- مقاله بحثيه
- Pytorch : YOLOv4-CSP ، YOLOv4-P5 ، YOLOv4-P6 ، YOLOv4-P7 ( المستودع الرئيسي - استخدم لإعادة إنتاج النتائج)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- داركنت : YOLOv4-صغيرة، YOLOv4-CSP، YOLOv4x-مش
- هيكل YOLOv4-CSP
Scaled YOLO v4 هي الشبكة العصبية الأكثر دقة ( 55.8٪ AP ) في مجموعة بيانات Microsoft COCO لأي شبكة عصبية منشورة حتى الآن. وهو أيضًا الأفضل من حيث نسبة السرعة إلى الدقة في النطاق الكامل للدقة والسرعة من 15 إطارًا في الثانية إلى 1774 إطارًا في الثانية . في الوقت الحالي هي الشبكة العصبية Top1 لاكتشاف الكائنات.
يتفوق YOLO v4 المتدرج على الشبكات العصبية من حيث الدقة:
- Google EfficientDet D7x / DetectoRS أو SpineNet-190 (مدرب ذاتيًا على بيانات إضافية)
- Amazon Cascade-RCNN ResNest200
- مايكروسوفت ريبوينتس v2
- فيسبوك RetinaNet SpineNet-190
نظهر أن نهج YOLO والشبكة عبر المراحل الجزئية (CSP) هي الأفضل من حيث الدقة المطلقة ونسبة الدقة إلى السرعة.
رسم بياني للدقة (المحور الرأسي) والكمون (المحور الأفقي) على GPU Tesla V100 (Volta) مع الدفعة = 1 دون استخدام TensorRT:
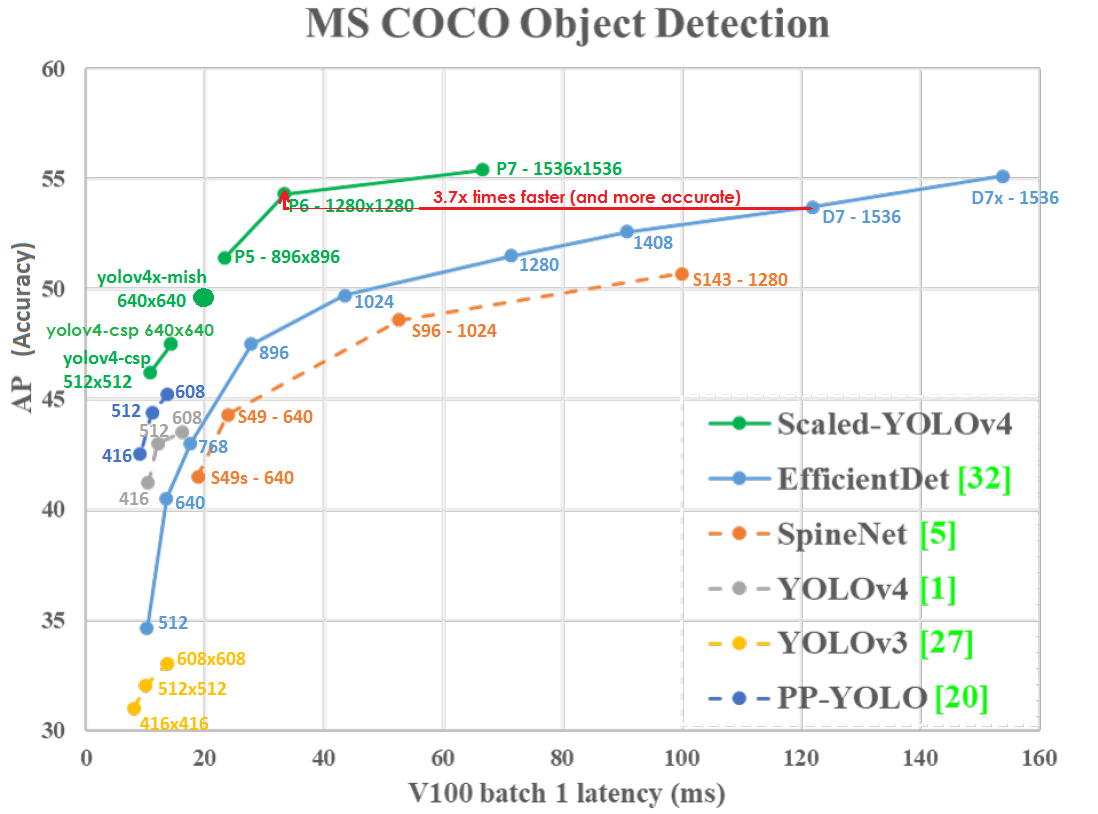
حتى مع دقة الشبكة المنخفضة ، فإن Scaled-YOLOv4-P6 (1280x1280) 30 إطارًا في الثانية أكثر دقة وأسرع 3.7 مرة من EfficientDetD7 (1536 × 1536) 8.2 إطارًا في الثانية. أولئك. يستفيد YOLOv4 من دقة الشبكة بشكل أفضل.
يقع Scaled YOLO v4 على منحنى Pareto الأمثل - بغض النظر عن الشبكة العصبية الأخرى التي تستخدمها ، هناك دائمًا شبكة YOLOv4 هذه ، والتي تكون إما أكثر دقة بنفس السرعة أو أسرع بنفس الدقة ، أي YOLOv4 هو الأفضل من حيث السرعة والدقة.
يعد YOLOv4 المتدرج أكثر دقة وأسرع من الشبكات العصبية:
- Google EfficientDet D0-D7x
- جوجل SpineNet S49s - S143
- مجداف بايدو PP YOLO
- وغيرها الكثير
Scaled YOLO v4 عبارة عن سلسلة من الشبكات العصبية المبنية من شبكة YOLOv4 المحسّنة والمحددة. تم تدريب شبكتنا العصبية من الصفر دون استخدام أوزان مدربة مسبقًا (Imagenet أو أي أوزان أخرى).
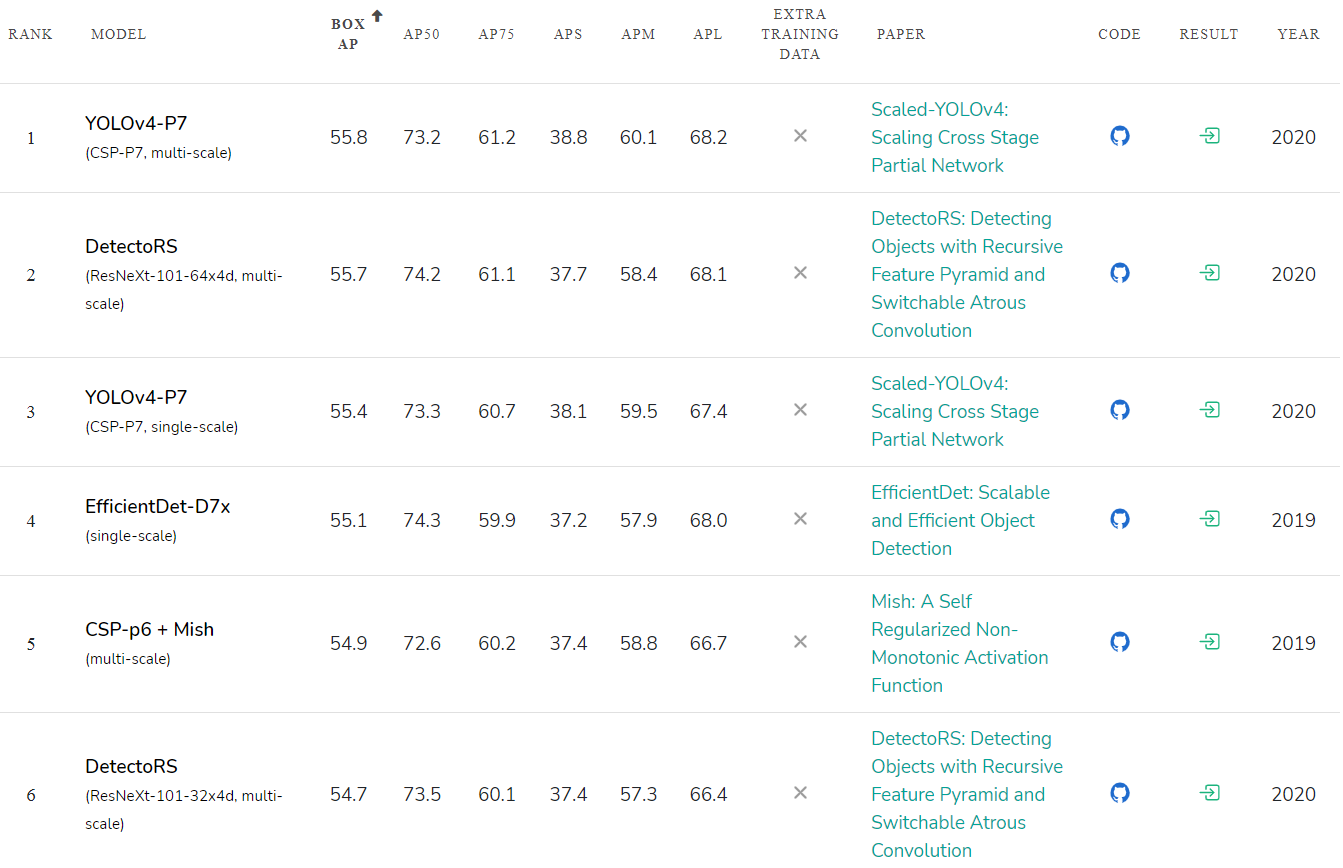
تصنيف الدقة للشبكات العصبية المنشورة: paperwithcode.com/sota/object-detection-on-coco :
تصل سرعة الشبكة العصبية الصغيرة YOLOv4 إلى 1774 إطارًا في الثانية على GPU RTX 2080Ti للألعاب باستخدام TensorRT + tkDNN (الدفعة = 4 ، FP16): جيثب.
يمكن تشغيل com / ceccocats / tkDNN YOLOv4-tiny في الوقت الفعلي بسرعة 39 إطارًا في الثانية / 25 مللي ثانية كمون على JetsonNano (416x416 ، fp16 ، الدفعة = 1) tkDNN / TensorRT:

يستخدم Scaled YOLOv4 موارد أجهزة الكمبيوتر المتوازية مثل GPUs و NPUs بشكل أكثر كفاءة. على سبيل المثال، GPU V100 (فولتا) والأداء: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
إذا كنا اختبار كلا الطرازين على GPU V100 مع الدفعة = 1 ، مع المعلمات --hparams = Mixed_precision = true وبدون - tensorrt = FP32 ، ثم:
- YOLOv4-CSP (640x640) - 47.5٪ AP - 70 FPS - 120 BFlops (60 FMA)
استنادًا إلى BFlops ، يجب أن يكون 933 إطارًا في الثانية = (112000/120) ، ولكن في الواقع نحصل على 70 إطارًا في الثانية ، أي تستخدم 7.5٪ GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
أولئك. كفاءة عمليات الحوسبة على الأجهزة ذات الحوسبة المتوازية الضخمة مثل وحدات معالجة الرسومات المستخدمة في YOLOv4-CSP (7.5 / 1.6) = 4.7x أفضل من كفاءة العمليات المستخدمة في EfficientDetD3.
عادة ، يتم تشغيل الشبكات العصبية على وحدة المعالجة المركزية فقط في مهام البحث لتسهيل تصحيح الأخطاء ، وخاصية BFlops حاليًا ذات أهمية أكاديمية فقط. في المهام الواقعية ، تعد السرعة والدقة الواقعية أمرًا مهمًا ، وليس الأداء على الورق. السرعة الحقيقية لـ YOLOv4-P6 هي 3.7x أسرع من EfficientDetD7 على GPU V100. لذلك ، يتم دائمًا استخدام الأجهزة ذات التوازي الهائل GPU / NPU / TPU / DSP مع السرعة المثلى والسعر وتبديد الحرارة:
- وحدة معالجة الرسومات المدمجة (Jetson Nano / Nx)
- Mobile-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-motors TPU 144 TOPS-8bit)
- وحدة معالجة الرسومات السحابية (nVidia A100 / V100 / TitanV)
- Cloud NPU (Google-TPU ، Huawei Ascend ، Intel Habana ، Qualcomm AI 100 ، ...)
أيضًا عند استخدام الشبكات العصبية على الويب - عادةً ما يتم استخدام GPU من خلال مكتبات WebGL و WebAssembly و WebGPU ، في هذه الحالة - يمكن أن يكون حجم النموذج مهمًا: github.com/tensorflow/tfjs#about-this-repo
استخدام الأجهزة والخوارزميات ذات الضعف التوازي هو طريق مسدود للتنمية ، لأن من المستحيل تقليل حجم الطباعة الحجرية الأصغر من حجم ذرة السيليكون لزيادة تردد المعالج:
- أفضل حجم حالي لتصنيع جهاز أشباه الموصلات هو 5 نانومتر.
- حجم الشبكة البلورية للسيليكون 0.5 نانومتر.
- نصف القطر الذري للسيليكون هو 0.1 نانومتر.
الحل هو أجهزة الكمبيوتر ذات التوازي الهائل: على بلورة واحدة أو على عدة بلورات متصلة بواسطة مداخل. لذلك ، من الضروري إنشاء شبكات عصبية تستخدم بكفاءة آلات الحوسبة المتوازية على نطاق واسع مثل وحدات معالجة الرسومات ووحدات المعالجة العصبية.
تحسينات في Scaled YOLOv4 على YOLOv4:
- استخدمت YOLOv4 المتدرجة تقنيات تحجيم الشبكة المثلى للحصول على YOLOv4-CSP -> P5 -> P6 -> شبكات P7
- بنية شبكة محسّنة: تم تحسين العمود الفقري ، ويستخدم Neck (PAN) اتصالات جزئية متقاطعة (CSP) وتنشيط Mish
- يتم استخدام المتوسط المتحرك الأسي (EMA) أثناء التدريب - وهذه حالة خاصة من SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- لكل دقة للشبكة ، يتم تدريب شبكة عصبية منفصلة (في YOLOv4 ، تم تدريب شبكة عصبية واحدة فقط لجميع القرارات)
- العوامل الطبيعية المحسنة في طبقات [yolo]
- عمليات التنشيط المتغيرة للعرض والارتفاع ، مما يسمح بتدريب الشبكة بشكل أسرع
- استخدم المعلمة [net] letter_box = 1 (تحافظ على نسبة العرض إلى الارتفاع لصورة الإدخال) للشبكات عالية الدقة (للجميع باستثناء yolov4-tiny.cfg)
بنية الشبكة العصبية Scaled-YOLOv4 (أمثلة على ثلاث شبكات: P5 و P6 و P7):

اتصال CSP فعال للغاية وبسيط ويمكن تطبيقه على أي شبكات عصبية. خلاصة القول هي أن
- يسير نصف إشارة الخرج على طول المسار الرئيسي (مما يؤدي إلى توليد المزيد من المعلومات الدلالية مع مجال استقبال كبير)
- والنصف الآخر من الإشارة يتبع منعطفًا (الاحتفاظ بالمزيد من المعلومات المكانية مع مجال تقبلي صغير)
أبسط مثال على اتصال CSP (على اليسار عبارة عن شبكة عادية ، وعلى اليمين توجد شبكة CSP):

مثال على اتصال CSP في YOLOv4-CSP / P5 / P6 / P7
(يوجد على اليسار شبكة عادية ، وعلى اليمين توجد شبكة CSP):

في YOLOv4 صغير ، يوجد اتصالان CSP :

يستخدم YOLOv4 في مختلف المجالات والمهام:
- الحكومة التايوانية: مراقبة حركة المرور www.taiwannews.com.tw/en/news/3957400 and youtu.be/IiU6wFmfVnk
- أمازون: مكافحة Covid19 المسافة عبر مساعد github.com/amzn/distance-assistant والأمازون Neurochip / أمازون EC2 الحالات Inf1: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- الكشف عن الكائن القائم على الخلايا العصبية المترجمة yolov4-model-on-aws-inferentia
- مختبر BMW للابتكار: github.com/BMW-InnovationLab
وفي مهام أخرى كثيرة….
هناك تطبيقات في أطر مختلفة:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o نقطة تثبيت yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- يمكن عرض بنية الشبكة باستخدام الأداة المساعدة Netron - Visualizer للشبكات العصبية: github.com/lutzroeder/netron
كيفية تجميع وتشغيل Cloud Object Detection مجانًا :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- فيديو: www.youtube.com/watch؟v=mKAEGSxwOAY
كيفية تجميع وتشغيل التدريب في السحابة مجانًا :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg؟usp=sharing
- فيديو: youtu.be/mmj3nxGT2YQ
أيضًا ، يمكن استخدام نهج YOLOv4 في مهام أخرى ، على سبيل المثال ، عند اكتشاف الكائنات ثلاثية الأبعاد:
- الكود - مجمع YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- الكود - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
