يمكنك القيام بذلك يدويًا ، ولكن هناك أيضًا أطر عمل ومكتبات لذلك تجعل هذه العملية أسرع وأسهل. سنتحدث
عن واحد منهم ، الأدوات المميزة ، بالإضافة إلى التجربة العملية لاستخدامه.

خط الأنابيب الأكثر عصرية
مرحبا! أنا ألكسندر لوسكوتوف ، أعمل في Leroy Merlin كمحلل بيانات ، أو ، كما هو معروف الآن ، عالم بيانات. تشمل مسؤولياتي العمل مع البيانات ، بدءًا من الاستعلامات التحليلية والتفريغ ، وانتهاءً بتدريب النموذج ، ولفه ، على سبيل المثال ، في خدمة ، وإعداد تسليم ونشر الكود ، ومراقبة عمله.
التراجع عن التنبؤ هو أحد المنتجات التي أعمل عليها.
هدف المنتج: توقع احتمال قيام العميل بإلغاء طلب عبر الإنترنت. بمساعدة مثل هذا التوقع ، يمكننا تحديد العملاء الذين قدموا طلبًا يجب الاتصال به أولاً لطلب تأكيد الطلب ، ومن قد لا يتم الاتصال بهم على الإطلاق. أولاً ، حقيقة الاتصال وتأكيد الطلب من العميل عبر الهاتف يقلل من احتمالية الإلغاء ، وثانيًا ، إذا اتصلنا ورفض الشخص ، فيمكننا توفير الموارد. سيتم توفير المزيد من الوقت للموظفين ، والذي كانوا سيقضونه في تحصيل الطلب. بالإضافة إلى ذلك ، بهذه الطريقة سيبقى المنتج على الرف ، وإذا احتاجه العميل في المتجر في تلك اللحظة ، فسيكون قادرًا على شرائه. وهذا سيقلل من عدد البضائع التي تم جمعها في أوامر تم إلغاؤها لاحقًا ولم تكن موجودة على الرفوف.
الرواد
بالنسبة إلى المنتج التجريبي ، لا نتلقى سوى الطلبات المدفوعة لاحقًا لاستلامها في متاجر متعددة.
يعمل الحل الجاهز على النحو التالي: يأتي إلينا طلب ، بمساعدة Apache NiFi ، نقوم بإثراء المعلومات المتعلقة به - على سبيل المثال ، سحب البيانات عن البضائع. ثم يتم نقل كل هذا من خلال وسيط رسائل Apache Kafka إلى الخدمة المكتوبة بلغة Python. تحسب الخدمة ميزات الطلب ، ثم يتم أخذ نموذج التعلم الآلي لها ، مما يعطي احتمالية الإلغاء. بعد ذلك ، وفقًا لمنطق العمل ، نقوم بإعداد إجابة عما إذا كنت بحاجة إلى الاتصال بالعميل الآن أم لا (على سبيل المثال ، إذا تم إجراء الطلب بمساعدة موظف داخل المتجر أو تم إجراء الطلب ليلاً ، فلا يجب عليك الاتصال).
يبدو ، ما الذي يمنع الجميع من الاتصال؟ الحقيقة هي أن لدينا عددًا محدودًا من الموارد للمكالمات ، لذلك من المهم أن نفهم من الذي يجب أن يتصل به بالتأكيد ، ومن سيتلقى طلباته دون الاتصال.
تطوير نموذج
لقد شاركت في الخدمة ، والنموذج ، وبالتالي حساب ميزات النموذج ، والتي ستتم مناقشتها بشكل أكبر.
عند حساب الميزات أثناء التدريب ، نستخدم ثلاثة مصادر بيانات.
- لوحة تحتوي على معلومات وصفية للطلب: رقم الطلب ، الطابع الزمني ، جهاز العميل ، طريقة التسليم ، طريقة الدفع.
- لوحة تحتوي على مراكز في الإيصالات: رقم الطلب ، والسلعة ، والسعر ، والكمية ، وكمية البضائع في المخزون. يذهب كل موقف في سطر منفصل.
- الجدول - كتاب مرجعي للسلع: مقال ، عدة حقول مع فئة من السلع ، وحدات قياس ، وصف.
باستخدام طرق Python القياسية ومكتبة الباندا ، يمكنك بسهولة دمج جميع الجداول في واحدة كبيرة ، وبعد ذلك ، باستخدام groupby ، يمكنك حساب جميع أنواع الميزات مثل التجميعات حسب الترتيب ، والتاريخ حسب المنتج ، وفئة المنتج ، وما إلى ذلك. ولكن هناك العديد من المشاكل هنا.
- موازاة الحسابات. تعمل المجموعة القياسية في خيط واحد ، وعلى البيانات الضخمة (حتى 10 ملايين صف) ، تعتبر مائة ميزة طويلة بشكل غير مقبول ، في حين أن سعة النوى المتبقية معطلة.
- مقدار الكود: يجب كتابة كل طلب بشكل منفصل ، والتحقق من صحته ، ومن ثم لا تزال هناك حاجة لجمع جميع النتائج. يستغرق هذا وقتًا ، خاصةً بالنظر إلى تعقيد بعض العمليات الحسابية - على سبيل المثال ، حساب أحدث محفوظات عنصر في إيصال وتجميع هذه الخصائص لأمر.
- يمكنك ارتكاب الأخطاء إذا قمت بترميز كل شيء يدويًا.
ميزة نهج "نكتب كل شيء يدويًا" هي ، بالطبع ، الحرية الكاملة في العمل ، يمكنك منح خيالك لتتكشف.
السؤال الذي يطرح نفسه: كيف يمكن تحسين هذا الجزء من العمل. أحد الحلول هو استخدام مكتبة الميزات .
نحن هنا ننتقل بالفعل إلى جوهر هذه المقالة ، أي إلى المكتبة نفسها وممارسة استخدامها.
لماذا الميزات؟
دعنا نفكر في العديد من الأطر للتعلم الآلي على شكل لوحة (الصورة نفسها مسروقة بصراحة من هنا ، وربما لم يتم الإشارة إلى جميعها هناك ، ولكن لا يزال):
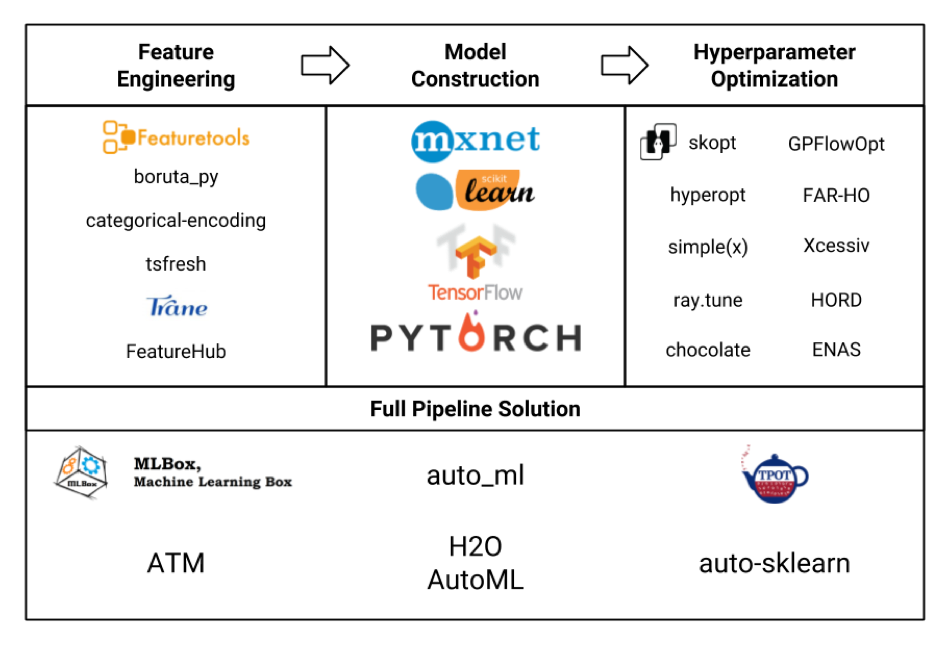
نحن مهتمون بشكل أساسي بمجموعة هندسة الميزات. إذا نظرنا إلى كل هذه الأطر والحزم ، اتضح أن أدوات الميزات هي الأكثر تعقيدًا ، بل إنها تتضمن وظائف بعض المكتبات الأخرى مثل tsfresh .
تشمل أيضًا مزايا الأدوات المميزة (وليس الإعلان على الإطلاق!):
- حوسبة موازية خارج الصندوق
- توافر العديد من الميزات خارج منطقة الجزاء
- المرونة في التخصيص - يمكن النظر في أشياء معقدة للغاية
- محاسبة العلاقات بين الجداول المختلفة (علائقية)
- رمز أقل
- أقل احتمالا لارتكاب خطأ
- في حد ذاته ، كل شيء مجاني ، بدون تسجيل ورسائل SMS (ولكن مع pypi)
لكن الأمر ليس بهذه البساطة.
- يتطلب إطار العمل بعض التعلم ، وسيستغرق إتقان كامل وقتًا مناسبًا.
- ليس لديها مثل هذا المجتمع الكبير ، على الرغم من أن الأسئلة الأكثر شيوعًا لا تزال تبحث في Google جيدًا.
- يتطلب الاستخدام نفسه أيضًا عناية حتى لا تضخم مساحة الميزة دون داع ولا تزيد من وقت الحساب.
تدريب
سأقدم مثالاً على تكوين الأدوات المميزة.
بعد ذلك ، سيكون هناك رمز يحتوي على تفسيرات موجزة ، بمزيد من التفاصيل حول أدوات الميزات ، وفئاتها ، وطرقها ، وإمكانياتها ، يمكنك قراءتها ، من بين أشياء أخرى ، في الوثائق الموجودة على موقع ويب الإطار. إذا كنت مهتمًا بأمثلة للتطبيق العملي مع عرض توضيحي لبعض الاحتمالات المثيرة للاهتمام في مهام حقيقية ، فاكتب في التعليقات ، ربما سأقوم بتدوين مقال منفصل.
وبالتالي.
أولاً ، تحتاج إلى إنشاء كائن من فئة EntitySet ، والذي يحتوي على جداول بها بيانات ويعرف علاقتها ببعضها البعض.
دعني أذكرك بأن لدينا ثلاثة جداول بالبيانات:
- Orders_meta (معلومات تعريف الطلب)
- Orders_items_lists (معلومات حول العناصر في الطلبات)
- العناصر (مرجع المقالات وخصائصها)
نكتب (علاوة على ذلك ، يتم استخدام بيانات 3 متاجر فقط):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

الصيحة! الآن لدينا كائن يسمح لنا بعد كل أنواع العلامات.
سأقدم رمزًا لحساب ميزات بسيطة إلى حد ما: لكل طلب ، سنقوم بحساب إحصائيات مختلفة عن أسعار وكمية البضائع ، بالإضافة إلى بعض الميزات حسب الوقت والمنتجات وفئات السلع الأكثر شيوعًا في الترتيب (تسمى الوظائف التي تؤدي عمليات تحويل مختلفة بالبيانات بالأوليات في أدوات الميزات) ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)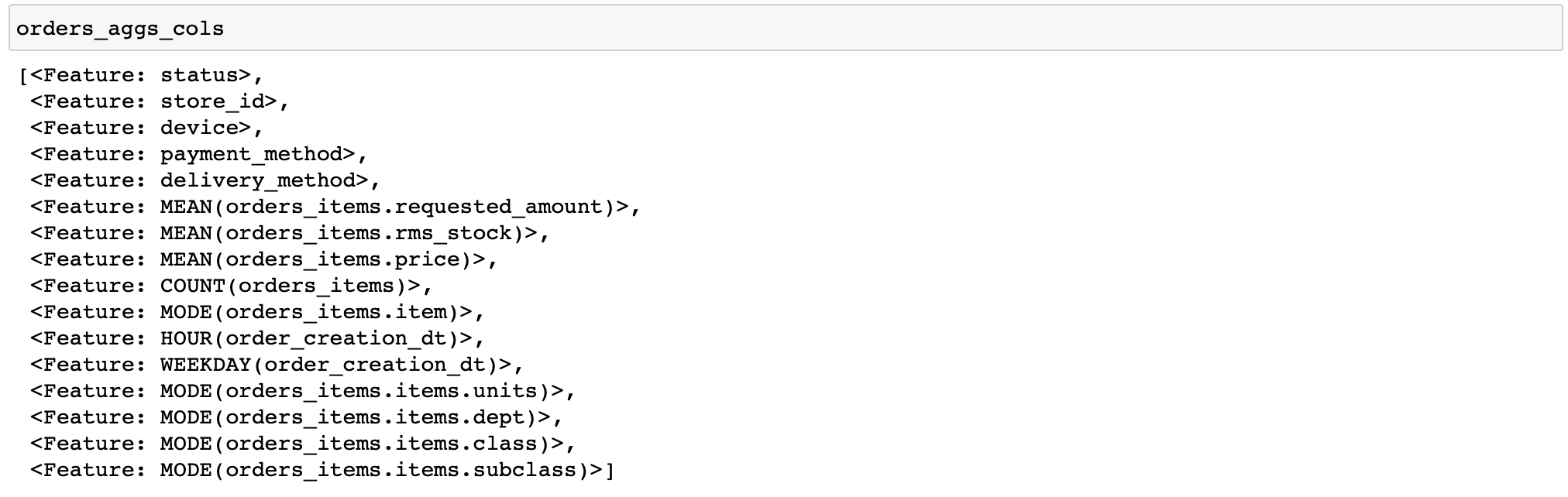

لا توجد أعمدة منطقية في الجداول هنا ، لذلك لم يتم تطبيق أي أعمدة أولية. بشكل عام ، من الملائم أن تقوم أداة الميزات نفسها بتحليل نوع البيانات وتطبيق الوظائف المناسبة فقط.
أيضًا ، قمت يدويًا بتحديد عدد قليل فقط من الطلبات للحساب. يتيح لك ذلك تصحيح أخطاء حساباتك بسرعة (ماذا لو قمت بتكوين خطأ ما).
دعنا الآن نضيف عددًا قليلاً من المجاميع الإضافية إلى ميزاتنا ، وهي النسب المئوية. لكن الأدوات المميزة لا تحتوي على عناصر أولية مضمنة لحسابها. لذلك عليك أن تكتبها بنفسك.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
وأضفهم للحساب:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)ثم كل شيء هو نفسه. حتى الآن ، كل شيء بسيط جدًا وسهل (نسبيًا ، بالطبع).
ولكن ماذا لو أردنا حفظ حاسبة الميزات الخاصة بنا واستخدامها في مرحلة تنفيذ النموذج ، أي في الخدمة؟
الميزات في القتال
من هنا تبدأ الصعوبات الرئيسية.
لحساب الخصائص لأمر وارد ، سيتعين عليك القيام بجميع العمليات مع إنشاء EntitySet مرة أخرى. وإذا كانت كائنات DataFrame في EntitySet للجداول الكبيرة تبدو طبيعية تمامًا ، فإن إجراء عمليات مماثلة لـ DataFrames من صف واحد (يوجد المزيد منها في الجدول مع الشيكات ، ولكن في المتوسط 3.3 موضع لكل شيك ، وهذا غير كافٍ) - ليس كثيرا. بعد كل شيء ، فإن إنشاء مثل هذه الكائنات والحسابات بمساعدتها يحتوي حتماً على مقدار عام ، أي عدد غير قابل للإزالة من العمليات الضرورية ، على سبيل المثال ، لتخصيص الذاكرة وتهيئتها عند إنشاء كائن من أي حجم أو عملية الموازاة نفسها عند حساب العديد من الميزات في وقت واحد.
لذلك ، في وضع التشغيل "طلب واحد في كل مرة" في أدواتنا المميزة لمنتجنا لا يظهر أفضل كفاءة ، حيث يأخذ في المتوسط 75٪ من وقت استجابة الخدمة (في المتوسط 150-200 مللي ثانية ، اعتمادًا على الأجهزة). للمقارنة: حساب التنبؤ باستخدام catboost على الميزات الجاهزة يستغرق 3٪ من وقت استجابة الخدمة ، أي ما لا يزيد عن 10 مللي ثانية.
بالإضافة إلى ذلك ، هناك مأزق آخر مرتبط باستخدام العناصر الأولية المخصصة. الحقيقة هي أنه لا يمكننا ببساطة حفظ كائن من الفئة التي تحتوي على الأوليات التي أنشأناها في مخلل ، لأن هذا الأخير ليس مخللًا.
ثم لماذا لا تستخدم وظيفة save_features () المضمنة ، والتي يمكنها حفظ قائمة كائنات FeatureBase ، بما في ذلك العناصر الأولية التي أنشأناها؟
سيحفظها ، لكن لن يكون من الممكن قراءتها لاحقًا باستخدام وظيفة load_features () إذا لم نقم بإنشائها مرة أخرى مسبقًا. أي ، الأوليات التي ، نظريًا ، يجب أن نقرأها من القرص ، نخلقها أولاً مرة أخرى ، حتى لا نستخدمها مرة أخرى أبدًا.
تبدو هكذا:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorفي دالة load () ، يجب عليك إنشاء العناصر الأولية (التي تعلن عن المتغير custom_primitives) التي لن يتم استخدامها. ولكن بدون ذلك ، ستفشل ميزة التحميل الإضافي في المكان الذي تُسمى فيه وظيفة load_features () مع عدم وجود خطأ RuntimeError: Primitive "percentile05" في الوحدة النمطية "featuretools.primitives.base.aggregation_primitive_base" غير موجود .
اتضح أنه ليس منطقيًا للغاية ، ولكنه يعمل ، ويمكنك حفظ كل من الآلة الحاسبة المرتبطة بالفعل بتنسيق بيانات معين (نظرًا لأن الميزات مرتبطة بمجموعة EntitySet التي تم حسابها من أجلها ، وإن لم يكن ذلك بدون القيم نفسها) ، والآلة الحاسبة فقط بقائمة معينة من العناصر الأولية.
ربما سيتم تصحيح هذا في المستقبل وسيكون من الممكن حفظ مجموعة عشوائية من كائنات FeatureBase بشكل ملائم.
لماذا إذن نستخدمها؟
لأنه من وجهة نظر وقت التطوير ، فهو رخيص ، في حين أن وقت الاستجابة تحت الحمل الحالي يتناسب مع اتفاقية مستوى الخدمة (5 ثوانٍ) بهامش.
ومع ذلك ، يجب أن تدرك أنه بالنسبة للخدمة التي يجب أن تستجيب بسرعة للطلبات التي يتم تلقيها بشكل متكرر ، فإن استخدام أدوات مميزة بدون "استقراءات" إضافية مثل المكالمات غير المتزامنة سيكون مشكلة.
هذه هي تجربتنا في استخدام الأدوات المميزة في مرحلتي التعلم والاستدلال.
هذا الإطار جيد جدًا كأداة لحساب عدد كبير من ميزات التدريب بسرعة ، فهو يقلل بشكل كبير من وقت التطوير ويقلل من احتمالية الأخطاء.
يعتمد ما إذا كنت ستستخدمه في مرحلة الانسحاب على مهامك.