
ليس من السهل حل مشاكل علم البيانات في بايثون
لماذا ا؟ الأدوات الحالية غير مناسبة بشكل جيد لحل المشكلات المتعلقة بالسلاسل الزمنية ، ومن الصعب دمج هذه الأدوات مع بعضها البعض. تفترض أساليب Scikit-Learn أن البيانات منظمة في تنسيق جدولي وأن كل عمود يتكون من متغيرات عشوائية مستقلة وموزعة بالتساوي - افتراضات لا علاقة لها ببيانات السلاسل الزمنية. الحزم التي تحتوي على وحدات للتعلم الآلي والعمل مع السلاسل الزمنية ، مثل statsmodels ، ليست صديقة جيدة لبعضها البعض. علاوة على ذلك ، فإن العديد من العمليات المهمة ذات السلاسل الزمنية ، مثل تقسيم البيانات إلى مجموعات تدريب واختبار على فترات زمنية ، غير متوفرة في الحزم الحالية.
لحل مشاكل مماثلة ، تم إنشاء sktime .

شعار مكتبة Sktime على GitHub
Sktime عبارة عن مجموعة أدوات مفتوحة المصدر للتعلم الآلي في Python مصممة خصيصًا للعمل مع السلاسل الزمنية. هذا المشروع هو المجتمع المتقدم والممول من قبل البريطانيين المجلس الاقتصادي والبحوث الاجتماعية ، بحوث بيانات المستهلك و معهد تورنج آلان .
يقوم Sktime بتوسيع واجهة برمجة تطبيقات scikit-Learn لحل مشاكل السلاسل الزمنية. يحتوي على جميع الخوارزميات وأدوات التحويل اللازمة لحل مشاكل انحدار السلاسل الزمنية والتنبؤ والتصنيف بكفاءة. تتضمن المكتبة خوارزميات خاصة للتعلم الآلي وطرق تحويل للسلسلة الزمنية غير الموجودة في المكتبات الشعبية الأخرى.
تم تصميم Sktime للعمل مع scikit-Learn ، وتكييف الخوارزميات بسهولة مع مشاكل السلاسل الزمنية المترابطة ، وبناء نماذج معقدة. كيف تعمل؟ ترتبط العديد من مشاكل السلاسل الزمنية ببعضها البعض بطريقة أو بأخرى. غالبًا ما يمكن تطبيق خوارزمية يمكن استخدامها لحل مشكلة ما لحل مشكلة أخرى متعلقة بها. هذه الفكرة تسمى الاختزال. على سبيل المثال ، يمكن إعادة استخدام نموذج لانحدار السلاسل الزمنية (الذي يستخدم سلسلة للتنبؤ بقيمة المخرجات) لمشكلة توقع السلاسل الزمنية (التي تتنبأ بقيمة الإخراج - وهي القيمة التي سيتم تلقيها في المستقبل).
الفكرة الرئيسية للمشروع:"يوفر Sktime تعلمًا آليًا سهل الفهم وقابل للتكامل باستخدام السلاسل الزمنية. يحتوي على خوارزميات متوافقة مع أدوات تبادل النماذج والنماذج scikit-learn ، مدعومة بتصنيف واضح لمهام التعلم ، وتوثيق واضح ، ومجتمع ودود. "
في هذه المقالة ، سوف أسلط الضوء على بعض الميزات الفريدة لـ sktime .
نموذج البيانات الصحيح للسلاسل الزمنية
يستخدم Sktime بنية بيانات متداخلة للسلاسل الزمنية في شكل إطارات بيانات الباندا .
يحتوي كل سطر في إطار بيانات نموذجي على متغيرات عشوائية مستقلة ومتساوية التوزيع - الحالات والأعمدة - متغيرات مختلفة. بالنسبة إلى طرق sktime ، يمكن أن تحتوي كل خلية في إطار بيانات Pandas الآن على سلسلة زمنية كاملة. هذا التنسيق مرن للبيانات متعددة الأبعاد واللوحية وغير المتجانسة ، ويسمح بإعادة استخدام الأسلوب في كل من Pandas و scikit-Learn .
في الجدول أدناه ، كل صف عبارة عن ملاحظة تحتوي على مجموعة من السلاسل الزمنية في العمود X وقيمة فئة في العمود Y. مقيّمو ومحولات sktime بارعون في العمل مع هذه السلاسل الزمنية.
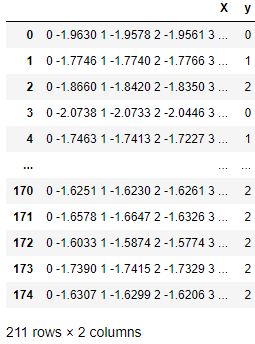
هيكل بيانات متسلسل زمني أصلي متوافق مع sktime.
في الجدول التالي ، تم نقل كل عنصر من عناصر السلسلة X إلى عمود منفصل كما هو مطلوب بواسطة طرق scikit-Learn. البعد مرتفع جدًا - 251 عمودًا! بالإضافة إلى ذلك ، يتم تجاهل الترتيب الزمني للأعمدة من خلال خوارزميات التعلم التي تعمل مع القيم المجدولة (ولكنها تستخدم في تصنيف السلاسل الزمنية وخوارزميات الانحدار).
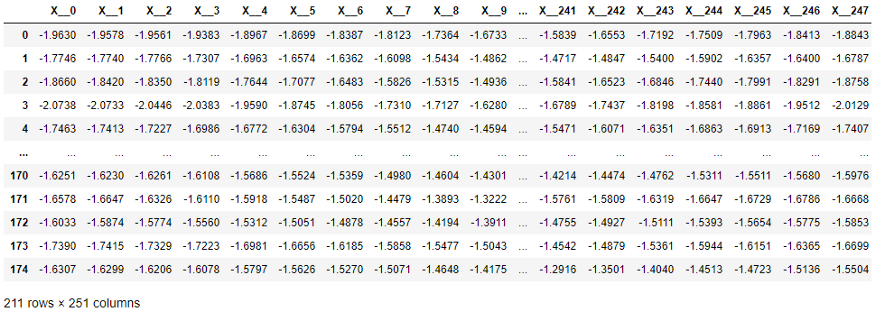
هيكل بيانات السلاسل الزمنية المطلوبة بواسطة scikit-Learn.
بالنسبة لمهام النمذجة للعديد من السلاسل المشتركة ، يعد هيكل بيانات السلاسل الزمنية الأصلية المتوافق مع sktime مثاليًا. النماذج المدربة على البيانات المجدولة المتوقعة من قبل scikit-Learn سوف تتعثر في الكثير من الميزات.
ماذا يمكن أن يفعل سكايم ؟
وفقًا لصفحة GitHub ، يوفر sktime حاليًا الإمكانات التالية:
- الخوارزميات الحديثة لتصنيف السلاسل الزمنية وتحليل الانحدار والتنبؤ (تم نقلها من مجموعة الأدوات
tsmlإلى Java) ؛ - محولات السلاسل الزمنية: تحويلات السلاسل المفردة (على سبيل المثال ، التراجع أو إزالة التفاوت) ، وتحولات السلاسل كميزات (على سبيل المثال ، استخراج الميزات) ، وأدوات لمشاركة محولات متعددة.
- خطوط الأنابيب للمحولات والنماذج.
- إعداد النموذج ؛
- مجموعة من النماذج ، على سبيل المثال ، الغابة العشوائية القابلة للتخصيص بالكامل لتصنيف وانحدار السلاسل الزمنية ، ومجموعة المشكلات متعددة الأبعاد.
API سكايم
كما ذكر آنفا، sktime يدعم API الأساسي scikit-تعلم طرق لالطبقات
fit، predictو transform.
بالنسبة لفئات التقييم (أو النماذج) ، يوفر sktime طريقة
fitلتدريب النموذج وطريقة predictلإنشاء تنبؤات جديدة.
يقوم المقيمون في sktime بتوسيع المتغيرات المشتركة والمصنفات scikit-Learn ، مما يوفر نظائر لهذه الأساليب ، والتي تكون قادرة على العمل مع السلاسل الزمنية.
لفئات sktime يوفر محول الطرق
fitو transformلتحويل البيانات السلسلة. هناك عدة أنواع من التحويلات المتاحة:
- , , ;
- , (, );
- (, );
- , , , (, ).
المثال التالي هو تعديل دليل التنبؤ من GitHub . توضح السلسلة في هذا المثال (مجموعة بيانات خطوط الطيران Box-Jenkins) عدد ركاب الطائرات الدولية شهريًا من عام 1949 إلى عام 1960.
أولاً ، قم بتحميل البيانات وقسمها إلى مجموعات تدريب واختبار ، وقم بعمل رسم بياني. في sktime ميزتان مناسبتان لسهولة تنفيذ هذه المهام -
temporal_train_test_splitforمفصولة بمجموعة من البيانات والوقت plot_ys، تم رسمها على أساس الاختبار وعينة التدريب.
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])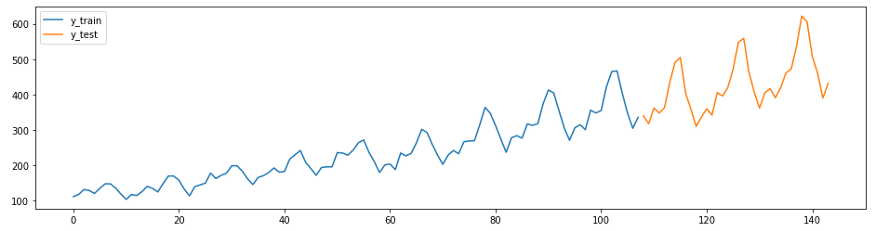
قبل إجراء تنبؤات معقدة ، من المفيد مقارنة توقعاتك بالقيم التي تم الحصول عليها باستخدام خوارزميات بايز الساذجة. يجب أن يتجاوز النموذج الجيد هذه القيم. في sktime ، لديك طريقة
NaiveForecasterذات استراتيجيات مختلفة لإنشاء توقعات أساسية.
يظهر الرمز والرسم البياني أدناه تنبؤين ساذجين. سيتنبأ المتنبئ c
strategy = “last”دائمًا بالقيمة الأخيرة للسلسلة. تتوقع
Forecaster s
strategy = “seasonal_last”القيمة الأخيرة للمسلسل للموسم المحدد. تم تعيين الموسمية في المثال “sp=12”، أي 12 شهرًا.
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957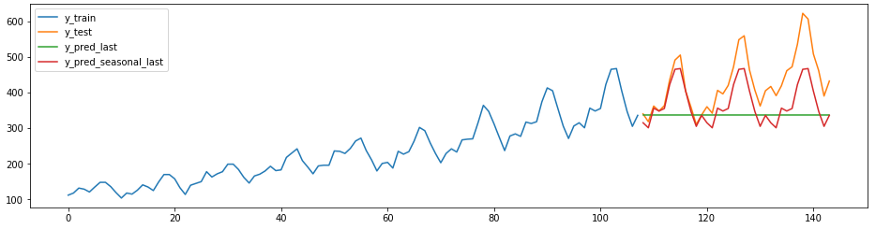
يوضح مقتطف التنبؤ التالي كيف يمكن أن تكون عوامل الارتداد الموجودة في sklearn سهلة وصحيحة وبأقل جهد ممكن لتكييفها مع مهام التنبؤ. يوجد أدناه طريقة
ReducedRegressionForecasterمن sktime تتنبأ بسلسلة باستخدام نموذج sklearnRandomForestRegressor. تحت غطاء المحرك ، يقسم sktime بيانات التدريب إلى نوافذ 12 بحيث يمكن للرجوع مواصلة التدريب.
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)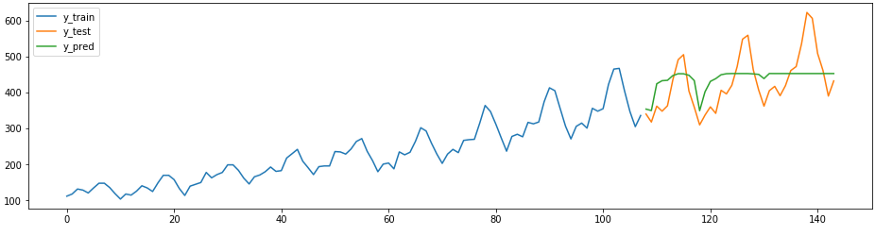
في sktime أيضًا طرق التنبؤ الخاصة بهم ، على سبيل المثال
AutoArima.
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469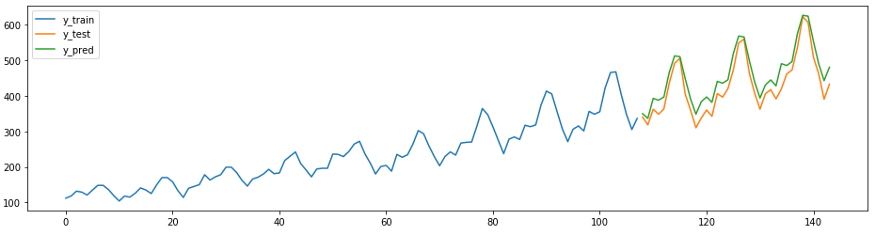
للتعمق أكثر في وظائف التنبؤ بـ sktime ، راجع البرنامج التعليمي هنا .
تصنيف السلاسل الزمنية
sktimeيمكن استخدامه
أيضًا لتصنيف السلاسل الزمنية إلى مجموعات مختلفة.
في مثال الكود أدناه ، أصبح تصنيف السلاسل الزمنية المفردة سهلاً مثل التصنيف في scikit-Learn. الاختلاف الوحيد هو بنية بيانات السلاسل الزمنية المتداخلة التي تحدثنا عنها أعلاه.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868وقد اتخذ هذا المثال من pypi.org/project/sktime
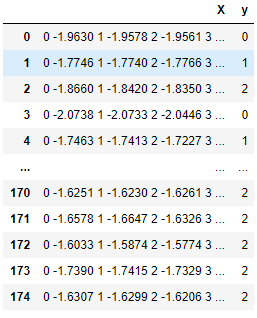
مرت البيانات إلى TimeSeriesForestClassifier
لمعرفة المزيد عن تصنيف سلسلة، انظر sktime الصورة أحادي المتغير و متعددة الأبعاد تصنيف الدروس .
موارد إضافية لـ sktime
لمعرفة المزيد حول Sktime ، راجع الروابط التالية للوثائق والأمثلة.
- وصف مفصل لواجهة برمجة التطبيقات: sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .