مرحبا هبر! سأوضح لك في هذه المقالة كيفية إجراء تحليل تردد للغة الإنترنت الروسية الحديثة واستخدامها لفك تشفير النص. من يهتم ، أهلا بك تحت الخفض!

تحليل تردد لغة الإنترنت الروسية
كمصدر حيث يمكنك الحصول على الكثير من النصوص بلغة الإنترنت الحديثة ، تم أخذ شبكة التواصل الاجتماعي فكونتاكتي ، أو بشكل أكثر دقة ، هذه تعليقات على المنشورات في مجتمعات مختلفة من هذه الشبكة. اخترت كرة القدم الحقيقية كمجتمع . لتحليل التعليقات ، استخدمت Vkontakte API :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passكانت النتيجة حوالي 200 ميغا بايت من النص. الآن نحسب الحرف الذي يظهر كم مرة:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyيمكن مقارنة النتائج التي تم الحصول عليها مع نتائج Wikipedia وعرضها على النحو التالي:
1) مخطط المقارنة
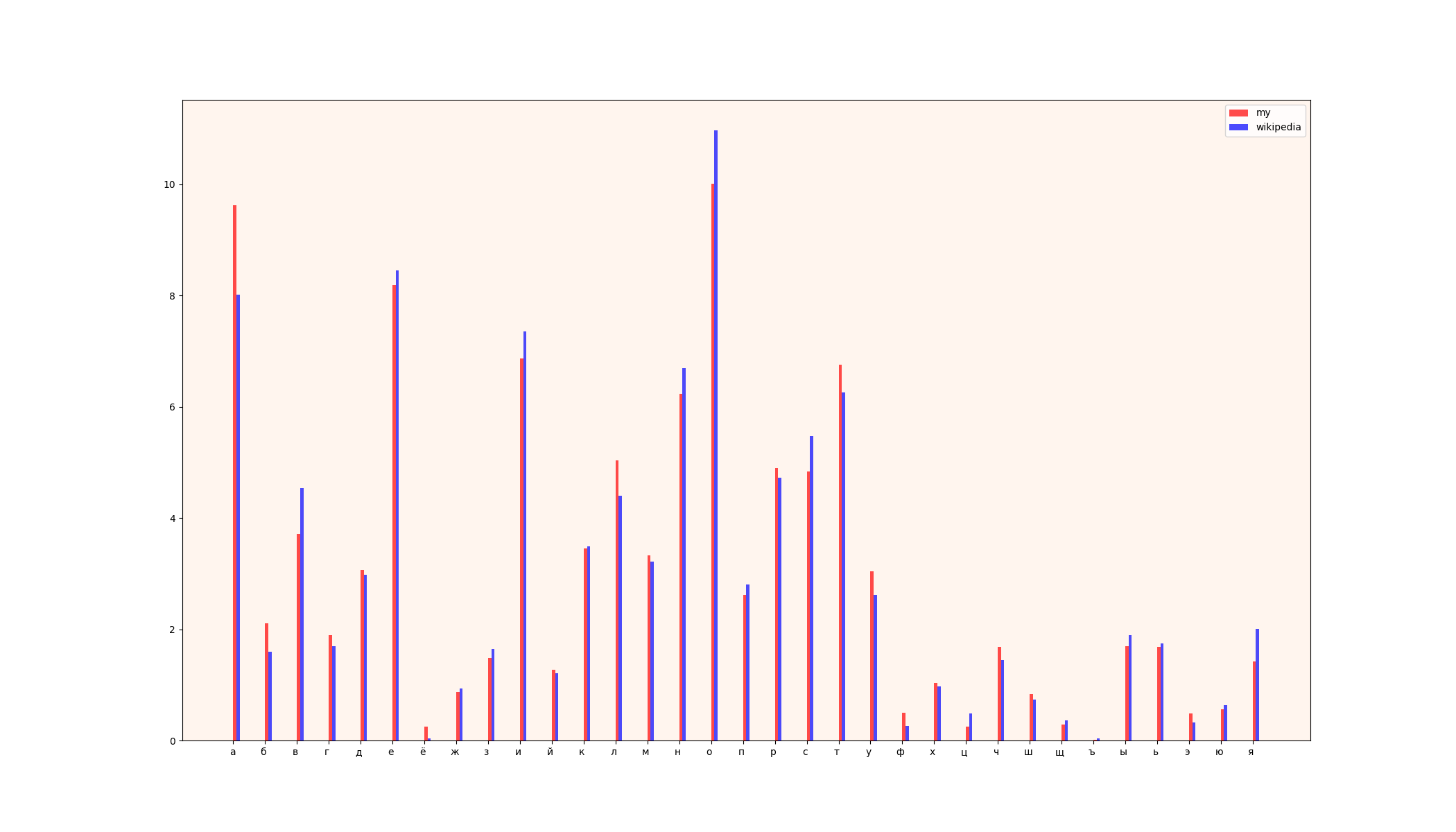
2) جداول (يسار - بيانات ويكيبيديا ، يمين - بياناتي)
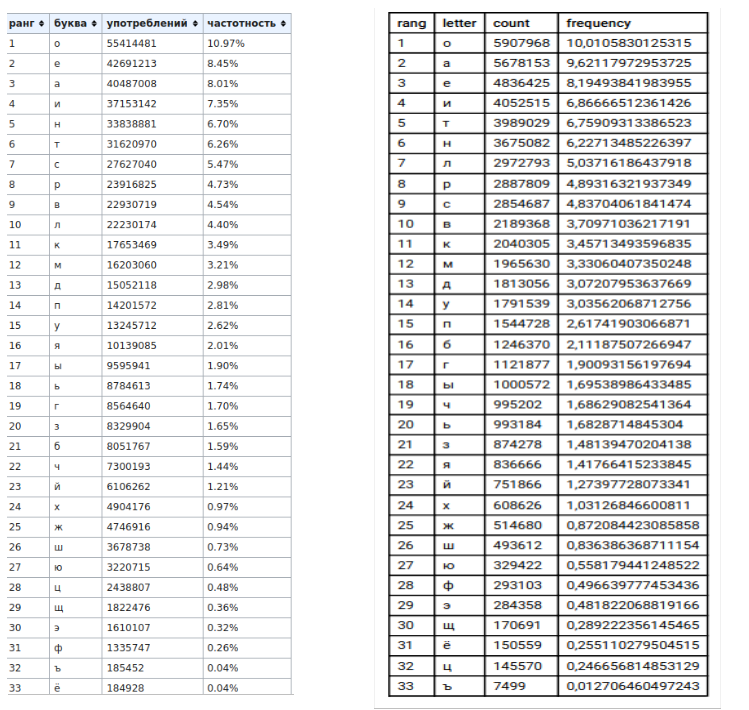
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
إذا نظرت إلى النص الذي تم فك تشفيره ، فيمكنك تخمين المكان الذي أخطأت فيه الخوارزمية الخاصة بنا: قتال → يفعل ، vadio → راديو ، toho → بالإضافة ، يؤدي → الأشخاص. وبالتالي ، من الممكن فك شفرة النص بأكمله ، على الأقل لفهم معنى النص. أريد أيضًا أن أشير إلى أن هذه الطريقة ستكون فعالة في فك تشفير النصوص الطويلة فقط التي تم تشفيرها باستخدام طرق التشفير المتماثل. الكود الكامل متاح على جيثب .