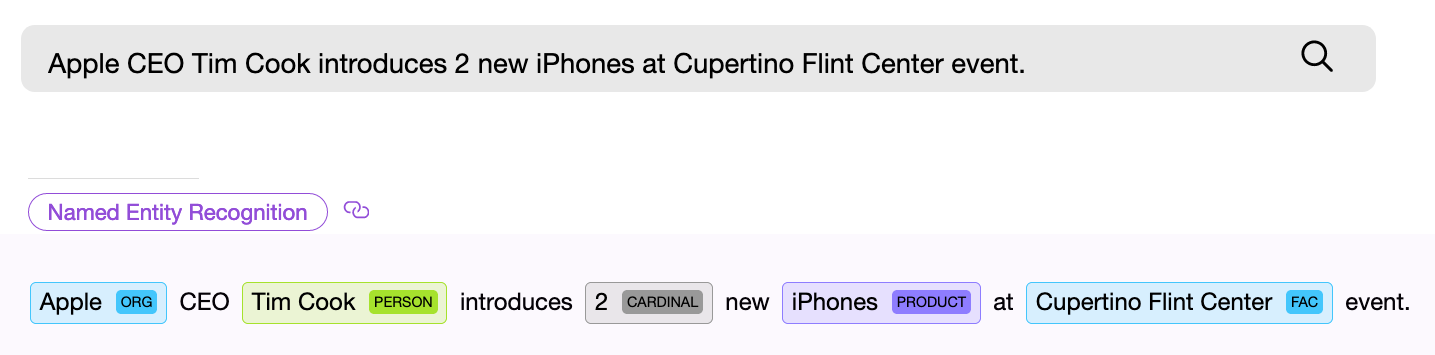
يجب أن يجد مكون NER (التعرف على الكيانات المسماة) ، أي مكون برنامج للبحث عن كيانات مسماة ، كائنًا في النص ، وإذا أمكن ، احصل على بعض المعلومات منه. مثال - "أعطني اثنين وعشرين قناعًا." يجد مكون NER العددي العبارة "اثنان وعشرون" في النص المحدد ويستخرج من هذه الكلمات القيمة الرقمية المُطابقة - " 22 " ، والآن يمكن استخدام هذه القيمة.
يمكن أن تستند مكونات NER على الشبكات العصبية أو تعمل على أساس القواعد وأي نماذج داخلية. غالبًا ما تستخدم مكونات NER العامة الطريقة الثانية.
دعنا نفكر في العديد من الحلول الجاهزة للعثور على الكيانات القياسية في النص. في هذا المنشور ، سنركز على المكتبات المجانية أو المجانية ذات القيود ، ونتحدث أيضًا عن ما تم إنجازه في مشروع Apache NlpCraft في إطار هذه المشكلة. القائمة أدناه ليست نظرة عامة مفصلة ومفصلة ، والتي يوجد بالفعل عدد كافٍ منها على الشبكة ، ولكنها بالأحرى وصف موجز للميزات الرئيسية وإيجابيات وسلبيات استخدام هذه المكتبات.
موفرو مكونات NER
اباتشي OpenNlp
يوفر Apache OpenNlp مجموعة قياسية إلى حد ما من مكونات NER للغة الإنجليزية ، والتي تتعامل مع التواريخ والأوقات والجغرافيا والمؤسسات والنسب المئوية والأشخاص. مجموعة صغيرة متاحة أيضًا للغات أخرى (الإسبانية ، الهولندية).
التسليم:
مكتبة جافا. لا يشحن Apache OpenNlp النماذج مع المشروع الرئيسي. هم متاحون للتنزيل بشكل منفصل.
الايجابيات:
رخصة اباتشي. تم اختبار النماذج في العديد من التطبيقات.
سلبيات:
على ما يبدو ، تمت إزالة النماذج من المشروع الرئيسي لسبب ما. لدى المرء انطباع بأن العمل عليها إما توقف أو أنه يسير بوتيرة محبطة ، حيث لم يتم رؤية النماذج الجديدة أو التغييرات في النماذج الحالية لبعض الوقت. نظرًا لأنه يمكن لمستخدمي Apache OpenNlp إنشاء وتدريب النماذج الخاصة بهم ، فمن الممكن أن تُترك هذه المهمة تمامًا لهم.
ستانفورد Nlp
يعتبر Stanford NLP منتجًا حيويًا ومتطورًا باستمرار بجودة ممتازة ومجموعة واسعة من الاحتمالات. بالنسبة للغة الإنجليزية ، تمت إضافة دعم للتعرف على الكيانات التالية: شخص ، موقع ، منظمة ، متفرقات ، نقود ، رقم ، ترتيبي ، نسبة مئوية ، تاريخ ، وقت ، مدة ، مجموعة. بالإضافة إلى ذلك ، يسمح لك مكون Regex NER المدمج بالعثور بدرجة عالية من الدقة على كيانات مثل: البريد الإلكتروني ، عنوان URL ، المدينة ، state_or_province ، البلد ، الجنسية ، الدين ، المسمى الوظيفي ، الأيديولوجيا ، الإجرام ، السبب_من_الموت ، التعامل. مزيد من التفاصيل على الرابط . تم الإعلان عن دعم NER المحدود للألمانية والإسبانية والصينية. يمكن اختبار جودة التعرف باستخدام العرض التوضيحي عبر الإنترنت .
يتبرع:
مكتبة جافا. يمكن تنزيل النماذج من المخضرمين جنبًا إلى جنب مع المشروع.
لم أجد في أي مكان قائمة ووصف مفصل لمكونات NER للغات غير الإنجليزية. الروابط 1 ، 2 - تم تقديم أمثلة على عملية تدريب مكونات NER الأصلية للغات مختلفة. ببساطة ، يتم الإعلان عن القدرة على استخدام لغات أخرى ، ولكن عليك إجراء تعديلات.
الإيجابيات:
الشعور من العمل مع المشروع ككل ومع النماذج الجاهزة هو الأكثر إيجابية ، حيث يستمر المشروع ويتطور ، وجودة الاعتراف جيدة ("جيد" مفهوم مشروط ، وهناك مقاييس تميز جودة التعرف على مكونات NER ، ولكن هذه المشكلة خارج نطاق المقالة).
سلبيات:
بصرف النظر عن بعض الفوضى مع المستندات ، فهي صغيرة. لمن هو مهم ، انتبه إلى الترخيص. تختلف رخصة جنو العمومية عن أباتشي ، لذلك ، على سبيل المثال ، لا يمكنك إضافة منتج بهذا الترخيص إلى المنتجات المرخصة بموجب أباتشي ، إلخ.
واجهة برمجة تطبيقات لغة Google
تدعم واجهة برمجة تطبيقات Google للغة الإنجليزية قائمة الكيانات التالية: شخص ، موقع ، مؤسسة ، حدث ، work_of_art ، Consumer_good ، أخرى ، رقم الهاتف ، العنوان ، التاريخ ، الرقم ، السعر.
النظام الأساسي:
REST API ، SaaS. مكتبات العملاء الجاهزة عبر REST متاحة (Java ، C # ، Python ، Go ، إلخ).
الإيجابيات:
يتم توفير مجموعة كبيرة من مكونات NER والتطوير والجودة من قبل عملاق الإنترنت المعروف.
السلبيات:
بدءًا من أحجام معينة ، يتم دفع الاستخدام .
سباسي
توفر هذه المكتبة واحدة من أكبر مجموعات الكيانات المدعومة للتعرف عليها ، راجع الارتباط للحصول على قائمة بالكيانات المدعومة .
المنصة:
بايثون.
للأسف ، عدم وجود خبرة شخصية في الاستخدام الصناعي لا يسمح لي بإضافة وصف حقيقي لإيجابيات وسلبيات هذه المكتبة. وبالإضافة إلى ذلك، تم بالفعل لمحة مفصلة عن حلول بيثون NLP نشرت على الهبر.
تتيح لك جميع المكتبات المذكورة أعلاه تدريب النماذج الخاصة بك. أيضًا ، جميعهم (باستثناء Apache OpenNlp) يسمحون باستخراج القيم الطبيعية من الكيانات الموجودة ، أي الحصول على الرقم "173" من الكيان الرقمي "مائة وثلاثة وسبعون" الموجود في الاستعلام.
كما نرى ، هناك العديد من الخيارات لحل مشكلة العثور على كيانات محددة ، واتجاه تطورها واضح - توسيع قائمة اللغات المدعومة ومجموعة من الكيانات المعترف بها ، وتحسين جودة التعرف.
إليكم ما جلبه مشروع Apache NlpCraft لهذه المنطقة الراسخة بالفعل.
الميزات الإضافية التي تقدمها NlpCraft
- مكونات NER الأصلية للكيانات الجديدة ، حلول محسّنة لبعض الكيانات الحالية.
- تكامل مكونات NER لجميع المكتبات المذكورة أعلاه في إطار استخدام المنتج.
- دعم "الكيانات المركبة" ، مما يمنح المستخدمين طريقة سهلة لإنشاء مكونات مخصصة جديدة من المكونات الحالية.
الآن حول كل هذا بمزيد من التفصيل.
مكونات NER المسجلة الملكية
مكونات NER الأصلية لـ Apache NlpCraft هي مكونات للتعرف على التواريخ والأرقام والجغرافيا والإحداثيات والفرز ومطابقة الكيانات المختلفة. بعضها فريد ، والبعض الآخر مجرد تنفيذ محسن للحلول الحالية (تمت زيادة دقة التعرف ، تمت إضافة حقول قيمة إضافية ، إلخ).
تكامل الحلول القائمة
تم دمج جميع الحلول المذكورة أعلاه للاستخدام مع Apache NlpCraft.
عند العمل مع مشروع ما ، يحتاج المستخدم فقط إلى توصيل الوحدة المطلوبة وتحديد مكونات NER التي يجب استخدامها عند البحث عن كيانات نموذج معين في التكوين.
فيما يلي مثال للتهيئة التي تستخدم أربعة مكونات NER مختلفة من مزودين اثنين عند البحث في النص:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
اقرأ المزيد عن استخدام Apache NlpCraft هنا . مطلوب حساب مطور Google صالح لاستخدام Google Language API.
دعم الكيان المركب
يعد دعم الكيانات المركبة هو الأكثر إثارة للاهتمام من الميزات المذكورة أعلاه ، دعنا نتناولها بمزيد من التفاصيل.
الكيان المركب هو كيان محدد على أساس كيان آخر. لنلقي نظرة على مثال. لنفترض أنك تقوم بتطوير نظام تحكم في البرمجة اللغوية العصبية (NLP) قائم على النوايا (انظر Alexa و Google Dialogflow و Alice و Apache Nlpraft وما إلى ذلك) ، ويعمل نموذجك مع الجغرافيا ، ولكن فقط للولايات المتحدة. يمكنك استخدام أي مكون بحث جغرافي مثل " nlpcraft: city " واستخدامه مباشرة.
علاوة على ذلك ، عند تفعيل النية ، في الوظيفة المقابلة (رد الاتصال) ، يجب عليك التحقق من قيمة الحقل " البلد"، وإذا لم تستوفِ الشروط المطلوبة ، فقم بإنهاء الوظيفة ، ومنع الإيجابيات الكاذبة. بعد ذلك ، يجب أن تعود إلى المطابقة وتحاول اختيار وظيفة أخرى أكثر ملاءمة.
ما الخطأ في هذا النهج:
- أنت تزيد من صعوبة العمل مع الوظائف المسماة عن طريق نقل التحكم منها إلى مؤشر ترابط العامل الرئيسي والعكس. بالإضافة إلى ذلك ، تجدر الإشارة إلى أنه ليست كل أنظمة الحوار لديها وظيفة نقل التحكم هذه.
- أنت تشوه منطق المطابقة بين الهدف ورمز الطريقة القابلة للتنفيذ.
حسنًا ... يمكنك إنشاء مكون NER الخاص بك من البداية للعثور على مدن أمريكية ، لكن هذه المهمة لم يتم حلها في خمس دقائق.
لنجربها بشكل مختلف. يمكنك تعقيد النية (في تلك الأنظمة حيثما أمكن ذلك) والبحث عن مدن تمت تصفيتها أيضًا حسب البلد. ولكن ، مرة أخرى ، لا توفر جميع الأنظمة إمكانية التصفية المعقدة حسب مجالات العناصر ، بالإضافة إلى أنك تعقد المقاصد ، والتي يجب أن تكون واضحة وبسيطة قدر الإمكان ، خاصة إذا كان هناك الكثير منها في المشروع.
يوفر Apache NlpCraft آلية لتحديد مكونات NER الأصلية بناءً على المكونات الموجودة. فيما يلي مثال على التكوين (تتوفر صيغة DSL الكاملة هنا ، ومثال على إنشاء العناصر هنا ):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
في هذا المثال ، نصف كيانًا جديدًا باسم "American city" - " custom: city: usa " ، استنادًا إلى " nlpcraft: city " الموجودة ، والتي تمت تصفيتها وفقًا لمعيار معين.
يمكنك الآن إنشاء أهداف بناءً على العنصر الجديد الذي تم إنشاؤه ، ولن تتسبب المدن الموجودة خارج الولايات المتحدة التي تمت مواجهتها في النص في إثارة نواياك بشكل غير مرغوب فيه.
مثال آخر:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
في هذا المثال ، حددنا كيانًا مسمى "city airport in the United States" - " custom: airport: usa ". عند تحديد هذا العنصر ، لم نقم فقط بترشيح المدن وفقًا لانتمائها إلى الدولة ، بل وضعنا أيضًا قاعدة إضافية وفقًا لها يجب أن يسبق اسم المدينة أي مرادف يحدد مفهوم "المطار". (اقرأ المزيد حول إنشاء مرادفات للعناصر عبر وحدات الماكرو - هنا ).
يمكن تعريف العناصر المركبة بأي درجة من التداخل ، أي إذا لزم الأمر ، يمكنك تصميم عناصر جديدة بناءً على " custom: airport: usa " الذي تم إنشاؤه حديثًا . لاحظ أيضًا أن جميع القيم المقيسة للكيانات الأم ، في هذه الحالة العنصر الأساسي “ nlpcraft: city"متوفرة أيضًا في عنصر" custom: airport: usa "، ويمكن استخدامها في جسم الوظيفة للنية المشغلة.
بالطبع ، يمكن تعريف "لبنات البناء" ليس فقط لجميع المكونات القياسية المدعومة من OpenNlp و Stanford و Google و Spacy و NlpCraft ، ولكن أيضًا لمكونات NER المخصصة ، مما يوسع قدراتها ويسمح لك بإعادة استخدام تطويرات البرامج الحالية.
يرجى ملاحظة ، في الواقع ، أنك لا تنتج مكونات جديدة لكل مهمة جديدة ، ولكن ببساطة قم بتكوينها أو "مزج" وظائفها مع العناصر الخاصة بك.
وبالتالي ، باستخدام "الكيانات المركبة" ، يمكن للمطور:
- تبسيط منطق بناء المقاصد بشكل كبير عن طريق نقلها جزئيًا إلى كتل بناء قابلة لإعادة الاستخدام.
- احصل على مكونات NER بسلوك جديد باستخدام تغييرات التكوين بدون تدريب نموذجي أو تشفير.
- إعادة استخدام الحلول الجاهزة بالجودة المتوقعة ، بالاعتماد على الاختبارات أو المقاييس الحالية.
خاتمة
آمل أن تكون نظرة عامة موجزة عن إيجابيات وسلبيات مكونات NER الحالية مفيدة للقراء ، وفهم كيف يمكن لـ Apache NlpCraft توسيع قدراتهم بشكل كبير وتكييف الحلول الحالية للمهام الجديدة سوف يسرع من تطوير مشاريعك.