اللحن المهووس (ديدان الأذن الإنجليزية) - ظاهرة معروفة ومزعجة في بعض الأحيان. بمجرد أن يعلق أحدهم في الرأس ، قد يكون التخلص منه صعبًا للغاية. أظهرت الأبحاث أن ما يسمى بالتفاعل مع التركيبة الأصلية ، سواء الاستماع إليها أو الغناء ، يساعد على إبعاد اللحن المتطفّل. ولكن ماذا لو كنت لا تتذكر اسم الأغنية ، ولكن لا يمكنك سوى ترنيم اللحن؟
عند استخدام الأساليب الحالية لمقارنة اللحن المغني بتسجيل الاستوديو الأصلي متعدد الأصوات ، ينشأ عدد من الصعوبات. يمكن أن يكون صوت التسجيل المباشر أو الاستوديو مع كلمات الأغاني والأغاني الداعمة والآلات مختلفًا تمامًا عما يدندنه الشخص. بالإضافة إلى ذلك ، قد لا تحتوي نسختنا على نفس درجة الصوت أو المفتاح أو الإيقاع أو الإيقاع عن طريق الخطأ أو التصميم. هذا هو السبب في أن العديد من الأساليب الحالية للاستعلام عن طريق نظام همهمة تعين اللحن المغني إلى قاعدة بيانات للألحان الموجودة مسبقًا أو الإصدارات الأخرى المغنية من تلك الأغنية ، بدلاً من تحديدها مباشرة. ومع ذلك ، غالبًا ما يعتمد هذا النوع من النهج على قاعدة بيانات محدودة تتطلب التحديث اليدوي. تم
إطلاق Hum to Search في أكتوبرهو نظام بحث Google جديد يتعلم آليًا بالكامل ويسمح لأي شخص بالعثور على أغنية من خلال غنائها أو التعجيل بها. على عكس الأساليب الحالية ، يُنشئ هذا الأسلوب تضمينًا من المخطط الطيفي للأغنية ، متجاوزًا التمثيل الوسيط. يسمح هذا للنموذج بمقارنة اللحن الخاص بنا مباشرةً بالتسجيل الأصلي (متعدد الألحان) دون الحاجة إلى الحصول على لحن مختلف أو إصدار MIDI لكل مسار. كما أنه لا يحتاج إلى استخدام منطق معقد مصنوع يدويًا لاستخراج اللحن. يعمل هذا النهج على تبسيط قاعدة البيانات الخاصة بـ Hum to Search إلى حد كبير ، مما يسمح لك باستمرار إضافة حفلات الزفاف للمقاطع الصوتية الأصلية من جميع أنحاء العالم ، حتى أحدث الإصدارات ، إليها.
كيف تعمل
تقوم العديد من أنظمة التعرف على الموسيقى الحالية بتحويلها إلى مخطط طيفي قبل معالجة عينة صوتية للعثور على تطابق أكثر صحة. ومع ذلك ، هناك مشكلة واحدة في التعرف على اللحن المغني - غالبًا ما يحتوي على معلومات قليلة نسبيًا ، كما في هذا المثال لأغنية "Bella Ciao" . يمكن تصور الفرق بين إصدار سونغ ونفس المقطع من تسجيل الاستوديو المقابل باستخدام مخططات الطيف الموضحة أدناه:

تصور مقتطف الغناء وتسجيل الاستوديو الخاص به
بالنظر إلى الصورة الموجودة على اليسار ، يجب أن يجد النموذج الصوت الذي يطابق الصورة الموجودة على اليمين في مجموعة تضم أكثر من 50 مليون صورة مماثلة (تقابل مقاطع تسجيلات استوديو لأغاني أخرى). للقيام بذلك ، يجب أن يتعلم النموذج التركيز على اللحن السائد وتجاهل الأصوات الداعمة والأدوات والجرس الصوتي ، فضلاً عن الاختلافات بسبب ضوضاء الخلفية أو الصدى. لتحديد اللحن السائد بالعين الذي يمكن استخدامه للمقارنة بين الطيفين ، يمكنك البحث عن أوجه التشابه في الخطوط الموجودة أسفل الصور أعلاه.
أظهرت المحاولات السابقة لتطبيق التعرف على الموسيقى ، وخاصة الموسيقى في المقاهي أو النوادي ، كيف يمكن تطبيق التعلم الآلي على هذه المشكلة. Now Playing ، الذي تم إصداره في عام 2017 لهواتف Pixel ، يستخدم شبكة عصبية عميقة مدمجة للتعرف على الأغاني دون الحاجة إلى اتصال بالخادم ، ويستخدم Sound Search ، الذي طور التكنولوجيا فيما بعد ، التعرف على الخادم للبحث بسرعة ودقة في أكثر من 100 مليون أغنية. احتجنا أيضًا إلى تطبيق ما تعلمناه في هذه الإصدارات للتعرف على الموسيقى من مكتبة كبيرة مماثلة ، ولكن بالفعل من المقاطع المغنية.
إعداد التعلم الآلي
كانت الخطوة الأولى في تطوير Hum to Search هي تغيير نماذج التعرف على الموسيقى المستخدمة في Now Playing و Sound Search للعمل مع تسجيلات الألحان. في الأساس ، تعمل العديد من محركات البحث المماثلة (مثل التعرف على الصور) بطريقة مماثلة. في عملية التدريب ، تتلقى الشبكة العصبية زوجًا (اللحن والتسجيل الأصلي) كمدخلات وتقوم بإنشاء حفلات الزفاف الخاصة بهم ، والتي سيتم استخدامها لاحقًا لتتناسب مع اللحن المغني.

إعداد تدريب الشبكة العصبية
لضمان التعرف على ما نغنيه ، يجب وضع حفلات الزفاف للأزواج الصوتية التي لها نفس اللحن بجوار بعضها البعض ، حتى لو كان لديهم أصوات مرافقة وغنائية مختلفة. يجب أن تكون أزواج الصوت التي تحتوي على ألحان مختلفة متباعدة. في عملية التدريب ، تتلقى الشبكة مثل هذه الأزواج الصوتية حتى تتعلم كيفية إنشاء حفلات الزفاف بهذه الخاصية.
في النهاية ، سيتمكن النموذج المدرّب من إنشاء حفلات زفاف لألحاننا ، على غرار حفلات الزفاف في التسجيلات الرئيسية للأغاني. في هذه الحالة ، فإن العثور على الأغنية المناسبة هو مجرد البحث في قاعدة البيانات عن حفلات الزفاف المماثلة المحسوبة على أساس التسجيلات الصوتية للموسيقى الشعبية.
بيانات التدريب
منذ تدريب النموذج الذي تطلب أزواجًا من الأغاني (المسجلة والمغنية) ، كان التحدي الأول هو الحصول على بيانات كافية. تتألف مجموعة البيانات الأصلية الخاصة بنا في الغالب من مقتطفات من الأغاني (احتوى عدد قليل جدًا منها على همهمة من فكرة بدون كلمات). لجعل النموذج أكثر موثوقية ، أثناء التدريب ، طبقنا التعزيز على هذه الأجزاء: قمنا بتغيير درجة الصوت والإيقاع بترتيب عشوائي. عمل النموذج الناتج جيدًا بما يكفي للأمثلة التي تم فيها غناء الأغنية بدلاً من همهمة أو صفير.
لتحسين أداء النموذج على الألحان الخالية من الكلمات ، قمنا بإنشاء بيانات تدريب إضافية باستخدام "همهمة" اصطناعية من المجموعة الحالية من البيانات الصوتية. لهذا استخدمنا SPICE ، نموذج استخراج الملعب الذي طوره فريقنا الموسع كجزء من مشروعفريدي متر . يستخرج سبايس قيم درجة الصوت من صوت معين ، والذي نستخدمه بعد ذلك لتوليد نغمة تتكون من نغمات صوتية منفصلة. لقد غيرت النسخة الأولى من هذا النظام المقطع الأصلي هنا في هذا .
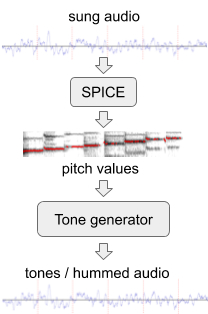
توليد "همسات" من مقطع صوتي مغني.
لاحقًا قمنا بتحسين الطريقة من خلال استبدال مولد نغمة بسيط بشبكة عصبية تولد صوتًا يشبه همهمة حقيقية لعنصر بدون كلمات. على سبيل المثال ، يمكن تحويل المقتطف أعلاه إلى طنين أو صافرة .
في الخطوة الأخيرة ، قمنا بمقارنة بيانات التدريب عن طريق خلط مقتطفات الصوت ومطابقتها. عندما وجدنا ، على سبيل المثال ، مقتطفات متشابهة من فنانين مختلفين ، قمنا بمواءمتها مع نماذجنا الأولية ، وبالتالي زودنا النموذج بزوج إضافي من المقتطفات الصوتية من نفس اللحن.
تحسين النموذج
في تدريب نموذج Hum to Search ، بدأنا بخسارة ثلاثية ، والتي أثبتت أنها ممتازة في مجموعة متنوعة من مهام التصنيف مثل تصنيف الصور والموسيقى المسجلة . إذا تم إعطاء زوج من الصوت يتطابق مع نفس اللحن (النقطتان R و P في مساحة التضمين الموضحة أدناه) ، فإن وظيفة الخسارة الثلاثية تتجاهل أجزاء معينة من بيانات التدريب المشتقة من اللحن الآخر. يساعد هذا في تحسين سلوك التعلم عندما يجد النموذج لحنًا آخر بسيطًا جدًا وبعيدًا بالفعل عن R و P (انظر النقطة E). وأيضًا عندما يكون الأمر معقدًا للغاية بالنسبة للمرحلة الحالية من تدريب النموذج ويتبين أنه قريب جدًا من R (انظر النقطة H).

أمثلة على مقاطع الصوت المقدمة كنقاط في الفضاء
وجدنا أنه يمكننا تحسين دقة النموذج من خلال مراعاة بيانات التدريب الإضافية (النقطتان H و E) ، أي من خلال صياغة المفهوم العام للثقة في النموذج في سلسلة من الأمثلة: ما مدى ثقة النموذج في أن جميع البيانات ، التي عملت معها يمكن تصنيفها بشكل صحيح؟ أم أنها صادفت أمثلة لا تتوافق مع فهمها الحالي؟ بناءً على ذلك ، أضفنا وظيفة خسارة تقرب ثقة النموذج من 100٪ في جميع مناطق مساحة التضمين ، مما يؤدي إلى تحسين جودة الذاكرة ودقة نموذجنا .
سمحت التغييرات المذكورة أعلاه ، وتحديداً الجمع بين البيانات المعززة والتدريب ، لنموذج الشبكة العصبية المستخدم في بحث Google بالتعرف على الألحان المغنية. يحقق النظام الحالي مستوى عاليًا من الدقة استنادًا إلى قاعدة بيانات تزيد عن نصف مليون أغنية نقوم بتحديثها باستمرار. هذه المجموعة من المسارات لديها مجال للنمو ، مع المزيد من الموسيقى القادمة من جميع أنحاء العالم.
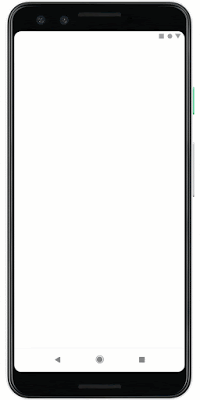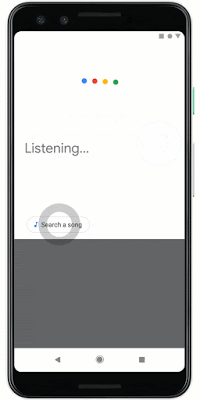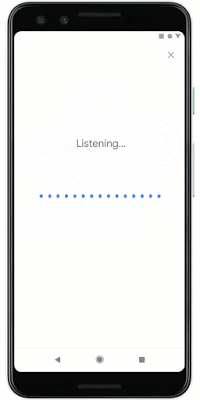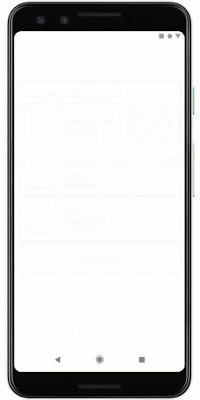
لاختبار هذه الميزة ، افتح أحدث إصدار من تطبيق Google ، وانقر على أيقونة الميكروفون وقل "ما هذه الأغنية" أو انقر على "البحث عن أغنية". الآن يمكنك همهمة أو صافرة لحن! نأمل أن يساعدك Hum to Search في التخلص من الألحان المتطفلة أو مجرد العثور على مقطع صوتي والاستماع إليه دون إدخال اسمه.