المقدمة
تطورت تكنولوجيا التعلم الآلي بوتيرة مذهلة خلال العام الماضي. تشارك المزيد والمزيد من الشركات أفضل ممارساتها ، مما يفتح إمكانيات جديدة لإنشاء مساعدين رقميين أذكياء.
كجزء من هذه المقالة ، أريد أن أشارك تجربتي في تنفيذ المساعد الصوتي وأن أقدم لك بعض الأفكار لجعله أكثر ذكاءً وفائدة.

ماذا يمكن أن يفعل مساعد الصوت الخاص بي؟
| وصف المهارة | العمل دون اتصال | التبعيات المطلوبة |
| التعرف على الكلام وتوليفه | أيد | تثبيت نقطة PyAudio (باستخدام ميكروفون)
تثبيت Pyttsx3 (تركيب الكلام) يمكنك اختيار أحدهما أو كليهما للتعرف على الكلام:
|
| pip install pyowm (OpenWeatherMap) | ||
| Google ( ) | pip install google | |
| YouTube | - | |
| Wikipedia c | pip install wikipedia-api | |
| pip install googletrans (Google Translate) | ||
| - | ||
| « » | - | |
| ( ) | - | |
| - | ||
| TODO ... | ||
1.
لنبدأ بتعلم كيفية التعامل مع الإدخال الصوتي. نحتاج إلى ميكروفون واثنين من المكتبات المثبتة: PyAudio و SpeechRecognition.
لنعد الأدوات الأساسية للتعرف على الكلام:
import speech_recognition
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
voice_input = record_and_recognize_audio()
print(voice_input)
لنقم الآن بإنشاء وظيفة لتسجيل الكلام والتعرف عليه. للتعرف على الإنترنت ، نحتاج إلى Google ، حيث إنها تتمتع بجودة عالية في التعرف على عدد كبير من اللغات.
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
except speech_recognition.RequestError:
print("Check your Internet Connection, please")
return recognized_data
ولكن ماذا لو لم يكن هناك اتصال بالإنترنت؟ يمكنك استخدام حلول للتعرف دون اتصال. أنا شخصياً أحببت حقًا مشروع Vosk .
في الواقع ، لا تحتاج إلى تنفيذ خيار وضع عدم الاتصال إذا لم تكن بحاجة إليه. أردت فقط عرض كلتا الطريقتين في إطار عمل المقالة ، وقد اخترت بالفعل بناءً على متطلبات النظام لديك (على سبيل المثال ، Google بلا شك هي الشركة الرائدة في عدد لغات التعرف المتاحة).الآن ، بعد تنفيذ حل غير متصل بالإنترنت وإضافة نماذج اللغة الضرورية إلى المشروع ، في حالة عدم الوصول إلى الشبكة ، سننتقل تلقائيًا إلى التعرف دون اتصال بالإنترنت.
لاحظ أنه حتى لا أضطر إلى تكرار نفس العبارة مرتين ، قررت تسجيل الصوت من الميكروفون في ملف wav مؤقت سيتم حذفه بعد كل التعرف.
وبالتالي ، فإن الكود الناتج يبدو كما يلي:
أكمل كود التعرف على الكلام للعمل
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import wave # wav
import json # json- json-
import os #
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
قد تسأل "لماذا دعم إمكانات وضع عدم الاتصال؟"
في رأيي ، يجدر دائمًا التفكير في أن المستخدم قد يكون معزولًا عن الشبكة. في هذه الحالة ، يمكن أن يظل المساعد الصوتي مفيدًا إذا كنت تستخدمه كروبوت للمحادثة أو لحل عدد من المهام البسيطة ، على سبيل المثال ، عد شيء ما ، أو التوصية بفيلم ، أو المساعدة في اختيار المطبخ ، أو ممارسة لعبة ، إلخ.
الخطوة 2. تكوين المساعد الصوتي
نظرًا لأن مساعد الصوت لدينا يمكن أن يكون له جنس ولغة كلام ، ووفقًا للكلاسيكيات ، اسم ، فلنختار فئة منفصلة لهذه البيانات ، والتي سنعمل معها في المستقبل.
من أجل تعيين صوت لمساعدنا ، سوف نستخدم مكتبة تركيب الكلام دون اتصال بالإنترنت pyttsx3. سيجد تلقائيًا الأصوات المتاحة للتجميع على جهاز الكمبيوتر الخاص بنا ، اعتمادًا على إعدادات نظام التشغيل (لذلك ، من الممكن أن يكون لديك أصوات أخرى متاحة وستحتاج إلى فهارس مختلفة).
سنضيف أيضًا إلى الوظيفة الرئيسية تهيئة تركيب الكلام ووظيفة منفصلة لتشغيله. للتأكد من أن كل شيء يعمل ، دعنا نجري تحققًا بسيطًا من أن المستخدم قد استقبلنا ، ونمنحه تحية عودة من المساعد:
كود كامل لإطار عمل المساعد الصوتي (تركيب الكلام والتعرف عليه)
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import pyttsx3 # (Text-To-Speech)
import wave # wav
import json # json- json-
import os #
class VoiceAssistant:
"""
, , ,
"""
name = ""
sex = ""
speech_language = ""
recognition_language = ""
def setup_assistant_voice():
"""
(
)
"""
voices = ttsEngine.getProperty("voices")
if assistant.speech_language == "en":
assistant.recognition_language = "en-US"
if assistant.sex == "female":
# Microsoft Zira Desktop - English (United States)
ttsEngine.setProperty("voice", voices[1].id)
else:
# Microsoft David Desktop - English (United States)
ttsEngine.setProperty("voice", voices[2].id)
else:
assistant.recognition_language = "ru-RU"
# Microsoft Irina Desktop - Russian
ttsEngine.setProperty("voice", voices[0].id)
def play_voice_assistant_speech(text_to_speech):
"""
( )
:param text_to_speech: ,
"""
ttsEngine.say(str(text_to_speech))
ttsEngine.runAndWait()
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
# ( )
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
#
ttsEngine = pyttsx3.init()
#
assistant = VoiceAssistant()
assistant.name = "Alice"
assistant.sex = "female"
assistant.speech_language = "ru"
#
setup_assistant_voice()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
if command == "":
play_voice_assistant_speech("")
في الواقع ، أود هنا أن أتعلم كيفية كتابة مُركِّب الكلام بمفردي ، لكن معرفتي هنا لن تكون كافية. إذا كان بإمكانك اقتراح أدبيات جيدة أو دورة تدريبية أو حل موثق مثير للاهتمام سيساعدك على فهم هذا الموضوع بعمق ، يرجى كتابة التعليقات.
الخطوة 3. معالجة الأوامر
الآن بعد أن "تعلمنا" التعرف على الكلام وتوليفه بمساعدة التطورات الإلهية البسيطة لزملائنا ، يمكننا البدء في إعادة اختراع العجلة الخاصة بنا لمعالجة أوامر كلام المستخدم: D
في حالتي ، أستخدم خيارات متعددة اللغات لتخزين الأوامر ، حيث لا يوجد لدي الكثير الأحداث ، وأنا راضٍ عن دقة تعريف أمر معين. ومع ذلك ، بالنسبة للمشاريع الكبيرة ، أوصي بتقسيم التكوينات حسب اللغة.
يمكنني تقديم طريقتين لتخزين الأوامر.
1 الطريق
يمكنك استخدام كائن جميل يشبه JSON لتخزين النوايا ، وسيناريوهات التطوير ، والاستجابات في حالة المحاولات الفاشلة (غالبًا ما تُستخدم لروبوتات الدردشة). يبدو شيئًا مثل هذا:
config = {
"intents": {
"greeting": {
"examples": ["", "", " ",
"hello", "good morning"],
"responses": play_greetings
},
"farewell": {
"examples": ["", " ", "", " ",
"goodbye", "bye", "see you soon"],
"responses": play_farewell_and_quit
},
"google_search": {
"examples": [" ",
"search on google", "google", "find on google"],
"responses": search_for_term_on_google
},
},
"failure_phrases": play_failure_phrase
}
هذا الخيار مناسب لأولئك الذين يرغبون في تدريب مساعد للرد على العبارات الصعبة. علاوة على ذلك ، يمكنك هنا تطبيق نهج NLU وإنشاء القدرة على توقع نية المستخدم عن طريق التحقق منها مقابل تلك الموجودة بالفعل في التكوين.
سننظر في هذه الطريقة بالتفصيل في الخطوة 5 من هذه المقالة. في غضون ذلك ، سألفت انتباهك إلى خيار أبسط.
2 طريقة
يمكنك أن تأخذ قاموسًا مبسطًا ، والذي سيكون له نوع tuple قابل للتجزئة كمفاتيح (نظرًا لأن القواميس تستخدم التجزئة لتخزين العناصر واستردادها بسرعة) ، وستكون أسماء الوظائف التي سيتم تنفيذها في شكل قيم. للأوامر القصيرة ، الخيار التالي مناسب:
commands = {
("hello", "hi", "morning", ""): play_greetings,
("bye", "goodbye", "quit", "exit", "stop", ""): play_farewell_and_quit,
("search", "google", "find", ""): search_for_term_on_google,
("video", "youtube", "watch", ""): search_for_video_on_youtube,
("wikipedia", "definition", "about", "", ""): search_for_definition_on_wikipedia,
("translate", "interpretation", "translation", "", "", ""): get_translation,
("language", ""): change_language,
("weather", "forecast", "", ""): get_weather_forecast,
}
لمعالجتها ، نحتاج إلى إضافة الكود على النحو التالي:
def execute_command_with_name(command_name: str, *args: list):
"""
:param command_name:
:param args: ,
:return:
"""
for key in commands.keys():
if command_name in key:
commands[key](*args)
else:
pass # print("Command not found")
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
command_options = [str(input_part) for input_part in voice_input[1:len(voice_input)]]
execute_command_with_name(command, command_options)
سيتم تمرير الوسائط الإضافية إلى الوظيفة بعد كلمة الأمر. بمعنى ، إذا قلت عبارة " video cute cats " ، فإن الأمر " video " سوف يستدعي الدالة search_for_video_on_youtube () مع الوسيطة " cute cats " وسيقدم النتيجة التالية:
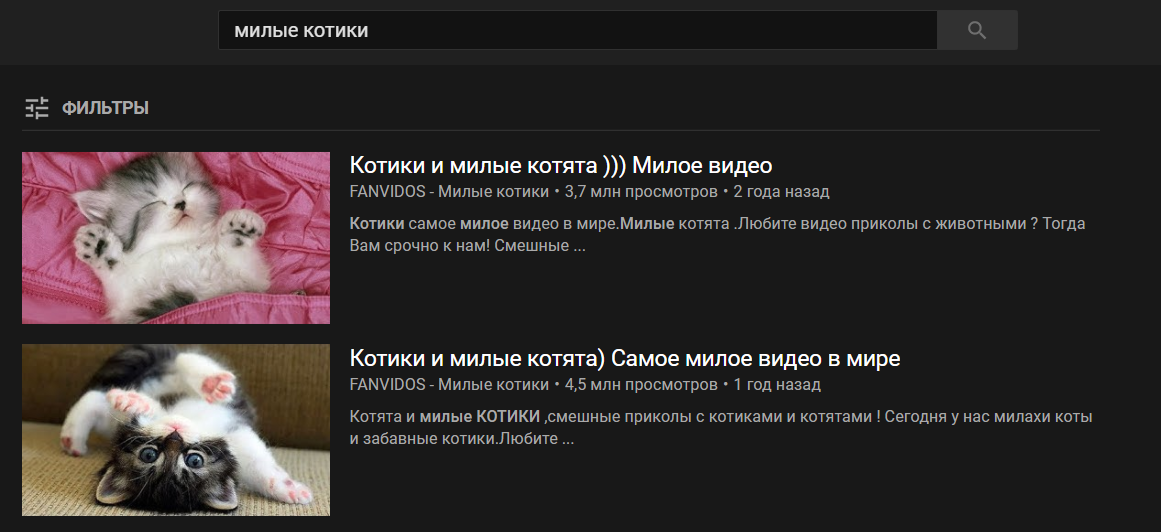
مثال على هذه الوظيفة مع معالجة الوسائط الواردة:
def search_for_video_on_youtube(*args: tuple):
"""
YouTube
:param args:
"""
if not args[0]: return
search_term = " ".join(args[0])
url = "https://www.youtube.com/results?search_query=" + search_term
webbrowser.get().open(url)
#
# , JSON-
play_voice_assistant_speech("Here is what I found for " + search_term + "on youtube")
هذا هو! الوظيفة الرئيسية للروبوت جاهزة. ثم يمكنك تحسينه إلى ما لا نهاية بطرق مختلفة. التنفيذ الخاص بي مع التعليقات التفصيلية متاح على GitHub الخاص بي .
أدناه سنلقي نظرة على عدد من التحسينات لجعل مساعدنا أكثر ذكاءً.
الخطوة 4. إضافة التعددية اللغوية
لتعليم مساعدنا العمل مع نماذج لغات متعددة ، سيكون من الأنسب تنظيم ملف JSON صغير بهيكل بسيط:
{
"Can you check if your microphone is on, please?": {
"ru": ", , ",
"en": "Can you check if your microphone is on, please?"
},
"What did you say again?": {
"ru": ", ",
"en": "What did you say again?"
},
}
في حالتي ، أستخدم التبديل بين الروسية والإنجليزية ، نظرًا لأن نماذج التعرف على الكلام والصوت لتركيب الكلام متاحة لي لهذا الغرض. سيتم اختيار اللغة اعتمادًا على لغة خطاب المساعد الصوتي نفسه.
لتلقي الترجمة ، يمكننا إنشاء فئة منفصلة بطريقة تعيد لنا سلسلة نصية مع الترجمة:
class Translation:
"""
"""
with open("translations.json", "r", encoding="UTF-8") as file:
translations = json.load(file)
def get(self, text: str):
"""
( )
:param text: ,
:return:
"""
if text in self.translations:
return self.translations[text][assistant.speech_language]
else:
#
#
print(colored("Not translated phrase: {}".format(text), "red"))
return text
في الوظيفة الرئيسية ، قبل الحلقة ، سنعلن مترجمنا على النحو التالي: مترجم = ترجمة ()
الآن ، عند تشغيل خطاب المساعد ، يمكننا الحصول على الترجمة على النحو التالي:
play_voice_assistant_speech(translator.get(
"Here is what I found for {} on Wikipedia").format(search_term))
كما ترى من المثال أعلاه ، يعمل هذا حتى مع تلك الأسطر التي تتطلب إدراج وسيطات إضافية. وبالتالي ، يمكنك ترجمة مجموعات "القياسية" من العبارات لمساعديك.
الخطوة 5. القليل من التعلم الآلي
دعنا الآن نعود إلى كائن JSON لتخزين أوامر متعددة الكلمات ، وهو أمر نموذجي لمعظم برامج الدردشة ، والتي ذكرتها في الفقرة 3. وهي مناسبة لأولئك الذين لا يرغبون في استخدام أوامر صارمة ويخططون لتوسيع فهمهم لنية المستخدم باستخدام NLU -طرق.
تحدث تقريبا، في هذه الحالة، عبارات " مساء الخير "، " مساء الخير " و " صباح الخير سينظر في" ما يعادلها. سوف يفهم المساعد أنه في جميع الحالات الثلاث ، كان قصد المستخدم هو الترحيب بمساعده الصوتي.
باستخدام هذه الطريقة ، يمكنك أيضًا إنشاء روبوت للمحادثة للمحادثات أو وضع محادثة لمساعد الصوت الخاص بك (للحالات التي تحتاج فيها إلى محاور).
لتنفيذ مثل هذا الاحتمال ، سنحتاج إلى إضافة وظيفتين:
def prepare_corpus():
"""
"""
corpus = []
target_vector = []
for intent_name, intent_data in config["intents"].items():
for example in intent_data["examples"]:
corpus.append(example)
target_vector.append(intent_name)
training_vector = vectorizer.fit_transform(corpus)
classifier_probability.fit(training_vector, target_vector)
classifier.fit(training_vector, target_vector)
def get_intent(request):
"""
:param request:
:return:
"""
best_intent = classifier.predict(vectorizer.transform([request]))[0]
index_of_best_intent = list(classifier_probability.classes_).index(best_intent)
probabilities = classifier_probability.predict_proba(vectorizer.transform([request]))[0]
best_intent_probability = probabilities[index_of_best_intent]
#
if best_intent_probability > 0.57:
return best_intent
وقم أيضًا بتعديل الوظيفة الرئيسية بشكل طفيف عن طريق إضافة تهيئة المتغيرات لإعداد النموذج وتغيير الحلقة إلى الإصدار المقابل للتكوين الجديد:
#
# ( )
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 3))
classifier_probability = LogisticRegression()
classifier = LinearSVC()
prepare_corpus()
while True:
#
#
voice_input = record_and_recognize_audio()
if os.path.exists("microphone-results.wav"):
os.remove("microphone-results.wav")
print(colored(voice_input, "blue"))
# ()
if voice_input:
voice_input_parts = voice_input.split(" ")
# -
#
if len(voice_input_parts) == 1:
intent = get_intent(voice_input)
if intent:
config["intents"][intent]["responses"]()
else:
config["failure_phrases"]()
# -
# ,
#
if len(voice_input_parts) > 1:
for guess in range(len(voice_input_parts)):
intent = get_intent((" ".join(voice_input_parts[0:guess])).strip())
if intent:
command_options = [voice_input_parts[guess:len(voice_input_parts)]]
config["intents"][intent]["responses"](*command_options)
break
if not intent and guess == len(voice_input_parts)-1:
config["failure_phrases"]()
ومع ذلك ، يصعب التحكم في هذه الطريقة: فهي تتطلب التحقق المستمر من أن هذه العبارة أو تلك لا يزال يتم تحديدها بشكل صحيح بواسطة النظام كجزء من نية معينة. لذلك ، يجب استخدام هذه الطريقة بعناية (أو تجربة النموذج نفسه).
خاتمة
هذا يختتم تعليمي الصغير.
سأكون سعيدًا إذا شاركت معي في التعليقات حلول مفتوحة المصدر التي تعرفها والتي يمكن تنفيذها في هذا المشروع ، بالإضافة إلى أفكارك حول الوظائف الأخرى عبر الإنترنت وغير المتصلة بالإنترنت التي يمكن تنفيذها.
يمكن العثور هنا على المصادر الموثقة لمساعد الصوت الخاص بي في نسختين .
ملاحظة: يعمل الحل على أنظمة التشغيل Windows و Linux و MacOS مع وجود اختلافات طفيفة عند تثبيت مكتبات PyAudio و Google.