في X5 ، يُطلق على النظام الذي سيتعقب السلع المصنفة ويتبادل البيانات مع الحكومة والموردين "Markus". دعونا نرتب كيف وكيف قام بتطويرها ، ما هو نوع المكدس التكنولوجي لديها ولماذا لدينا شيء نفخر به.
تحميل عالي حقيقي
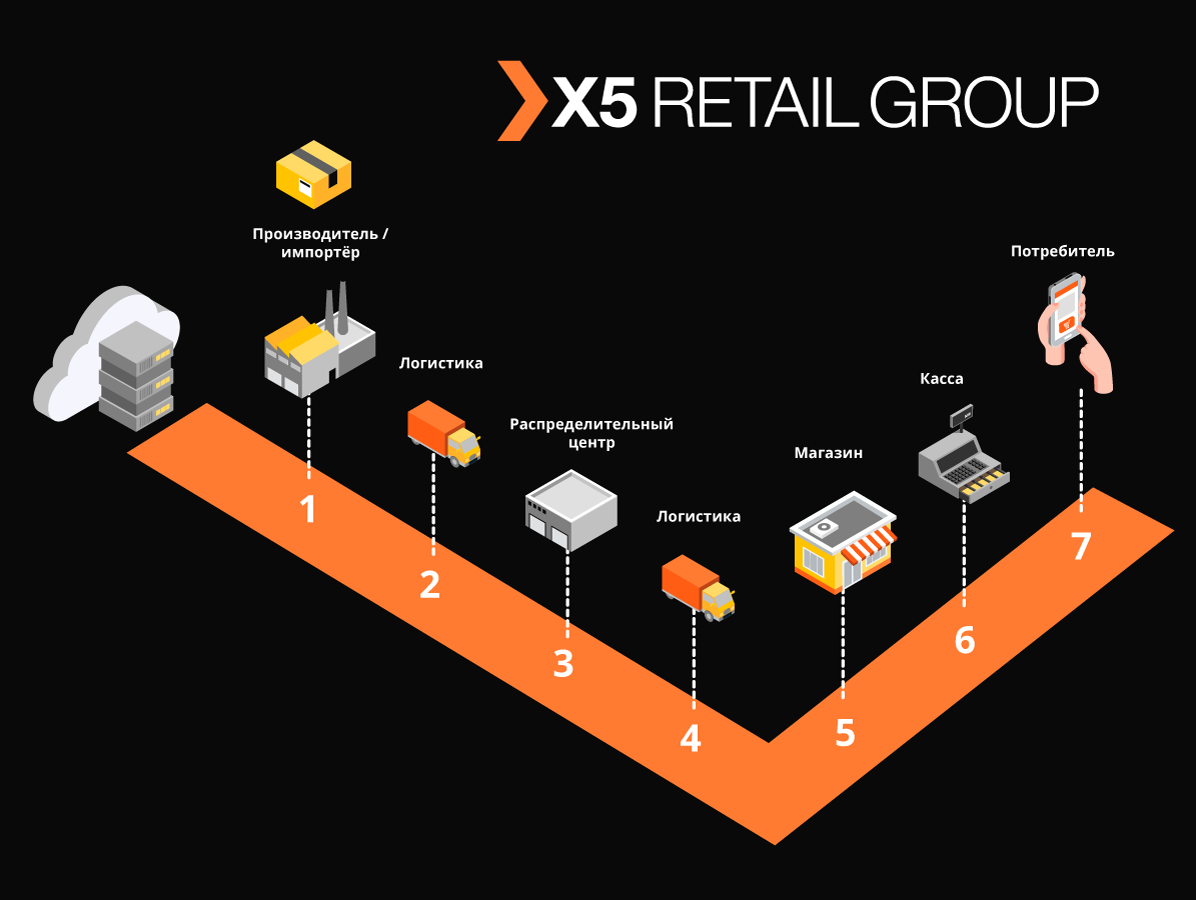
يحل "Markus" العديد من المشكلات ، أهمها تفاعل التكامل بين أنظمة المعلومات X5 ونظام معلومات الحالة للمنتجات ذات العلامات (GIS MP) لتتبع حركة المنتجات التي تحمل علامات. تقوم المنصة أيضًا بتخزين جميع أكواد وضع العلامات التي نتلقاها كما أن التاريخ الكامل لحركة هذه الرموز عبر الكائنات ، يساعد في القضاء على إعادة فرز المنتجات المميزة. على سبيل المثال منتجات التبغ ، التي تم تضمينها في المجموعات الأولى من السلع المعنونة ، تحتوي شاحنة واحدة فقط من السجائر على حوالي 600000 عبوة ، لكل منها رمزها الفريد. وتتمثل مهمة نظامنا في تتبع والتحقق من قانونية حركات كل حزمة من هذا القبيل بين المستودعات والمخازن ، والتحقق في النهاية من مقبولية تنفيذها للعميل النهائي. ونسجل المعاملات النقدية حوالي 125000 في الساعة ،ومن الضروري أيضًا تسجيل كيفية دخول كل حزمة من هذه المنتجات في المتجر. وبالتالي ، مع الأخذ في الاعتبار جميع التحركات بين الكائنات ، نتوقع عشرات المليارات من السجلات سنويًا.
فريق م
على الرغم من حقيقة أن "Markus" يعتبر مشروعًا ضمن X5 ، إلا أنه يتم تنفيذه وفقًا لمنهج المنتج. يعمل الفريق على سكروم. كان بداية المشروع في الصيف الماضي ، ولكن النتائج الأولى جاءت فقط في أكتوبر - تم تجميع فريقهم بالكامل ، وتم تطوير بنية النظام وتم شراء المعدات. يضم الفريق الآن 16 شخصًا ، ستة منهم يعملون في تطوير الواجهة الأمامية والخلفية ، وثلاثة في تحليل النظام. يشارك ستة أشخاص آخرين في الاختبار اليدوي والتحميل والاختبار الآلي ودعم المنتج. بالإضافة إلى ذلك ، لدينا متخصص SRE.
لا تتم كتابة التعليمات البرمجية في فريقنا من قبل المطورين فقط ، ولكن جميع اللاعبين تقريبًا يعرفون كيفية برمجة وكتابة الاختبارات التلقائية وتحميل البرامج النصية ونصوص الأتمتة. نولي اهتمامًا خاصًا لذلك ، نظرًا لأن دعم المنتج يتطلب مستوى عاليًا من الأتمتة. نحاول دائمًا تقديم المشورة ومساعدة زملائنا الذين لم يبرمجوا من قبل ، لإعطاء بعض المهام الصغيرة للعمل.
فيما يتعلق بوباء الفيروس التاجي ، قمنا بنقل الفريق بأكمله إلى العمل عن بُعد ، وتوافر جميع أدوات إدارة التطوير ، وسهل سير العمل المدمج في Jira و GitLab من المرور بهذه المرحلة. أظهرت الأشهر التي قضاها في مكان بعيد أن إنتاجية الفريق لم تعاني من هذا ، لأن الكثير من الراحة في العمل زادت ، الشيء الوحيد هو أنه لا يوجد ما يكفي من التواصل المباشر.
اجتماع الفريق قبل المسافة

اجتماعات عن بعد
مكدس تكنولوجيا الحل
المستودع القياسي وأداة CI / CD لـ X5 هو GitLab. نستخدمها لتخزين التعليمات البرمجية ، الاختبار المستمر ، النشر لخوادم الإنتاج والإنتاج. نستخدم أيضًا ممارسة مراجعة الكود ، عندما يحتاج زميلان على الأقل إلى الموافقة على التغييرات التي أجراها المطور على الكود. تساعدنا أدوات تحليل الشفرة الثابتة SonarQube و JaCoCo في الحفاظ على نظافة الشفرة وتوفير المستوى المطلوب من تغطية اختبار الوحدة. يجب أن تخضع جميع التغييرات في الرمز لهذه الاختبارات. يتم تلقائيًا تشغيل جميع البرامج النصية للاختبار التي يتم تشغيلها يدويًا.
من أجل التنفيذ الناجح للعمليات التجارية من قبل "ماركوس" كان علينا حل عدد من المشاكل التكنولوجية ، كل في الترتيب.
المهمة 1. الحاجة إلى قابلية التوسع الأفقية للنظام
لحل هذه المشكلة ، اخترنا نهج الخدمات الصغيرة للهندسة المعمارية. في نفس الوقت ، كان من المهم للغاية فهم مجالات مسؤولية الخدمات. حاولنا تقسيمها إلى عمليات تجارية ، مع مراعاة تفاصيل العمليات. على سبيل المثال ، لا يعد القبول في أحد المستودعات أمرًا متكررًا جدًا ، ولكنه عملية ضخمة جدًا ، حيث من الضروري الحصول عليها من الجهة المنظمة للولاية بأسرع ما يمكن من المعلومات حول وحدات السلع المقبولة ، والتي يصل عددها في تسليم واحد إلى 600000 ، وتحقق من مقبولية قبول هذا المنتج إلى المستودع وإعطاء جميع المعلومات اللازمة لنظام أتمتة المستودعات. لكن الشحن من المستودعات له كثافة أعلى بكثير ، ولكن في نفس الوقت يعمل بكميات صغيرة من البيانات.
ننفذ جميع الخدمات على أساس مبدأ انعدام الجنسية وحتى نحاول تقسيم العمليات الداخلية إلى خطوات ، باستخدام ما نسميه موضوعات كافكا الذاتية. يحدث ذلك عندما ترسل الخدمة المصغرة رسالة إلى نفسها ، مما يسمح بموازنة الحمل لعمليات أكثر استفادة من الموارد وتبسيط صيانة المنتج ، ولكن أكثر من ذلك لاحقًا.
قررنا فصل الوحدات للتفاعل مع الأنظمة الخارجية في خدمات منفصلة. وقد جعل هذا من الممكن حل مشكلة واجهات برمجة التطبيقات (APIs) المتغيرة بشكل متكرر للأنظمة الخارجية ، دون أي تأثير عمليًا على الخدمات ذات وظائف الأعمال.
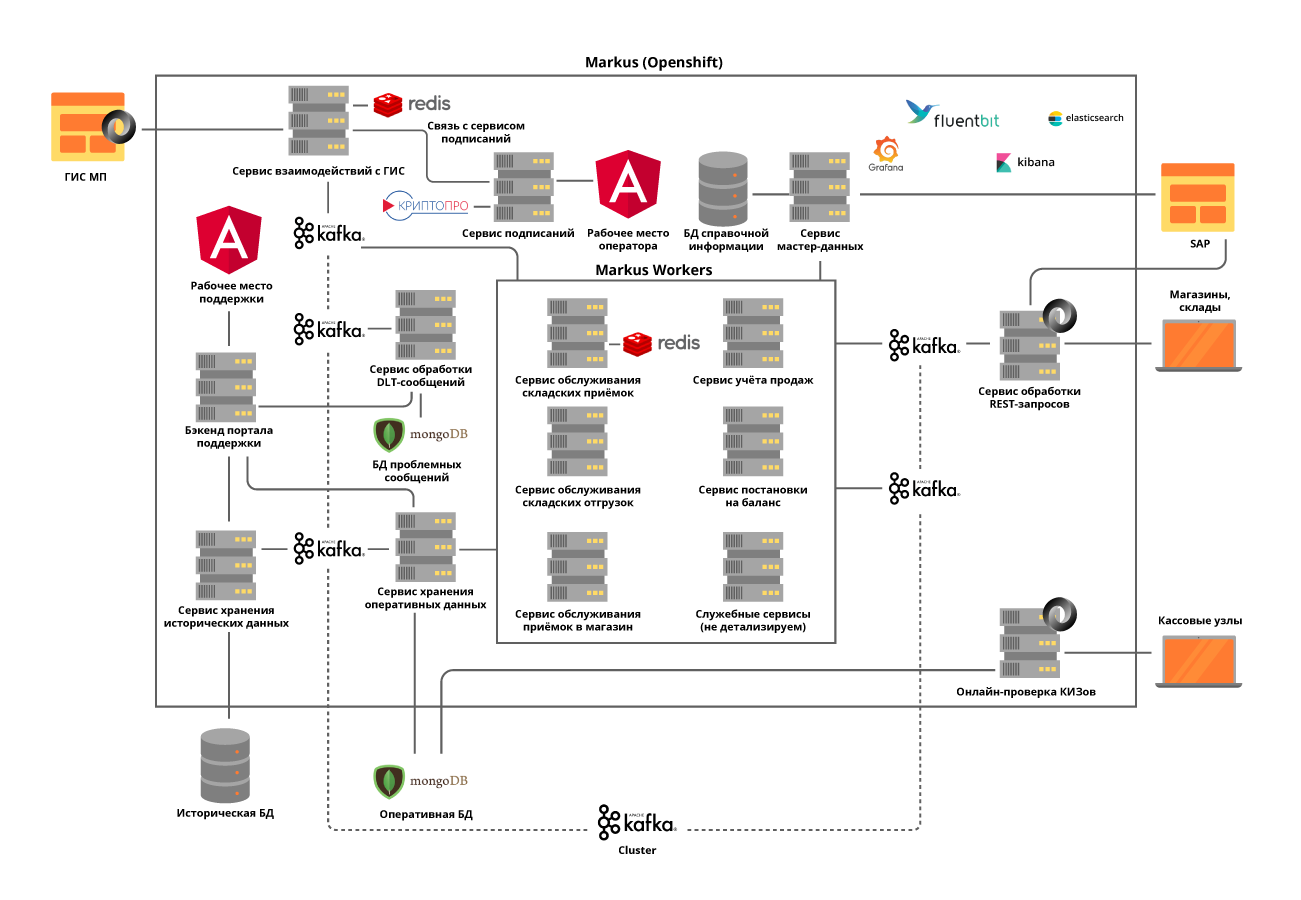
يتم نشر جميع الخدمات الصغيرة في مجموعة OpenShift ، والتي تعمل على حل مشكلة تغيير حجم كل خدمة صغيرة وتتيح لنا عدم استخدام أدوات اكتشاف الخدمة التابعة لجهة خارجية.
المهمة 2. الحاجة إلى الحفاظ على حمولة عالية وتبادل بيانات مكثف للغاية بين خدمات النظام الأساسي: فقط في مرحلة إطلاق المشروع ، يتم تنفيذ حوالي 600 عملية في الثانية. نتوقع أن تزيد هذه القيمة حتى 5000 عملية في الثانية عند اتصال كائنات التداول بمنصتنا.
تم حل هذه المهمة من خلال نشر مجموعة كافكا والتخلي تمامًا عن الاتصال المتزامن بين الخدمات الدقيقة للمنصة. يتطلب هذا تحليلًا دقيقًا للغاية لمتطلبات النظام ، حيث لا يمكن أن تكون جميع العمليات غير متزامنة. في الوقت نفسه ، نحن لا ننقل الأحداث فقط من خلال الوسيط ، ولكن أيضًا ننقل جميع المعلومات التجارية المطلوبة في الرسالة. وبالتالي ، يمكن أن يصل حجم الرسالة إلى عدة مئات من الكيلوبايت. يتطلب تحديد حجم الرسائل في كافكا أن نتنبأ بدقة حجم الرسائل ، وإذا لزم الأمر ، فإننا نقسمها ، لكن القسم منطقي ومرتبط بالعمليات التجارية.
على سبيل المثال ، وصلت البضائع في السيارة ، نقسمها إلى صناديق. بالنسبة للعمليات المتزامنة ، يتم تخصيص خدمات دقيقة منفصلة ويتم إجراء اختبار صارم للحمل. يمثل استخدام كافكا تحديًا آخر لنا - اختبار خدمتنا مع تكامل كافكا يجعل جميع اختبارات وحدتنا غير متزامنة. لقد قمنا بحل هذه المشكلة من خلال كتابة طرق النفعية الخاصة بنا باستخدام Embedded Kafka Broker. هذا لا يلغي الحاجة إلى كتابة اختبارات الوحدة للطرق الفردية ، لكننا نفضل اختبار الحالات المعقدة باستخدام Kafka.
لقد أولينا الكثير من الاهتمام لسجلات التتبع حتى لا تضيع TraceId عند طرح الاستثناءات أثناء تشغيل الخدمات أو عند العمل مع مجموعة Kafka. وإذا لم تكن هناك أسئلة خاصة مع السؤال الأول ، فعندئذٍ في الحالة الثانية ، نضطر إلى الكتابة إلى السجل جميع TraceId التي جاءت بها الدفعة وتحديد واحد لمتابعة التتبع. بعد ذلك ، عند البحث عن TraceId الأولي ، سيكتشف المستخدم بسهولة التتبع الذي استمر التتبع.
الهدف 3. الحاجة إلى تخزين كمية كبيرة من البيانات: يتم إرسال أكثر من مليار ملصق سنويًا للتبغ وحده إلى X5. تتطلب الوصول المستمر والسريع. في المجموع ، يجب على النظام معالجة حوالي 10 مليار سجل في تاريخ حركة هذه السلع المميزة.
لحل المشكلة الثالثة ، تم اختيار قاعدة بيانات MongoDB NoSQL. قمنا ببناء جزء من 5 عقد وفي كل عقدة مجموعة متماثلة من 3 خوادم. يتيح لك هذا توسيع نطاق النظام أفقيًا ، وإضافة خوادم جديدة إلى المجموعة ، وضمان تحمل الخطأ. واجهنا هنا مشكلة أخرى - ضمان المعاملات في مجموعة المونغو ، مع مراعاة استخدام الخدمات الدقيقة القابلة للتوسيع أفقياً. على سبيل المثال ، تتمثل إحدى مهام نظامنا في الكشف عن محاولات إعادة بيع البضائع برموز العلامات نفسها. تظهر هنا التراكبات مع عمليات مسح خاطئة أو عمليات أمين صندوق خاطئة. وجدنا أن مثل هذه التكرارات يمكن أن تحدث داخل دفعة واحدة تتم معالجتها في كافكا ، وداخل دفعتين معالجتين بالتوازي. وبالتالي ، فإن التحقق من التكرارات عن طريق الاستعلام عن قاعدة البيانات لم يعط شيئًا.لكل من الخدمات الصغيرة ، قمنا بحل المشكلة بشكل منفصل بناءً على منطق الأعمال لهذه الخدمة. على سبيل المثال ، بالنسبة للإيصالات ، أضفنا شيكًا داخل الدفعة ومعالجة منفصلة لظهور التكرارات عند إدراجها.
حتى لا يؤثر عمل المستخدم مع تاريخ العمليات على أهم شيء - سير عمليات أعمالنا ، فقد قمنا بفصل جميع البيانات التاريخية إلى خدمة منفصلة بقاعدة بيانات منفصلة ، والتي تتلقى أيضًا معلومات من خلال كافكا. وبالتالي ، يعمل المستخدمون مع خدمة معزولة دون التأثير على الخدمات التي تعالج البيانات على العمليات الحالية.
المهمة 4. إعادة معالجة قوائم الانتظار والمراقبة:
في الأنظمة الموزعة ، تنشأ مشاكل وأخطاء في توافر قواعد البيانات وقوائم الانتظار ومصادر البيانات الخارجية حتماً. في حالة ماركوس ، مصدر هذه الأخطاء هو التكامل مع الأنظمة الخارجية. كان من الضروري إيجاد حل يسمح بالطلبات المتكررة للاستجابات الخاطئة مع مهلة محددة ، ولكن في نفس الوقت لا يتوقف عن معالجة الطلبات الناجحة في قائمة الانتظار الرئيسية. لهذا ، تم اختيار ما يسمى بمفهوم "إعادة المحاولة على أساس الموضوع". لكل موضوع رئيسي ، يتم إنشاء موضوع واحد أو أكثر من مواضيع إعادة المحاولة ، والتي يتم إرسال رسائل خاطئة إليها ، وفي نفس الوقت ، يتم التخلص من التأخير في معالجة الرسائل من الموضوع الرئيسي. مخطط التفاعل -
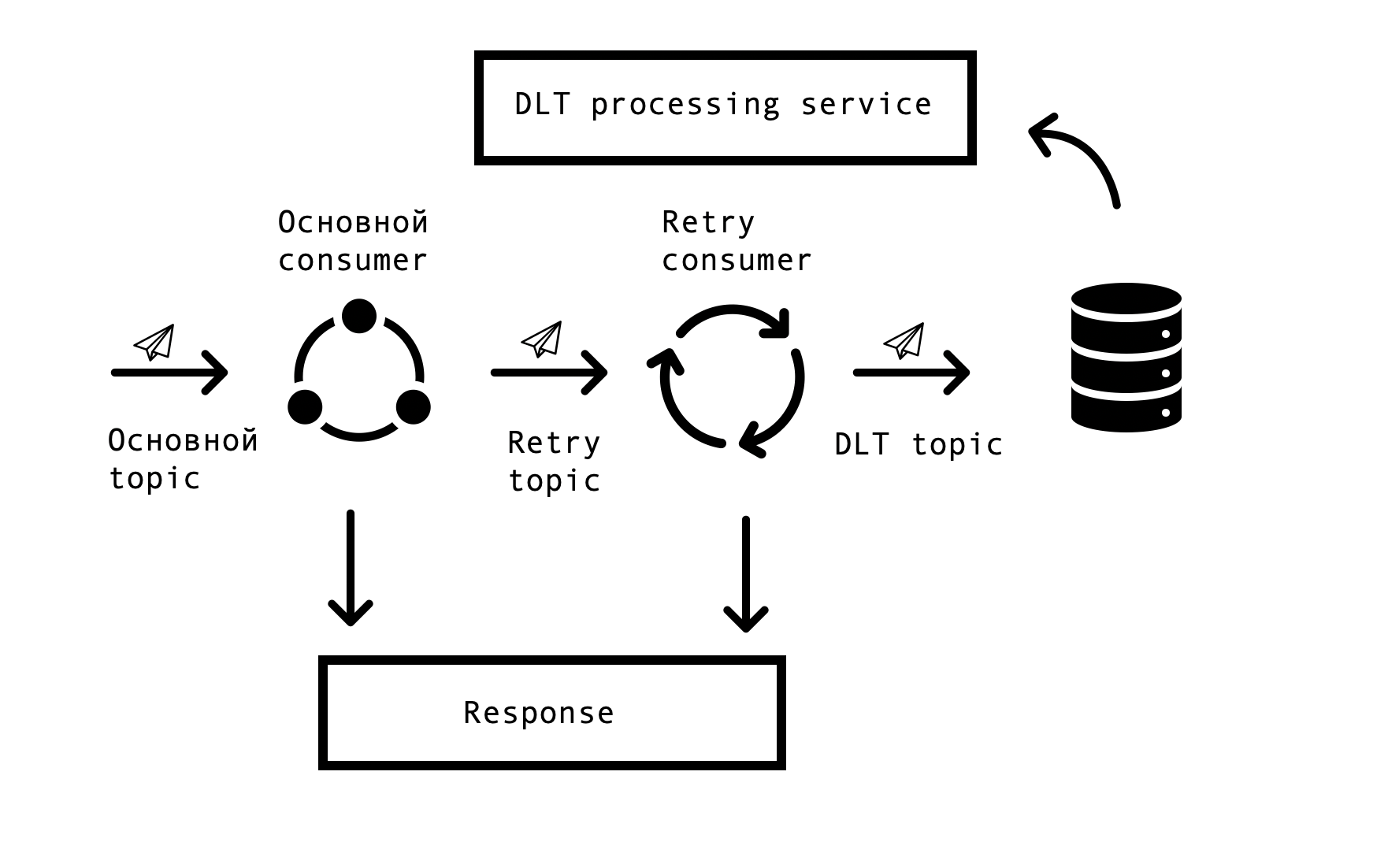
لتنفيذ مثل هذا المخطط ، كنا بحاجة إلى ما يلي - لدمج هذا الحل مع Spring وتجنب ازدواج التعليمات البرمجية. في اتساع الشبكة ، توصلنا إلى حل مماثل يعتمد على Spring BeanPostProccessor ، ولكن بدا لنا مرهقًا بلا داعٍ. قدم فريقنا حلاً أبسط يتيح لنا الاندماج في دورة إنشاء المستهلك في Spring وإضافة عملاء إعادة المحاولة. قدمنا نموذجًا أوليًا لحلنا لفريق الربيع ، يمكنك رؤيته هنا . يتم تكوين عدد عملاء إعادة المحاولة وعدد المحاولات لكل مستهلك من خلال المعلمات ، اعتمادًا على احتياجات عملية الأعمال ، ولكل شيء يعمل ، كل ما تبقى هو وضع org.springframework.kafka.annotation.KafkaListener ، وهو أمر مألوف لجميع مطوري الربيع.
إذا تعذرت معالجة الرسالة بعد كل محاولات إعادة المحاولة ، يتم إرسالها إلى DLT (موضوع الرسالة الميتة) باستخدام Spring DeadLetterPublishingRecoverer. بناءً على طلب الدعم ، قمنا بتوسيع هذه الوظيفة وقمنا بتقديم خدمة منفصلة تتيح لك عرض الرسائل و stackTrace و traceId وغيرها من المعلومات المفيدة حول تلك التي دخلت في DLT. بالإضافة إلى ذلك ، تمت إضافة المراقبة والتنبيهات إلى جميع موضوعات DLT ، والآن ، في الواقع ، فإن ظهور رسالة في موضوع DLT هو سبب للتحليل وإنشاء عيب. هذا مريح للغاية - من خلال اسم الموضوع ، نفهم على الفور في أي خطوة من العملية نشأت المشكلة ، والتي تسرع بشكل كبير البحث عن السبب الجذري.

في الآونة الأخيرة ، قمنا بتطبيق واجهة تسمح لنا بإعادة إرسال الرسائل من خلال دعمنا ، بعد القضاء على أسبابها (على سبيل المثال ، استعادة قابلية تشغيل النظام الخارجي) ، وبطبيعة الحال ، إنشاء العيب المقابل للتحليل. هذا هو المكان الذي أصبحت فيه موضوعاتنا الذاتية مفيدة ، حتى لا يتم إعادة تشغيل سلسلة معالجة طويلة ، يمكنك إعادة تشغيلها من الخطوة المطلوبة.
تشغيل المنصة
تعمل المنصة بالفعل بشكل مثمر ، ونقوم كل يوم بتنفيذ عمليات التسليم والشحن ، وربط مراكز التوزيع والمتاجر الجديدة. كجزء من المشروع التجريبي ، يعمل النظام مع مجموعات السلع "التبغ" و "الأحذية".
يشارك فريقنا بأكمله في إجراء عمليات تجريبية وتحليل المشكلات الناشئة وتقديم مقترحات لتحسين منتجاتنا من تحسين السجلات إلى العمليات المتغيرة.
حتى لا نكرر أخطائنا ، تنعكس جميع الحالات التي تم العثور عليها أثناء الإصدار التجريبي في الاختبارات التلقائية. يسمح لك وجود عدد كبير من الاختبارات الذاتية واختبارات الوحدة بإجراء اختبار الانحدار ووضع إصلاح عاجل في غضون ساعات قليلة.
نواصل الآن تطوير وتحسين منصتنا ، ونواجه باستمرار تحديات جديدة. إذا كنت مهتمًا ، فسنخبرك عن حلولنا في المقالات التالية.