
على مدار السنوات الثلاث الماضية ، قامت Nvidia بإنشاء شرائح رسومات يتم فيها تثبيت شرائح إضافية بالإضافة إلى النوى المعتادة المستخدمة في التظليل. هذه النوى ، التي تسمى نوى التنسور ، موجودة بالفعل في الآلاف من أجهزة الكمبيوتر المكتبية وأجهزة الكمبيوتر المحمولة ومحطات العمل ومراكز البيانات حول العالم. لكن ماذا يفعلون وما الذي يستخدمونه؟ هل هم مطلوبون حتى في بطاقات الرسوميات؟
سنشرح اليوم ما هو الموتر وكيف يتم استخدام نواة الموتر في الرسومات وعالم التعلم العميق.
درس رياضيات قصير
لفهم ما تفعله نوى الموتر وما يمكن استخدامه من أجله ، نكتشف أولاً ماهية الموترات. تقوم جميع المعالجات الدقيقة ، بغض النظر عن المهمة التي تؤديها ، بإجراء عمليات حسابية على الأرقام (الجمع ، الضرب ، إلخ).
في بعض الأحيان تحتاج هذه الأرقام إلى التجميع لأنها تحمل معنى معينًا لبعضها البعض. على سبيل المثال ، عندما تعالج الشريحة البيانات لتقديم الرسومات ، يمكنها التعامل مع قيم عدد صحيح واحد (على سبيل المثال ، +2 أو +115) كعامل قياس ، أو مجموعة من العوامات (+0.1 ، -0.5 ، +0.6) باعتبارها إحداثيات نقطة في مساحة ثلاثية الأبعاد. في الحالة الثانية ، تكون جميع عناصر البيانات الثلاثة مطلوبة لموضع النقطة.
موترهو كائن رياضي يصف العلاقات بين الكائنات الرياضية الأخرى المرتبطة ببعضها البعض. يتم عرضها عادةً كمصفوفة من الأرقام ، تظهر أبعادها أدناه.

أبسط نوع موتر له بعد صفر ويتكون من قيمة واحدة ؛ خلاف ذلك ، يطلق عليه سلمي . مع زيادة عدد الأبعاد ، نواجه هياكل رياضية شائعة أخرى:
- 1 البعد = متجه
- 2 أبعاد = مصفوفة
بالمعنى الدقيق للكلمة ، العدد القياسي هو موتر 0 × 0 ، والمتجه هو 1 × 0 ، والمصفوفة 1 × 1 ، ولكن من أجل البساطة والإشارة إلى نوى الموتر لوحدة معالجة الرسومات ، سننظر في الموترات فقط في شكل مصفوفات.
يعد الضرب (أو المنتج) من أهم العمليات الحسابية التي يتم إجراؤها على المصفوفات. دعنا نلقي نظرة على كيفية ضرب مصفوفتين بأربعة صفوف وأعمدة بيانات ببعضهما البعض:
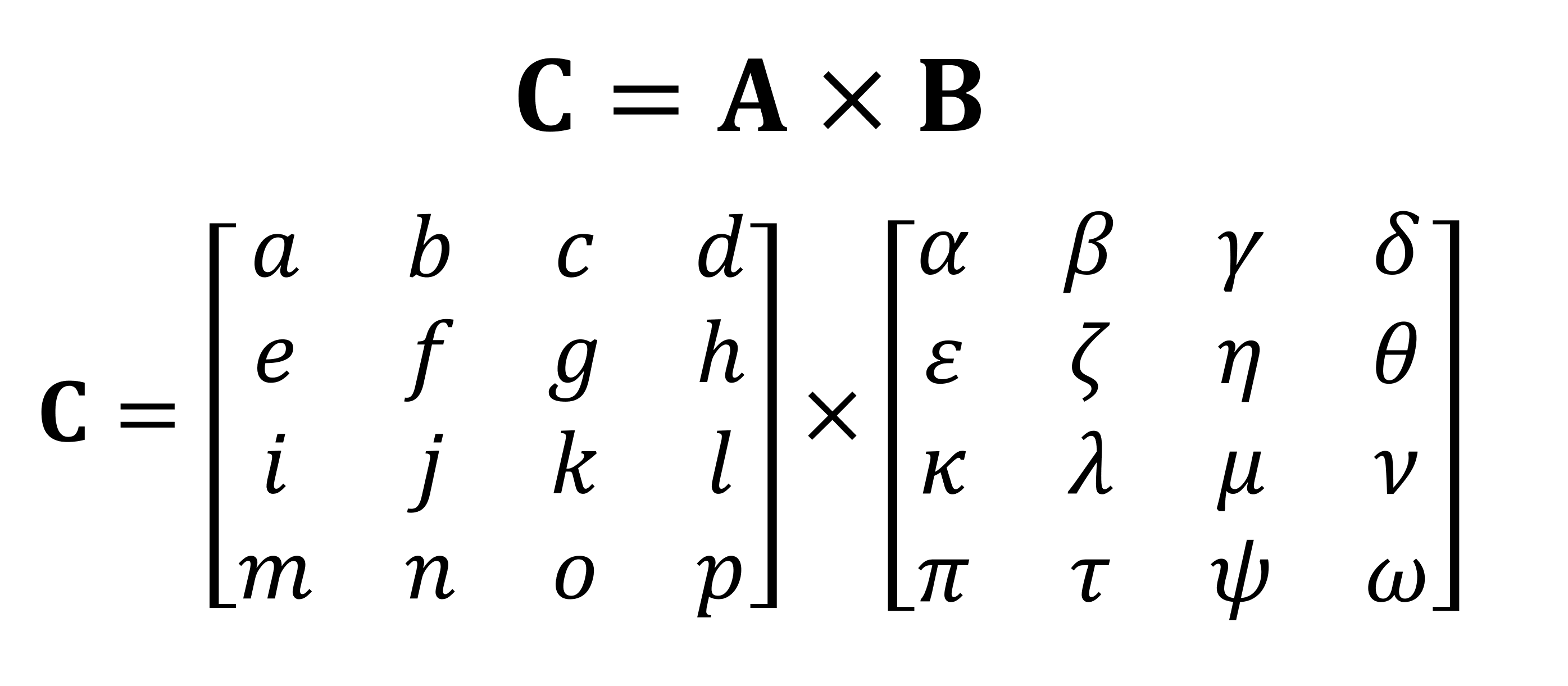
ستكون النتيجة النهائية للضرب دائمًا نفس عدد الصفوف كما في المصفوفة الأولى ، ونفس عدد الأعمدة كما في الثانية. كيف تضاعف هاتين المصفوفتين؟ مثله:
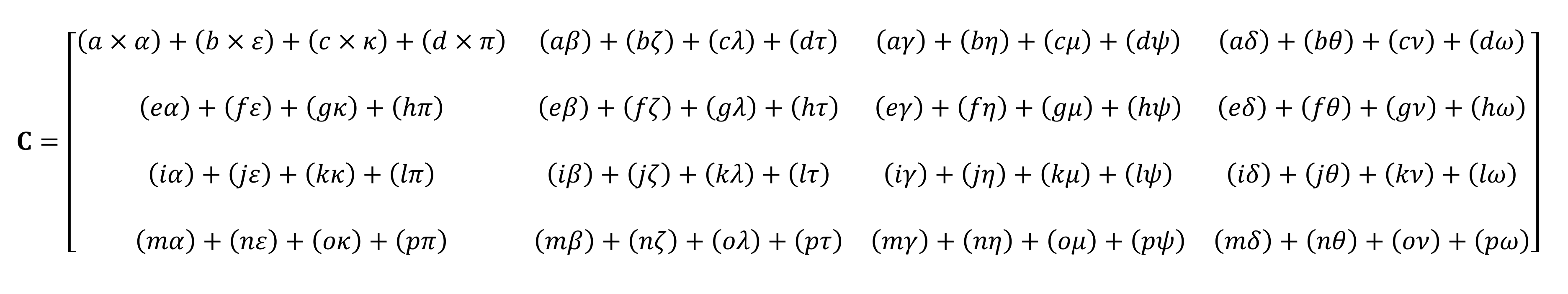
لن يكون من الممكن حسابها على الأصابع
كما ترى ، فإن حساب حاصل ضرب المصفوفات "البسيط" يتكون من مجموعة كاملة من عمليات الضرب والإضافة الصغيرة. نظرًا لأن أي وحدة معالجة مركزية حديثة يمكنها إجراء هاتين العمليتين ، يمكن إجراء أبسط أجهزة الموتر بواسطة كل كمبيوتر مكتبي أو كمبيوتر محمول أو جهاز لوحي.
ومع ذلك ، فإن المثال الموضح أعلاه يحتوي على 64 عملية ضرب و 48 إضافة ؛ يعطي كل منتج صغير قيمة يجب تخزينها في مكان ما قبل إضافتها إلى المنتجات الثلاثة الصغيرة الأخرى بحيث يمكن تخزين قيمة الموتر النهائية لاحقًا. لذلك ، على الرغم من البساطة الرياضية لمضاعفات المصفوفة ، إلا أنها مكلفة من الناحية الحسابية . - من الضروري استخدام الكثير من السجلات ، ويجب أن تكون ذاكرة التخزين المؤقت قادرة على التعامل مع مجموعة من عمليات القراءة والكتابة.

بنية Intel Sandy Bridge ، التي قدمت لأول مرة امتدادات AVX
على مر السنين ، كان لمعالجات AMD و Intel امتدادات مختلفة (MMX ، SSE ، والآن AVX - وكلها عبارة عن SIMD ، بيانات متعددة التعليمات الفردية ) ، مما يسمح للمعالج بمعالجة العديد من الأرقام في وقت واحد النقطة العائمة؛ هذا هو بالضبط ما هو مطلوب لضرب المصفوفة.
ولكن هناك نوع خاص من المعالج الذي هو على وجه التحديد مصمم للتعامل مع عمليات SIMD: وحدة معالجة الرسومات (GPU).
أذكى من الآلة الحاسبة العادية؟
في عالم الرسومات ، من الضروري نقل كميات هائلة من المعلومات ومعالجتها في وقت واحد في شكل موجهات. نظرًا لقدرتها على المعالجة المتوازية ، تعد وحدات معالجة الرسومات مثالية لمعالجة الموتر ؛ تدعم جميع وحدات معالجة الرسومات الحديثة وظيفة تسمى GEMM ( General Matrix Multiplication ).
هذه عملية "ملتصقة" يتم فيها ضرب مصفوفتين ثم يتم تجميع النتيجة مع مصفوفة أخرى. توجد قيود مهمة على تنسيق المصفوفات ، وكلها مرتبطة بعدد الصفوف والأعمدة في كل مصفوفة.

متطلبات صف وعمود GEMM: المصفوفة A (mxk) ، المصفوفة B (kxn) ، المصفوفة C (mxn)
عادةً ما تعمل الخوارزميات المستخدمة لإجراء العمليات على المصفوفات بشكل أفضل عندما تكون المصفوفات مربعة (على سبيل المثال ، ستعمل مصفوفة 10 × 10 أفضل من 50 × 2) وصغيرة الحجم نوعًا ما. لكنها ستظل تعمل بشكل أفضل إذا تمت معالجتها على معدات مصممة حصريًا لمثل هذه العمليات.
في ديسمبر 2017 ، أصدرت Nvidia بطاقة رسومات مزودة بوحدة معالجة الرسومات (GPU) تتميز بهندسة فولتا الجديدة . كانت تستهدف الأسواق الاحترافية ، لذلك لم يتم استخدام هذه الشريحة في نماذج GeForce. كانت فريدة من نوعها لأنها كانت أول وحدة معالجة رسومات تحتوي على نوى فقط لحسابات الموتر.

بطاقة رسومات Nvidia Titan V مع شريحة GV100 Volta. نعم ، يمكنك تشغيل Crysis عليه تم تصميم
نوى Nvidia الموتر لتنفيذ 64 GEMM لكل دورة ساعة مع مصفوفات 4 × 4 تحتوي على قيم FP16 (أرقام الفاصلة العائمة من 16 بت) أو مضاعفة FP16 مع إضافة FP32. هذه الموترات صغيرة الحجم جدًا ، لذلك عند معالجة مجموعات حقيقية من البيانات ، تعالج النواة أجزاء صغيرة من المصفوفات الكبيرة ، مما يبني الإجابة النهائية.
بعد أقل من عام ، أصدرت Nvidia بنية تورينج . هذه المرة ، تم تثبيت نوى الموتر أيضًا في نموذج GeForceمستوى المستهلك. تم تحسين النظام لدعم تنسيقات البيانات الأخرى ، مثل INT8 (قيمة عدد صحيح 8 بت) ، ولكن بخلاف ذلك كانت تعمل بنفس الطريقة كما في فولتا.

في وقت سابق من هذا العام ، ظهرت بنية Ampere لأول مرة في وحدة معالجة الرسومات لمركز البيانات A100 ، وهذه المرة قامت Nvidia بتحسين أداء (256 جم لكل دورة بدلاً من 64) ، وإضافة تنسيقات بيانات جديدة ، والقدرة على معالجة موتر متناثر سريع للغاية (مصفوفات مع العديد الأصفار). يمكن
للمبرمجين الوصول إلى نوى الموتر لرقائق Volta و Turing و Ampere بسهولة بالغة: يحتاج الكود فقط إلى استخدام علامة تخبر API والمحركات باستخدام نوى الموتر ، ويجب أن يكون نوع البيانات مدعومًا بواسطة النوى ، ويجب أن تكون أبعاد المصفوفة مضاعفات 8. كل هذه الظروف ستعتني بها المعدات.
كل هذا رائع ، ولكن ما مدى كفاءة Tensor Cores في معالجة GEMM من نوى GPU العادية؟
عندما تم إصدار Volta ، أجرى Anandtech اختبارات الرياضيات على ثلاث بطاقات Nvidia: Volta الجديدة ، أقوى بطاقة في تشكيلة Pascal ، وبطاقة Maxwell القديمة.
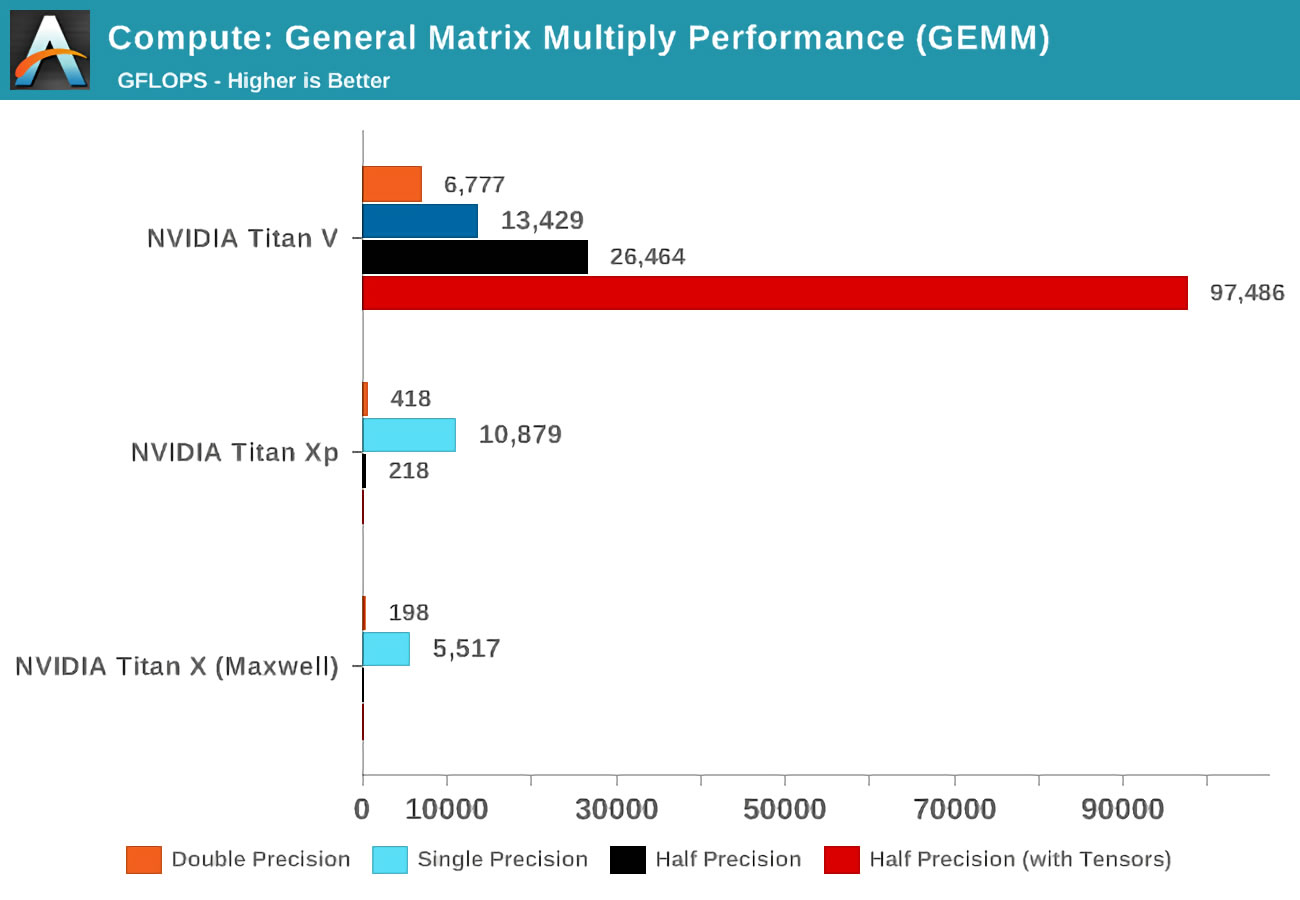
يشير مفهوم الدقة (الدقة) إلى عدد البتات المستخدمة لأرقام الفاصلة العائمة في المصفوفات: يشير مزدوج (مزدوج) إلى 64 ، ويشير واحد (مفرد) - 32 وهكذا. المحور الأفقي هو الحد الأقصى لعدد عمليات النقطة العائمة التي يتم إجراؤها في الثانية ، أو FLOPs لفترة قصيرة (تذكر أن GEMM هو 3 FLOPs).
ما عليك سوى إلقاء نظرة على النتائج عند استخدام نواة الموتر بدلاً من ما يسمى بنواة CUDA! من الواضح أنهم مدهشون في هذه الوظيفة ، لكن ماذا يمكننا أن نفعل بحبات التنسور؟
الرياضيات التي تجعل كل شيء أفضل
تعد حوسبة التنسور مفيدة للغاية في الفيزياء والهندسة ، فهي تُستخدم لحل جميع أنواع المشكلات المعقدة في ميكانيكا الموائع والكهرومغناطيسية والفيزياء الفلكية ، ومع ذلك ، فإن أجهزة الكمبيوتر التي تم استخدامها لمعالجة هذه الأرقام عادةً ما كانت تؤدي عمليات مصفوفة في مجموعات كبيرة من وحدات المعالجة المركزية.
من المجالات الأخرى التي تحظى فيها المتوترات بشعبية التعلم الآلي ، وخاصة قسمها الفرعي "التعلم العميق". يتلخص معناها في معالجة مجموعات البيانات الضخمة في مصفوفات عملاقة تسمى الشبكات العصبية . يتم تعيين وزن معين للاتصالات بين قيم البيانات المختلفة - وهو رقم يعبر عن أهمية اتصال معين.
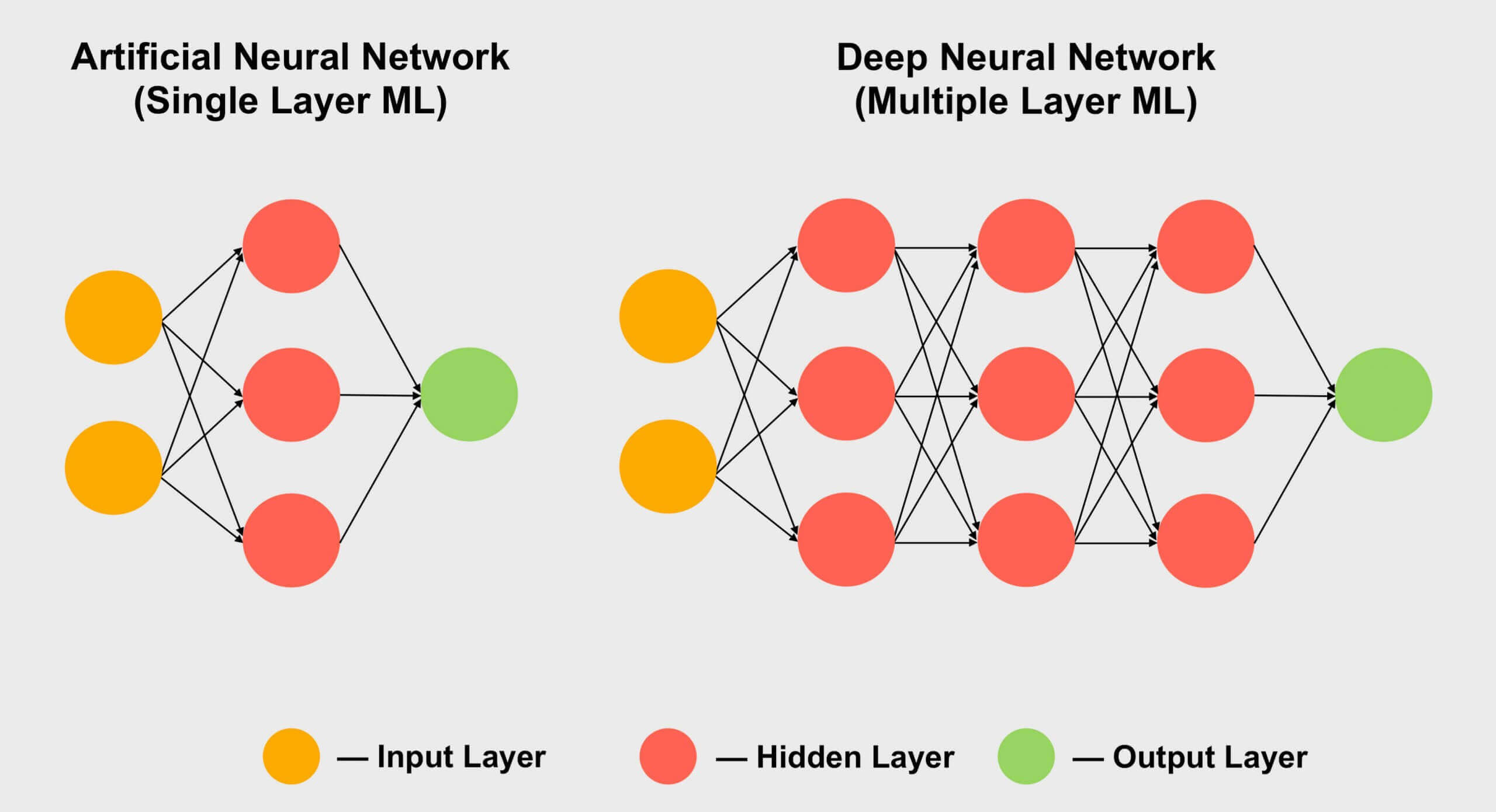
لذلك عندما نحتاج إلى معرفة كيفية تفاعل كل هذه المئات ، إن لم يكن الآلاف من الاتصالات ، نحتاج إلى مضاعفة كل جزء من البيانات في الشبكة بكل أوزان الاتصال الممكنة. بعبارة أخرى ، اضرب مصفوفتين ، وهي رياضيات موتر كلاسيكية!

رقائق Google TPU 3.0 مغطاة بنظام تبريد مائي
وهذا هو السبب في أن جميع أجهزة الكمبيوتر العملاقة ذات التعلم العميق تستخدم وحدات معالجة الرسومات ، وهي دائمًا Nvidia تقريبًا. ومع ذلك ، فقد طورت بعض الشركات معالجاتها الخاصة من نوى الموتر. أعلنت Google ، على سبيل المثال ، عن تطوير أول وحدة معالجة موترية (TPU ) في عام 2016 ، لكن هذه الرقائق متخصصة جدًا لدرجة أنها لا تستطيع القيام بأي شيء بخلاف العمليات باستخدام المصفوفات.
نوى الموتر في وحدات معالجة الرسومات للمستهلك (GeForce RTX)
ولكن ماذا لو اشتريت بطاقة رسومات Nvidia GeForce RTX ، ولم أكن عالم فيزياء فلكية يحل مشاكل Riemannian المتشعبة ، أو خبيرًا يجرب أعماق الشبكة العصبية التلافيفية ...؟ كيف يمكنني استخدام حبات التنسور؟
في كثير من الأحيان ، لا تنطبق على عرض الفيديو العادي أو ترميزه أو فك تشفيره ، لذلك قد يبدو أنك أهدرت أموالًا على ميزة غير مجدية. ومع ذلك ، قامت Nvidia ببناء نوى موتر في منتجاتها الاستهلاكية في 2018 (Turing GeForce RTX) أثناء تنفيذ DLSS - Deep Learning Super Sampling .

المبدأ بسيط: عرض الإطار بدقة منخفضة إلى حد ما ، وبعد الانتهاء ، قم بزيادة دقة النتيجة النهائية بحيث تتطابق مع أبعاد الشاشة "الأصلية" للشاشة (على سبيل المثال ، العرض بدقة 1080 بكسل ، ثم تغيير الحجم إلى 1400 بكسل). يؤدي ذلك إلى تحسين الأداء نظرًا لأنه تتم معالجة عدد أقل من وحدات البكسل ولا تزال الشاشة تنتج صورة جميلة.
تتمتع وحدات التحكم بهذه الميزة لسنوات ، وتوفر العديد من ألعاب الكمبيوتر الحديثة هذه الميزة أيضًا. في Assassin's Creed: Odyssey من Ubisoft ، يمكنك تقليل دقة العرض إلى أقل من 50٪ من دقة الشاشة. لسوء الحظ ، النتائج لا تبدو جميلة جدًا. هذا ما تبدو عليه اللعبة بدقة 4K مع أقصى إعدادات للرسومات:

في الدقة العالية ، تبدو القوام أجمل لأنها تحتفظ بمزيد من التفاصيل. ومع ذلك ، فإن الأمر يتطلب الكثير من المعالجة لعرض هذه البكسلات على الشاشة. ألقِ نظرة الآن على ما يحدث عند ضبط العرض على 1080 بكسل (25٪ من العدد السابق للبكسل) ، باستخدام التظليل في النهاية لتمديد الصورة إلى 4K.

بسبب ضغط jpeg ، قد لا يكون الفرق ملحوظًا على الفور ، ولكن يمكنك أن ترى أن درع الشخصية والصخرة في المسافة تبدو ضبابية. دعنا نكبر جزء من الصورة لإلقاء نظرة فاحصة:

يتم تقديم الصورة على اليسار بدقة 4K ؛ الصورة على اليمين 1080 بكسل ممتدة إلى 4K. يكون الاختلاف أكثر وضوحًا في الحركة ، لأن تخفيف كل التفاصيل يتحول بسرعة إلى فوضى ضبابية. يمكن استعادة جزء من الحدة بفضل تأثير زيادة حدة برامج تشغيل بطاقة الرسومات ، لكننا نتمنى ألا نضطر إلى القيام بذلك على الإطلاق.
هذا هو المكان الذي تلعب فيه DLSS - في الإصدار الأولحللت هذه التكنولوجيا Nvidia العديد من الألعاب المختارة ؛ ركضوا بدقة عالية ، دقة منخفضة ، مع أو بدون تنعيم. في كل هذه الأوضاع ، تم إنشاء مجموعة من الصور ثم تحميلها في أجهزة الكمبيوتر العملاقة للشركة ، والتي استخدمت شبكة عصبية لتحديد أفضل السبل لتحويل صورة 1080 بكسل إلى صورة مثالية عالية الدقة.

يجب أن أقول أن DLSS 1.0 لم يكن مثاليًا : فغالبًا ما كانت التفاصيل مفقودة وظهر وميض غريب في بعض الأماكن. بالإضافة إلى ذلك ، لم تستخدم نوى الموتر الخاصة ببطاقة الرسومات نفسها (تم تشغيلها على شبكة Nvidia) وتطلبت كل لعبة تدعم DLSS بحثًا منفصلًا من Nvidia لإنشاء خوارزمية الترقية.

عندما تم إصدار الإصدار 2.0 في أوائل عام 2020 ، تم إجراء تحسينات كبيرة عليه. الأهم من ذلك ، أن حواسيب Nvidia الفائقة تستخدم الآن فقط لإنشاء خوارزمية عامة للترقية - يستخدم الإصدار الجديد من DLSS بيانات من إطار تم عرضه لمعالجة وحدات البكسل باستخدام نموذج عصبي (نوى موتر GPU).

نحن معجبون بإمكانيات DLSS 2.0 ، ولكن حتى الآن عدد قليل جدًا من الألعاب يدعمها - في وقت كتابة هذا التقرير ، كان هناك 12 فقط مطورين يرغبون في تنفيذها في ألعابهم المستقبلية ، ولسبب وجيه.
يمكن أن تحقق أي زيادة في الحجم مكاسب كبيرة في الإنتاجية ، لذلك يمكنك أن تثق في أن DLSS ستستمر في التطور.
على الرغم من أن النتائج المرئية لـ DLSS ليست مثالية دائمًا ، فمن خلال تحرير موارد العرض ، يمكن للمطورين إضافة المزيد من التأثيرات المرئية أو توفير مستوى واحد من الرسومات عبر نطاق أوسع من الأنظمة الأساسية.
على سبيل المثال ، غالبًا ما يتم الإعلان عن DLSS جنبًا إلى جنب مع تتبع الأشعة في الألعاب "التي تدعم RTX". تحتوي بطاقات GeForce RTX على كتل حسابية إضافية تسمى RT cores ، وهي كتل منطقية متخصصة لتسريع تقاطعات مثلث الأشعة واجتياز التسلسل الهرمي للحجم المحيط (BVH). هاتان العمليتان عمليتان تستغرقان وقتًا طويلاً للغاية وتحددان كيفية تفاعل الضوء مع الكائنات الأخرى في المشهد.
كما اكتشفنا ، تتبع الأشعةإنها عملية تستغرق وقتًا طويلاً ، لذا لضمان مستوى مقبول من معدل الإطارات في الألعاب ، يجب على المطورين تحديد عدد الأشعة والانعكاسات التي يتم إجراؤها في المشهد. يمكن أن تنتج هذه العملية صورًا محببة ، لذلك يجب تطبيق خوارزمية تقليل الضوضاء ، مما يزيد من تعقيد المعالجة. من المتوقع أن تعمل نواة الموتر على تحسين أداء هذه العملية من خلال القضاء على الضوضاء باستخدام الذكاء الاصطناعي ، ولكن هذا لم يتحقق بعد: لا تزال معظم التطبيقات الحديثة تستخدم نواة CUDA لهذه المهمة. من ناحية أخرى ، نظرًا لأن DLSS 2.0 أصبح أسلوبًا عمليًا للغاية لتكبير الحجم ، يمكن استخدام Tensor Kernels بشكل فعال لتعزيز معدلات الإطارات بعد تتبع الأشعة في المشهد.
هناك خطط أخرى للاستفادة من بطاقات Tensor Cores الخاصة ببطاقات GeForce RTX ، مثل تحسين الرسوم المتحركة للشخصية أو محاكاة الأنسجة . ولكن كما هو الحال مع DLSS 1.0 ، سوف يمر وقت طويل قبل أن تكون هناك مئات الألعاب التي تستخدم حوسبة المصفوفة المتخصصة على وحدة معالجة الرسومات.
بداية واعدة
لذا ، فإن الوضع مثل هذا - نوى موتر ، وحدات أجهزة ممتازة ، والتي ، مع ذلك ، توجد فقط في بعض البطاقات المخصصة للمستهلكين. هل سيتغير أي شيء في المستقبل؟ نظرًا لأن Nvidia قد قامت بالفعل بتحسين أداء كل Tensor Core بشكل كبير في بنية Ampere الخاصة بها ، فهناك احتمال قوي بأن يتم تثبيتها في طراز المدى المنخفض والمتوسط.
على الرغم من عدم وجود مثل هذه النوى بعد في وحدات معالجة الرسومات لـ AMD و Intel ، فربما نراها في المستقبل. تمتلك AMD نظامًا لشحذ أو تحسين التفاصيل في الإطارات النهائية على حساب انخفاض طفيف في الأداء ، لذلك قد تلتزم الشركة بهذا النظام ، خاصةً أنه لا يحتاج إلى تكامل من قبل المطورين ، ويكفي لتمكينه في السائقين.
هناك أيضًا تصور بأن المساحة الموجودة على البلورات في رقائق الرسومات سيتم إنفاقها بشكل أفضل على نوى تظليل إضافية - وهذا ما فعلته Nvidia عند إنشاء إصدارات الميزانية من رقائق Turing الخاصة بها. في منتجات مثل GeForce GTX 1650 ، تخلصت الشركة تمامًا من أنوية التنسور واستبدلتهم بمظلات FP16 إضافية.
ولكن في الوقت الحالي ، إذا كنت ترغب في توفير معالجة GEMM فائقة السرعة والاستفادة الكاملة منها ، فلديك خياران: شراء مجموعة ضخمة من وحدات المعالجة المركزية متعددة النواة أو وحدة معالجة رسومات واحدة فقط مع نوى موتر.
أنظر أيضا: