
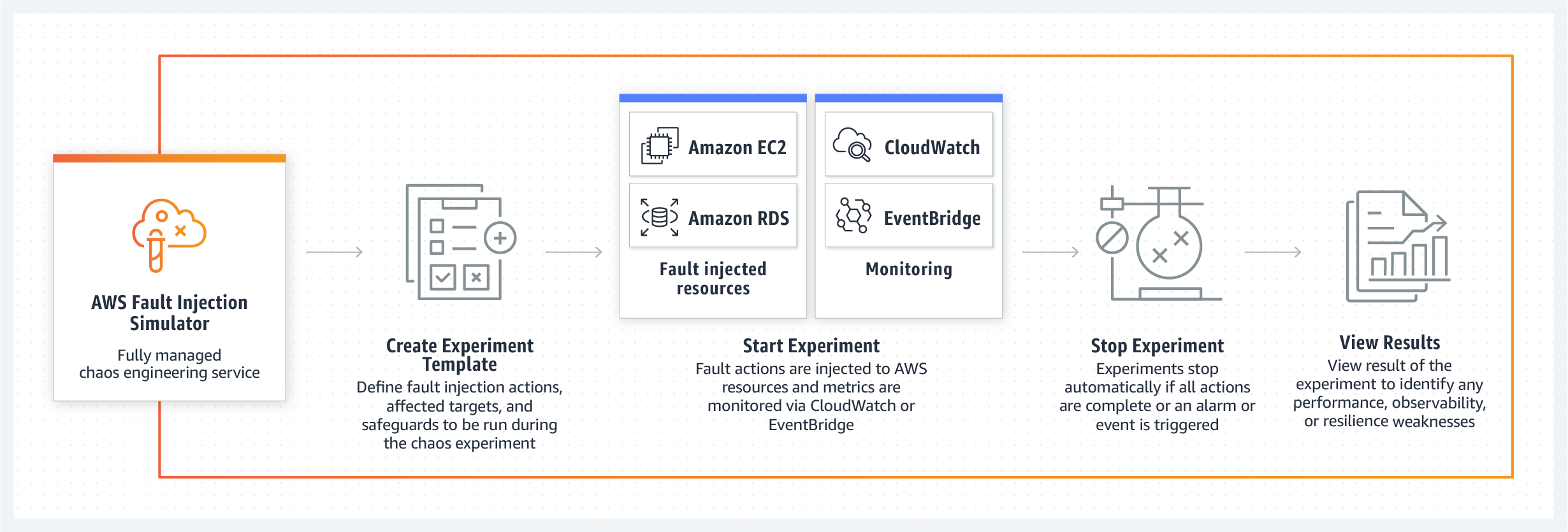
AWS Fault Injection Simulator (FIS)- أداة تتيح لك تنفيذ السيناريوهات المعروفة سابقًا لفشل النظام الداخلي ضمن خدمات AWS. لأي غرض؟ - حتى تتمكن الفرق من وضع سيناريوهات للتخلص منها وتقييم سلوك منتجها بشكل عام في ظل الظروف المقترحة. سيقدم النظام على الفور عدة قوالب مع سيناريوهات الفشل ، على سبيل المثال ، تباطؤ الخوادم أو فشلها أو خطأ في الوصول إلى قاعدة البيانات أو تعطلها. في الوقت نفسه ، ستضمن FIS أن التجربة لا تذهب بعيدًا وعندما يتم الوصول إلى معلمات معينة ، سيتم إيقاف الاختبار ، وسيعود النظام إلى طبيعته. الشعار الرئيسي للمنتج الجديد للعملاق السحابي هو "زيادة المرونة والأداء باستخدام تقنية الفوضى الخاضعة للتحكم." من المقرر إصدار نظام الاختبار الجديد في عام 2021.
تقدم AWS أيضًا اختبارًا وأنظمة افتراضية موزعة أقل اعتمادًا على مضيف واحد. خصوصية الفشل في نظام موزع هو أن المشكلة يمكن أن تكون دورية ولها هيكل أكثر تعقيدًا. ستسمح لك ميزة AWS الجديدة بالبحث عن نقاط الضعف ليس فقط في البنية التحتية للوحدات المتراصة ، ولكن أيضًا في الأنظمة والتطبيقات الموزعة.
دعونا نرى لماذا هذا مهم ورائع.
هندسة الفوضى هي عملية اختبار محاكاة يأتي فيها التأثير الرئيسي على النظام من الداخل ويؤثر على البنية التحتية للمشروع. يحاكي الفريق المواقف التي يواجه فيها جزء البنية التحتية من المشروع مشاكل فنية ومشاكل أخرى ، على سبيل المثال ، مع انخفاض نقطة أو منهجي في الأداء في الحالات. يمكن أن يشمل ذلك أيضًا أعطال الخادم ، وإخفاقات واجهة برمجة التطبيقات ، والكوابيس الأخرى للواجهة الخلفية التي قد يواجهها الفريق في أي وقت ، أو الأسوأ من ذلك ، في اليوم الذي يتم فيه إصدار الإصدار التالي.
لا يوجد تعريف واضح لهندسة الفوضى حتى الآن ، لذا إليك بعض الخيارات الأكثر شيوعًا ، وفي رأينا ، الخيارات الدقيقة. هندسة الفوضى هي: "نهج يتضمن تجربة نظام إنتاج للتأكد من قدرته على تحمل الاضطرابات المختلفة التي تحدث أثناء التشغيل" و "تجربة للتخفيف من آثار الفشل".
لماذا هناك حاجة على الإطلاق إلى AWS Fault Injection Simulator
يستشهد مطورو الأداة بالعديد من الأسباب التي تجعل FIS مفيدة للفرق عند اختبار وإعداد أنظمتهم.
يعد أداء النظام والمرونة والشفافية إحدى الرسائل الأساسية لفريق AWS FIS.
AWS Fault Injection Simulator , , «» , .
في الواقع ، فإن طرق الاختبار المعتادة هي ، أولاً وقبل كل شيء ، محاكاة الحمل الخارجي على النظام. على سبيل المثال ، محاكاة تأثير habra أو هجوم DDoS خارجي على نظام أو خدمة. في أغلب الأحيان ، يتم ربط جميع أنظمة المراقبة الرئيسية بدقة بهذه العقد ، بينما يقتصر تتبع سلوك البنية التحتية الداخلية ، في كثير من الأحيان ، فقط على تلقي البيانات بأسلوب "down / down" أو الحمل على وحدة المعالجة المركزية. في الوقت نفسه ، يرتبط الضرر الأكبر وأقوى حالات الفشل في السنوات الأخيرة على وجه التحديد بالفشل الداخلي أو أخطاء البنية التحتية. يكفي أن نتذكر انهيار CloudFlare العام الماضي ، عندما أجبر المطورون حرفياً نصف الإنترنت على "الاستلقاء" بأيديهم ، بسبب عدد من الإخفاقات والأخطاء.
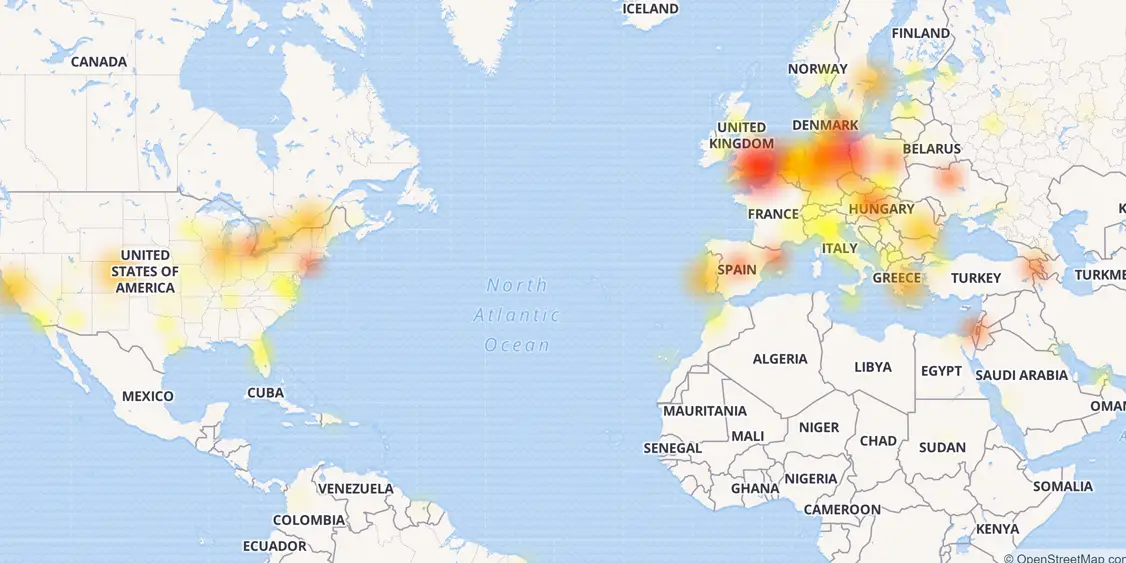
خريطة فشل CloudFlare
الأداة الجديدة قادرة على العمل على حد سواء القوالب الجاهزة لسيناريوهات فشل قاعدة البيانات ، API أو تدهور الأداء ، بالإضافة إلى إنشاء ظروف اختبار عشوائية عشوائية تحدث فيها المشاكل في تسلسل عشوائي على العقد المختلفة.
نقطة أخرى قوية في مجموعة أدوات AWS الجديدة هي إمكانية التحكم في الفوضى التي أحدثها الفريق في النظام. يؤكد المهندسون أنه بمساعدة لوحة التحكم الخاصة بهم ، يمكن للمطورين إيقاف سيناريو الفشل المتحكم فيه في أي وقت وإعادة النظام إلى حالة العمل الأصلية. يدعم Fault Injection Simulator Amazon CloudWatch وأدوات المراقبة الخارجية المتصلة عبر Amazon EventBridge ، بحيث يمكن للمطورين استخدام مقاييسهم لمراقبة تجارب الفوضى الخاضعة للرقابة. حسنًا ، وبالطبع ، بعد إيقاف الاختبار ، سيتلقى المسؤول تقريرًا كاملاً عن عُقد النظام وبأي تسلسل تأثر بالفشل ، والذي سيساعد في المستقبل على تطوير مجموعة من الإجراءات والإجراءات لتوطين المشكلات والقضاء عليها.
كيف نشأ أسياد الفوضى
من الواضح أن اختبار الضغط هذا للنظام هو الأكثر منطقية في فترة ما قبل الإصدار للتأكد من أن البنية التحتية الحالية على AWS ستصمد أمام التصحيح الجديد. ومع ذلك ، في الواقع ، تعود تقنية هندسة الفوضى إلى الممارسات القديمة ، التي كان مؤسسها أحد مديري Amazon في العقد الأول من القرن الحالي ، جيسي روبينز. أطلق على منصبه رسميًا اسم "Master of Disaster" ، والذي يمكن اعتباره خطأً في ترجمة مثيرة للشفقة على أنه "Lord of Disasters" ، وفي نسخة مجانية بدا موقفه مثل "Master Lomaster".
 كان روبينز ، رجل إطفاء الإنقاذ السابق ، هو من
نفذ GameDay في أمازون.... كان الهدف من مبادرة روبنز بسيطًا للغاية - لتزويد فرق الهندسة بفهم بديهي لكيفية التعامل مع كارثة ، تمامًا مثل هذا الشعور الذي يتم تدريبه في فرق الإطفاء. لهذا تم اختيار طريقة المحاكاة الشاملة للفوضى الشاملة: كل شيء ينهار من جميع الجوانب ، في وقت واحد أو بالتتابع ، وكل محاولة للتعامل مع الفشل تؤدي إلى مشاكل جديدة وجديدة.
كان روبينز ، رجل إطفاء الإنقاذ السابق ، هو من
نفذ GameDay في أمازون.... كان الهدف من مبادرة روبنز بسيطًا للغاية - لتزويد فرق الهندسة بفهم بديهي لكيفية التعامل مع كارثة ، تمامًا مثل هذا الشعور الذي يتم تدريبه في فرق الإطفاء. لهذا تم اختيار طريقة المحاكاة الشاملة للفوضى الشاملة: كل شيء ينهار من جميع الجوانب ، في وقت واحد أو بالتتابع ، وكل محاولة للتعامل مع الفشل تؤدي إلى مشاكل جديدة وجديدة.
عندما يواجه شخص غير مستعد أعمال شغب من العناصر ، فإنه في أغلب الأحيان يقع في ذهول أو ذعر. معظم المطورين والمهندسين ليسوا مستعدين نفسياً لموقف يجب أن يستغرق فيه حل مشكلة ما ثلاثة أيام ، ومستوى التوتر المحيط به هو ببساطة خارج النطاق.
يصف روبنز أهم نتيجة لـ GameDay بالتأثير النفسي لمثل هذه التمارين: فهي تطور القدرة على قبول حقيقة حدوث اضطرابات واسعة النطاق . إنه قبول حقيقة أن كل شيء يحترق وينهار ، يسميها مهمة للغاية بالنسبة للمهندس ، حتى يتمكن من جمع أفكاره والبدء في النهاية في "إطفاء الحريق". الشخص غير المدرب ، في أحسن الأحوال ، سيركض في دوائر ويصرخ "ضاع كل شيء".
بعد تنفيذ ممارسة GameDay ، اتضح أن مثل هذه التمارين تحدد تمامًا المشكلات المعمارية والاختناقات التي لا يتم الالتفات إليها أثناء الاختبار والتحقق الكلاسيكيين.
هناك اختلاف مهم آخر بين GameDay وتماريننا المعتادة "للتدريب والنظام" وهو أن قلة من الناس يعرفون السيناريو المحدد وما سيحدث بشكل عام. يتم تقديم المعلومات حول "الألعاب" القادمة بطريقة عامة وغامضة للغاية ، بحيث لا يتمكن المشاركون من الاستعداد بشكل كامل لهذا الحدث. من الناحية المثالية - الإعلان فقط عن تاريخ "يوم المباراة" التالي دون أي توضيحات على الإطلاق ، فقط حتى لا يخطئ المشاركون في اعتباره حادثًا حقيقيًا. بالطبع ، هذه المنهجية لا تتناسب مع شركة ضخمة ، على سبيل المثال ، لا يمكن تنفيذ GameDay في جميع أنحاء Yandex أو Microsoft في وقت واحد.
ونتيجة لذلك ، تمت ترقية الممارسة إلى GameDay المحلية وتم تقديمها في جميع شركات تكنولوجيا المعلومات الكبيرة الحالية ، على سبيل المثال ، في Google و Flickr والعديد من الشركات الأخرى. لديها درجة الماجستير في الكوارث الخاصة بها (حسناً ، أو Master-Lommasters ، كما تريد) ، الذين ينظمون إخفاقات التدريب ثم يحللون النتائج التي تم الحصول عليها في مشاريع محددة.
تكمن الصعوبة الرئيسية في تنفيذ هذه الممارسة في كل مكان في جانبين: كيفية تنظيمها وكيفية جمع البيانات حتى لا تذهب GameDay عبثًا. لهذا السبب ، في الشركات الصغيرة ، لم يتم استخدام هذه التقنية على نطاق واسع حتى وقت قريب (إذا تم استخدامها على الإطلاق). بدلاً من GameDay ومحاكاة الكوارث ، ركزت الشركة بشكل أكبر على أنواع مختلفة من الاختبارات و CI / CD ومنهجيات أخرى للتطوير المنظم والمتسق. أي ما يمنع حدوث كارثة في حد ذاتها.
ستتيح لك مجموعة أدوات AWS الجديدة معالجة الجانب الآخر من الاضطراب: فبدلاً من المنع ، وهو أمر مهم بلا شك ، ستتيح FIS للفرق الهندسية من جميع الأحجام التدريب الفعال في حل اضطرابات البنية التحتية العالمية. بعد كل شيء ، الشيء الرئيسي الذي يلاحظه روبنز هو أن الكوارث تحدث على أي حال: لا يمكن تجنبها.