
صورة كريستيان كريستيان على Unsplash
في المستقبل القريب ، سيكون من الممكن تنشيط مكبر الصوت Amazon Echo أو Nest Audio ، أو البحث في Google أو Siri على أجهزة Apple بدون تحية مثل "Hello ، Google!" بمساعدة الذكاء الاصطناعي ، طور علماء من الولايات المتحدة خوارزمية يفهم من خلالها المساعدون الصوتيون الأذكياء أن الشخص يتحدث إليهم.
في المحادثة العادية ، يقوم الأشخاص بتعيين المرسل إليه من الرسالة بمجرد النظر إليها. لكن معظم الأجهزة الصوتية مصممة للتفعيل من خلال عبارات رئيسية لا يلفظها أحد في التواصل الحقيقي. إن فهم الإشارات غير اللفظية من خلال المساعدين الصوتيين من شأنه أن يجعل التواصل أسهل وأكثر سهولة. خاصة إذا كان هناك العديد من هذه الأجهزة في المنزل.
لاحظ العلماء في جامعة كارنيجي ميلون أن الخوارزمية المطورة تحدد اتجاه الصوت (DoV) باستخدام ميكروفون.
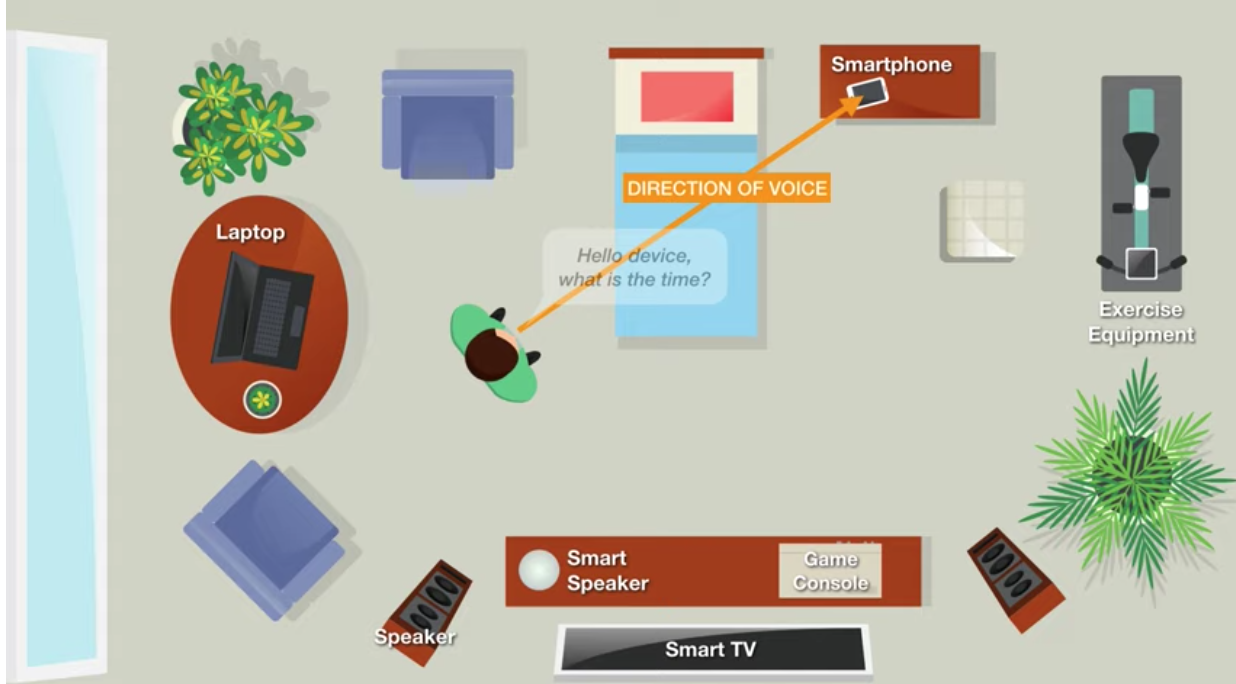
يختلف DoV عن اكتشاف اتجاه الوصول (DoA).
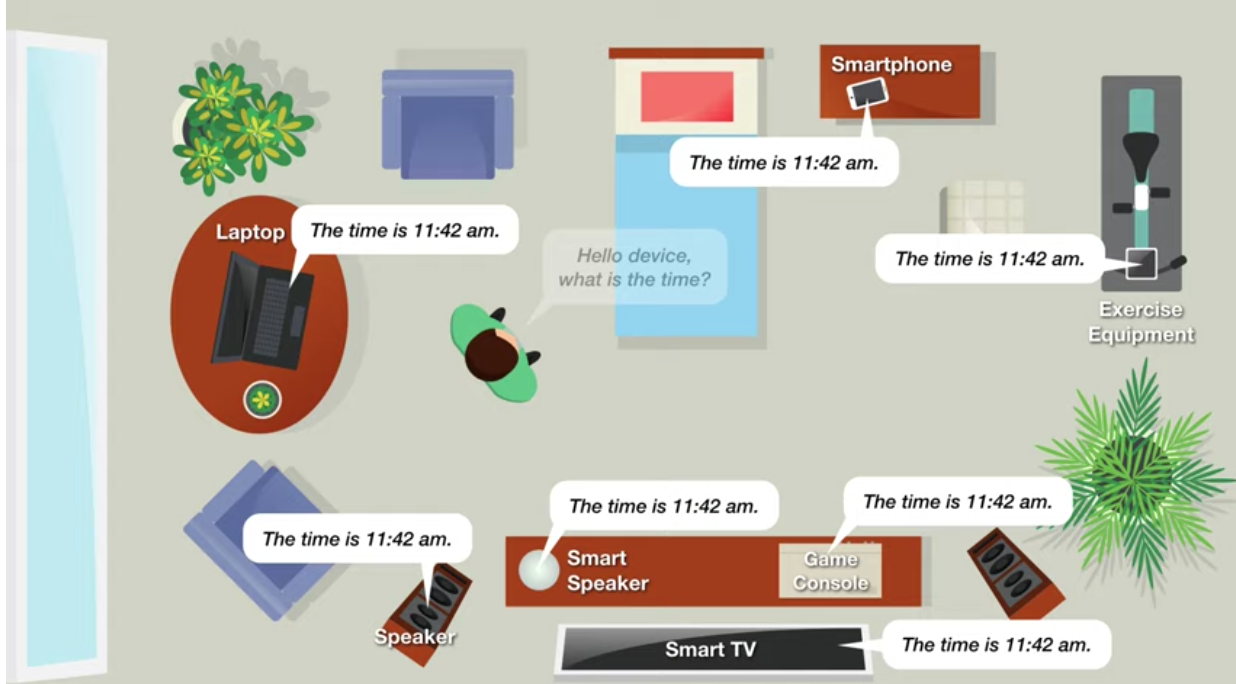
وفقًا للباحثين ، فإن استخدام DoV يجعل الأوامر المستهدفة ممكنة ، وهو ما يشبه التواصل البصري للمحاورين عند بدء محادثة. ومع ذلك ، فإن كاميرات الأجهزة ليست متورطة. وبالتالي ، هناك تفاعل طبيعي مع أنواع مختلفة من الأجهزة دون التباس.
من بين أمور أخرى ، ستعمل هذه التقنية على تقليل عدد عمليات التنشيط العرضية للمساعدين الصوتيين ، والتي تكون في وضع الاستعداد طوال الوقت.
تعتمد تقنية الصوت الجديدة على ميزات انتشار صوت الكلام. إذا تم توجيه الصوت إلى الميكروفون ، فإن الترددات المنخفضة والعالية تهيمن عليه. إذا انعكس الصوت ، أي أنه تم توجيهه مبدئيًا إلى جهاز آخر ، فسيكون هناك انخفاض ملحوظ في الترددات العالية مقارنة بالترددات المنخفضة. تحلل
الخوارزمية أيضًاانتشار الصوت في أول 10 مللي ثانية. هناك سيناريوهان محتملان هنا: يتم توجيه
المستخدم نحو الميكروفون. ستكون الإشارة التي تصل أولاً إلى الميكروفون واضحة مقارنة بالإشارات الأخرى المحتملة المنعكسة من الأجهزة الأخرى في المنزل.
يتم إبعاد المستخدم عن الميكروفون. سيتم تكرار جميع اهتزازات الصوت وتشويهها.
الخوارزمية تقيس شكل الموجة وتحسب ذروة شدتها وتقارنها بمتوسط القيمة وتحدد ما إذا كان الصوت موجهًا نحو الميكروفون أم لا.
من خلال قياس انتشار الصوت ، تمكن العلماء من تحديد بدقة 93.1٪ ما إذا كان السماعة أمام ميكروفون معين أم لا. وأشاروا إلى أن هذه هي أفضل نتيجة حتى الآن وخطوة مهمة نحو تطبيق الحل في الأجهزة الموجودة. عند محاولة تحديد واحدة من ثماني الزوايا التي ينظر الشخص إلى الجهاز، و كان دقة 65.4٪ تحققت . لا يزال هذا غير كافٍ للتطبيق ، والذي يتمثل جوهره في التفاعل النشط مع المستخدمين.
لجمع المعلومات ، استخدم المهندسون لغة Python ، وتمت معالجة الإشارات بناءً على خوارزمية مصنف Extra-Trees.
البيانات والخوارزمية التي تم جمعها أثناء التطوير مفتوحة على GitHub . يمكن استخدامها عند إنشاء مساعد الصوت الخاص بك.
