلة. نخطط أيضًا لاستخدام نموذج لغوي خاص ، تم تدريبه على المستندات المشابهة في موضوع مهمتنا.
ما المهام التي قمت بحلها في تقييم الحوار؟
في الحوار ، شاركت في مسابقة RuREBus المخصصة لاستخراج الكيانات والعلاقات من وثائق محددة من مجموعة وزارة التنمية الاقتصادية. كانت هذه الحالة مختلفة تمامًا عن الحالات المستخدمة ، على سبيل المثال ، في مسابقة كونل . أولاً ، لم تكن أنواع الكيانات نفسها قياسية (الأشخاص والمواقع والمنظمات) ، ومن بينها كانت هناك إجراءات موضوعية وغير مسماة. ثانيًا ، لم تكن النصوص نفسها عبارة عن مجموعات من الجمل التي تم التحقق منها ، بل وثائق حقيقية ، مما أدى إلى قوائم وعناوين مختلفة وحتى جداول. ونتيجة لذلك ، نشأت الصعوبات الرئيسية على وجه التحديد مع معالجة البيانات ، وليس مع حل المشكلة. في الواقع ، هذه هي المهام الكلاسيكية للتعرف على الكيان واستخراج العلاقة.
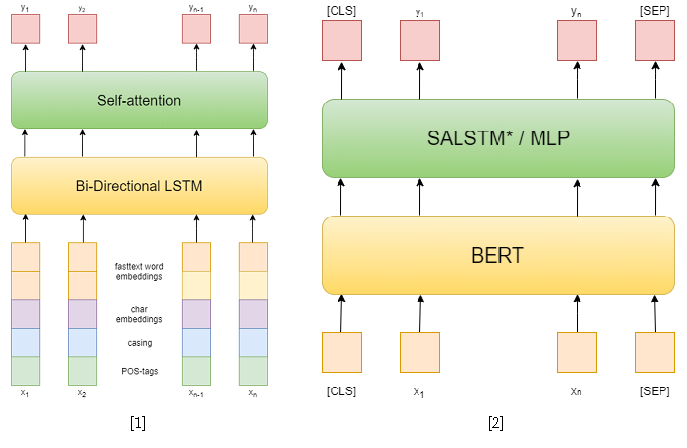
في المسابقة نفسها ، كان هناك 3 مسارات: NER و RE مع كيانات معينة و RE من طرف إلى طرف. حاولت حل الأولين. في المهمة الأولى ، استخدمت الأساليب الكلاسيكية. أولاً ، حاولت استخدام شبكة متكررة كنموذج ، وتضمين كلمة النص السريع ، وأنماط الكتابة بالأحرف الكبيرة ، والتضمينات الرمزية وعلامات نقطة البيع كميزات [1]. ثم استخدمت بالفعل العديد من BERTs سابقة التدريب [2] ، والتي تتفوق تمامًا على نهجي السابق. ومع ذلك ، لم يكن هذا كافيًا ليحتل المركز الأول في هذا المسار.
ولكن في المسار الثاني نجحت. لحل مشكلة استخراج العلاقات ، قمت بتقليصها إلى مشكلة تصنيف العلاقات ، على غرار المهمة 8 SemEval 2010 . في هذه المشكلة ، لكل جملة ، يتم إعطاء زوج واحد من الكيانات ، والذي يجب تصنيف العلاقة له. وفي المسار ، يمكن أن تحتوي كل جملة على العديد من الكيانات كما تريد ، ومع ذلك ، فإنها ببساطة تختزل إلى السابقة من خلال أخذ عينات من الجملة لكل زوج من الكيانات. أيضا ، أثناء التدريب ، أخذت أمثلة سلبية عشوائيا لكل جملة بحجم لا يتجاوز ضعف عدد الإيجابيات من أجل تقليل عينة التدريب.
كطرق لحل مشكلة تصنيف العلاقات ، استخدمت نموذجين يعتمدان على BERT-e. في النوع الأول ، قمت ببساطة بربط مخرجات BERT مع عمليات تضمين NER ثم قمت بوضع متوسط الميزات لكل رمز مميز باستخدام الانتباه الذاتي [3]. أحد أفضل الحلول للمهمة 8 من SemEval 2010 - R-BERT [4] تم اعتباره النموذج الثاني. جوهر هذا النهج هو كما يلي: إدراج رموز مميزة خاصة قبل وبعد كل كيان ، ومتوسط مخرجات BERT لرموز كل كيان ، ودمج المتجهات الناتجة مع الناتج المقابل لرمز CLS ، وتصنيف ناقل الميزة الناتج. ونتيجة لذلك ، احتل هذا النموذج المرتبة الأولى في المسار. نتائج المسابقة متاحة هنا .
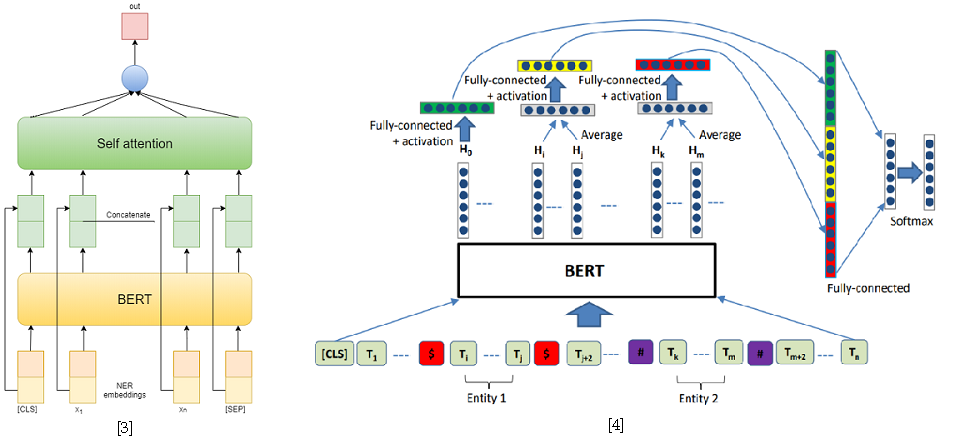
[4] Wu، S.، He، Y. (2019، November). إثراء نموذج اللغة المدرب مسبقًا بمعلومات الكيان لتصنيف العلاقات. في وقائع المؤتمر الدولي الثامن والعشرين ACM حول إدارة المعلومات والمعرفة ( ص 2361-2364 ).
ما أصعب ما بدا لك في هذه المهام؟
كانت معالجة القضية الأكثر إشكالية. المهام نفسها كلاسيكية قدر الإمكان ، لحلها هناك بالفعل أطر جاهزة ، على سبيل المثال ، AllenNLP. ولكن يجب إعطاء الإجابة مع حفظ امتداد الرمز المميز ، لذلك لم أستطع فقط استخدام خط الأنابيب الجاهز دون كتابة الكثير من التعليمات البرمجية الإضافية. لذلك ، قررت كتابة خط الأنابيب بالكامل في PyTorch النقي حتى لا تفوت أي شيء. على الرغم من أنني ما زلت استخدم بعض الوحدات من AllenNLP.
كانت هناك أيضًا العديد من الجمل الطويلة إلى حد ما في الجسم ، مما تسبب في إزعاج عند تدريس المحولات الكبيرة ، على سبيل المثال ، BERT ، لأن أصبحوا يطالبون بذاكرة الفيديو مع زيادة مدة الجملة. ومع ذلك ، فإن معظم هذه الجمل عبارة عن تعدادات بفواصل منقوطة ويمكن فصلها بواسطة هذه الشخصية. لقد قمت ببساطة بتقسيم العروض المتبقية على الحد الأقصى لعدد الرموز المميزة.
هل شاركت في الحوار والمسارات من قبل؟
في العام الماضي تحدثت مع درجة الماجستير في جلسة الطلاب.
لماذا قررت المشاركة في المسابقة هذا العام؟
في هذا الوقت ، كنت فقط أحل مشكلة استخراج العلاقات ، ولكن لفيلق مختلف. حاولت استخدام نهج مختلف يعتمد على تحليل الأشجار. تم استخدام المسار في الشجرة من كيان إلى آخر كمدخل. لكن هذا النهج ، للأسف ، لم يُظهر نتائج قوية ، على الرغم من أنه كان على مستوى مع النهج القائم على الشبكات المتكررة ، باستخدام التضمين المميز والميزات الأخرى كعلامات ، مثل طول المسار من رمز إلى جذر أو أحد الكيانات في الشجرة النحوية. التحليل ، وكذلك الوضع النسبي للكيانات.
في هذه المسابقة ، قررت المشاركة ، لأن لدي بالفعل بعض الأسس لحل مشاكل مماثلة. ولماذا لا تطبقها في مسابقة وتنشر؟ لم يكن الأمر سهلاً كما اعتقدت ، ولكنه بالأحرى بسبب مشاكل في التفاعل مع الهياكل. ونتيجة لذلك ، كانت بالنسبة لي مهمة هندسية أكثر منها بحثية.
هل شاركت في مسابقات أخرى؟
في الوقت نفسه ، شارك فريقنا في SemEval . شاركت إيليا ديموف بشكل رئيسي في المهمة ، لقد اقترحت للتو بعض الأفكار. كانت هناك مهمة تصنيف الدعاية: تم اختيار مدى النص وكان من الضروري تصنيفه. اقترحت استخدام نهج R-BERT ، أي لتحديد هذا الكيان في الرموز المميزة ، وإدراج رمز مميز أمامه وبعده ، ومتوسط المخرجات. ونتيجة لذلك ، أعطى هذا زيادة صغيرة. هذه هي القيمة العلمية: لحل المشكلة ، استخدمنا نموذجًا مصممًا لشيء مختلف تمامًا.
شاركت أيضًا في ABBYY hackathon في ACM icpc - المنافسة في البرمجة الرياضية في السنوات الأولى. لم نتقدم كثيرًا في ذلك الوقت ، لكن الأمر كان ممتعاً. تختلف هذه المسابقات اختلافًا كبيرًا عن تلك المقدمة في الحوار ، حيث يتوفر الوقت الكافي لتطبيق واختبار العديد من المناهج بهدوء. في الهاكاثون ، عليك القيام بكل شيء بسرعة ، ليس هناك وقت للاسترخاء ، لا يوجد شاي. ولكن هذا هو جمال هذه الأحداث - لديهم جو معين.
ما هي المشاكل الأكثر إثارة للاهتمام التي قمت بحلها في المسابقات أو في العمل؟
ستقام قريبًا منافسة GENEA لجيل الإيماءات وسأذهب إلى هناك. أعتقد أنها ستكون مثيرة للاهتمام. هذه ورشة عمل في ACM - المؤتمر الدولي حول الوكلاء الافتراضيين الأذكياء . في هذه المسابقة ، يُقترح إنشاء إيماءات لنموذج بشري ثلاثي الأبعاد يعتمد على الصوت. لقد تحدثت هذا العام في الحوار بموضوع مماثل ، وقمت بإلقاء نظرة عامة صغيرة على مناهج مشكلة التوليد التلقائي لتعبيرات الوجه وإيماءات الصوت. أحتاج إلى اكتساب الخبرة ، لأنني ما زلت بحاجة للدفاع عن رسالتي حول موضوع مماثل. أريد أن أحاول إنشاء وكيل افتراضي للقراءة ، مع تعابير الوجه والإيماءات وبالطبع الصوت. تسمح الأساليب الحالية لتجميع الكلام بتوليد كلام واقعي إلى حد ما من النص ، بينما تسمح نُهج توليد الإيماءات بتوليد إيماءات من الصوت. فلماذا لا تجمع بين هذه الأساليب.
بالمناسبة ، أين تدرس الآن؟
أنا طالب دراسات عليا في قسم اللغويات الحاسوبية في ABBYY في مدرسة Phystech للرياضيات التطبيقية والمعلوماتية في MIPT . سأدافع عن أطروحي خلال عامين.
ما المعارف والمهارات المكتسبة في الجامعة التي تساعدك الآن؟
من الغريب ، الرياضيات. على الرغم من أنني لا أدمج كل يوم ولا أضرب المصفوفات في رأسي ، فإن الرياضيات تعلم التفكير التحليلي والقدرة على اكتشاف أي شيء. بعد كل شيء ، يتضمن أي اختبار إثبات النظريات ، ومحاولة تعلمها غير مجدية ، ولكن من الممكن فهم وإثبات نفسك ، وتذكر فكرة فقط. كان لدينا أيضًا دورات برمجة جيدة ، حيث تعلمنا من مستوى منخفض لفهم كيفية عمل كل شيء ، وتحليل الخوارزميات المختلفة وهياكل البيانات. والآن لن تكون هناك مشكلة للتعامل مع إطار عمل جديد أو حتى لغة برمجة. نعم ، بالطبع ، كانت لدينا دورات في التعلم الآلي ، وفي البرمجة اللغوية العصبية على وجه الخصوص ، ولكن لا يزال ، يبدو لي أن المهارات الأساسية أكثر أهمية.
دانييل أناستاسييف ، الفائز بمسار تقييم الحوار GramEval-2020

ماذا تعمل؟
أقوم بتطوير المساعد الصوتي "أليس" ، أعمل في البحث عن مجموعة المعنى. نقوم بتحليل الطلبات التي تأتي إلى أليس. من الأمثلة القياسية لطلب البحث "ما حالة الطقس في موسكو غدًا؟" عليك أن تفهم أن هذا طلب يتعلق بالطقس ، وأن الطلب يسأل عن الموقع (موسكو) وهناك إشارة إلى الوقت (غدًا).
أخبرنا عن المشكلة التي قمت بحلها هذا العام في أحد مسارات تقييم الحوار.
كنت أقوم بمهمة قريبة جدًا مما يفعله ABBYY. كان من الضروري بناء نموذج لتحليل الجملة ، وإجراء تحليل مورفولوجي ونحوي ، وتحديد الليمونات. هذا مشابه جدًا لما يفعلونه في المدرسة. استغرق مني حوالي 5 أيام لبناء النموذج.

درس النموذج باللغة الروسية العادية ، ولكن ، كما ترى ، يعمل أيضًا باللغة التي كانت في المشكلة.
هل يبدو هذا مثل ما تفعله في العمل؟
على الاغلب لا. هنا تحتاج إلى فهم أن هذه المهمة في حد ذاتها لا تحمل الكثير من المعنى - يتم حلها كمهمة فرعية في إطار حل بعض مشاكل الأعمال المهمة. لذا ، على سبيل المثال ، في ABBYY ، حيث عملت مرة واحدة ، يعد التحليل الصرفي النحوي المرحلة الأولية في حل مشكلة استخراج المعلومات. في إطار مهامي الحالية ، لست بحاجة إلى مثل هذه التحليلات. ومع ذلك ، فإن الخبرة الإضافية للعمل مع نماذج لغوية سابقة التدريب مثل BERT تشعر بأنها مفيدة بالتأكيد لعملي. بشكل عام ، كان هذا هو الدافع الرئيسي للمشاركة - لم أكن أرغب في الفوز ، ولكن لممارسة واكتساب بعض المهارات المفيدة. بالإضافة إلى ذلك ، كانت شهادتي مرتبطة جزئيًا بموضوع المشكلة.
هل شاركت في تقييم الحوار من قبل؟
شارك في مسار MorphoRuEval-2017 في السنة الخامسة ، ثم حصل على المركز الأول. ثم كان من الضروري تحديد مورفولوجيا و lemmas فقط ، دون العلاقات النحوية.
هل من الواقعي تطبيق النموذج الخاص بك على المهام الأخرى الآن؟
نعم ، يمكن استخدام النموذج الخاص بي لمهام أخرى - لقد قمت بنشر كافة التعليمات البرمجية المصدر. أخطط لنشر الرمز باستخدام نموذج أخف وأسرع ولكن أقل دقة. من الناحية النظرية ، إذا أراد أي شخص ، يمكن استخدام النموذج الحالي. المشكلة هي أنها ستكون كبيرة جدًا وبطيئة بالنسبة لمعظم الناس. في المنافسة ، لا أحد يهتم بالسرعة ، من المثير للاهتمام تحقيق أعلى جودة ممكنة ، ولكن في التطبيق العملي ، كل شيء عادة ما يكون العكس. لذلك ، فإن الفائدة الرئيسية لهذه النماذج الكبيرة هي معرفة الجودة الأكثر قابلية للتحقيق من أجل فهم ما تضحي به.
لماذا تشارك في تقييم الحوار ومسابقات أخرى مماثلة؟
لا ترتبط الهاكاثون ومثل هذه المسابقات بشكل مباشر بعملي ، لكنها لا تزال تجربة مجزية. على سبيل المثال ، عندما شاركت في هاكاثون رحلة منظمة العفو الدولية في العام الماضي ، تعلمت بعض الأشياء التي استخدمتها بعد ذلك في عملي. كانت المهمة هي تعلم كيفية اجتياز الامتحان باللغة الروسية ، أي حل الاختبارات وكتابة مقال. من الواضح أن كل هذا لا علاقة له بالعمل. لكن القدرة على الخروج بسرعة وتدريب نموذج يحل بعض المشاكل مفيد جدًا. بالمناسبة ، فزت أنا وفريقي بالمركز الأول.
ما التعليم الذي حصلت عليه وماذا فعلت بعد الجامعة؟
تخرج من درجة البكالوريوس والماجستير في قسم اللسانيات الحاسوبية ABBYY في معهد موسكو للفيزياء والتكنولوجيا ، وتخرج في 2018. كما درس في مدرسة تحليل البيانات (SHAD). عندما حان الوقت لاختيار قسم أساسي في السنة الثانية ، ذهبت معظم مجموعتنا إلى أقسام ABBYY - اللغويات الحاسوبية أو التعرف على الصور ومعالجة النصوص. في برنامج البكالوريوس تعلمنا البرمجة بشكل جيد - كانت هناك دورات مفيدة للغاية. من السنة الرابعة عملت في ABBYY لمدة 2.5 سنة. أولاً ، في مجموعة المورفولوجيا ، كنت منخرطًا في مهام تتعلق بنماذج اللغة لتحسين التعرف على النص في ABBYY FineReader. لقد كتبت التعليمات البرمجية ، النماذج المدربة ، الآن أفعل نفس الشيء ، ولكن لمنتج مختلف تمامًا.
كيف تقضي وقت فراغك؟
انا احب قراءة الكتب. اعتمادًا على الموسم ، أحاول الركض أو التزلج. أنا مغرم بالتصوير أثناء السفر.
هل لديك خطط أو أهداف للسنوات الخمس القادمة مثلا؟
5 سنوات بعيدة جدا عن أفق التخطيط. ليس لدي حتى 5 سنوات من الخبرة في العمل. على مدى السنوات الخمس الماضية ، تغير الكثير ، والآن من الواضح أن هناك شعورًا مختلفًا عن الحياة. لا أستطيع أن أتخيل ما يمكن أن يتغير ، ولكن هناك أفكار للحصول على درجة الدكتوراه في الخارج.
ما النصيحة التي يمكنك تقديمها للمطورين الشباب الذين يشاركون في اللغويات الحاسوبية وهم في بداية رحلتهم؟
من الأفضل ممارسة ومحاولة والتنافس. يمكن مبتدئين تأخذ واحدة من العديد من الدورات: على سبيل المثال، من SHAD ، DeepPavlov، أو حتى بلدي الخاصة، وأنا مرة واحدة تدرس في ABBYY.
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .