
لذا حان الوقت لنشر الجزء الثاني ، واليوم سنستمر في تطوير محرر الكود الخاص بنا وإضافة الإكمال التلقائي وإبراز الخطأ إليه ، ونتحدث أيضًا عن سبب عدم تأخر أي محرر للكود
EditText.
قبل قراءة المزيد ، أوصي بشدة بقراءة الجزء الأول .
المقدمة
 أولاً ، لنتذكر المكان الذي توقفنا فيه في الجزء الأخير . لقد كتبنا بناء جملة محسنًا يسلط الضوء على تحليل النص في الخلفية وألوان الجزء المرئي فقط ، بالإضافة إلى ترقيم الأسطر المضافة (وإن كان ذلك بدون فواصل أسطر android ، ولكن لا يزال).
أولاً ، لنتذكر المكان الذي توقفنا فيه في الجزء الأخير . لقد كتبنا بناء جملة محسنًا يسلط الضوء على تحليل النص في الخلفية وألوان الجزء المرئي فقط ، بالإضافة إلى ترقيم الأسطر المضافة (وإن كان ذلك بدون فواصل أسطر android ، ولكن لا يزال).
في هذا الجزء ، سنضيف استكمال الكود وإبراز الخطأ.
اكتمال الرمز
أولاً ، دعنا نتخيل كيف يجب أن يعمل:
- يكتب المستخدم كلمة
- بعد إدخال الأحرف N الأولى ، تظهر نافذة تحتوي على نصائح
- عند النقر على التلميح ، تتم طباعة الكلمة تلقائيًا
- يتم إغلاق النافذة ذات التلميحات ويتم تحريك المؤشر إلى نهاية الكلمة
- إذا أدخل المستخدم الكلمة المعروضة في تلميح الأداة بنفسه ، فيجب إغلاق النافذة التي تحتوي على تلميحات تلقائيًا
ألا يبدو مثل أي شيء؟ يحتوي Android بالفعل على مكون له نفس المنطق تمامًا -
MultiAutoCompleteTextViewلذلك PopupWindowلا يتعين علينا كتابة العكازات معنا (لقد تمت كتابتها بالفعل لنا).
الخطوة الأولى هي تغيير والد الفصل:
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.autoCompleteTextViewStyle
) : MultiAutoCompleteTextView(context, attrs, defStyleAttr)
الآن نحن بحاجة إلى الكتابة
ArrayAdapterالتي ستعرض النتائج التي تم العثور عليها. لن يكون رمز المحول الكامل متاحًا ، ويمكن العثور على أمثلة للتنفيذ على الإنترنت. لكني سأتوقف في الوقت الحالي مع التصفية.
لكي
ArrayAdapterنتمكن من فهم التلميحات التي يجب عرضها ، نحتاج إلى تجاوز الطريقة getFilter:
override fun getFilter(): Filter {
return object : Filter() {
private val suggestions = mutableListOf<String>()
override fun performFiltering(constraint: CharSequence?): FilterResults {
// ...
}
override fun publishResults(constraint: CharSequence?, results: FilterResults) {
clear() //
addAll(suggestions)
notifyDataSetChanged()
}
}
}
وفي الطريقة ،
performFilteringاملأ قائمة suggestionsالكلمات استنادًا إلى الكلمة التي بدأ المستخدم في إدخالها (الواردة في متغير constraint).
من أين تحصل على البيانات قبل التصفية؟
كل هذا يتوقف عليك - يمكنك استخدام نوع من المترجم لتحديد الخيارات الصالحة فقط ، أو مسح النص بالكامل عند فتح الملف. من أجل بساطة المثال ، سأستخدم قائمة جاهزة من خيارات الإكمال التلقائي:
private val staticSuggestions = mutableListOf(
"function",
"return",
"var",
"const",
"let",
"null"
...
)
...
override fun performFiltering(constraint: CharSequence?): FilterResults {
val filterResults = FilterResults()
val input = constraint.toString()
suggestions.clear() //
for (suggestion in staticSuggestions) {
if (suggestion.startsWith(input, ignoreCase = true) &&
!suggestion.equals(input, ignoreCase = true)) {
suggestions.add(suggestion)
}
}
filterResults.values = suggestions
filterResults.count = suggestions.size
return filterResults
}
منطق التصفية هنا بدائي إلى حد ما ، فإننا نراجع القائمة بأكملها ، وتجاهل الحالة ، نقارن بداية السلسلة.
تثبيت المحول ، اكتب النص - لا يعمل. ماذا دهاك؟ على الرابط الأول في Google ، صادفنا إجابة تقول أننا نسينا التثبيت
Tokenizer.
ما هو Tokenizer؟
بعبارات بسيطة ، من المفيد
Tokenizerأن MultiAutoCompleteTextViewنفهم بعد ذلك الحرف المدخل الذي يمكن اعتباره إدخال كلمة كاملة. لديها أيضًا تنفيذ جاهز في شكل CommaTokenizerفصل الكلمات إلى فواصل ، وهو الأمر الذي لا يناسبنا في هذه الحالة.
حسنًا ، بما
CommaTokenizerأننا غير راضين ، فسوف نكتب الخاصة بنا:
رمز مخصص
class SymbolsTokenizer : MultiAutoCompleteTextView.Tokenizer {
companion object {
private const val TOKEN = "!@#$%^&*()_+-={}|[]:;'<>/<.? \r\n\t"
}
override fun findTokenStart(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i > 0 && !TOKEN.contains(text[i - 1])) {
i--
}
while (i < cursor && text[i] == ' ') {
i++
}
return i
}
override fun findTokenEnd(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i < text.length) {
if (TOKEN.contains(text[i - 1])) {
return i
} else {
i++
}
}
return text.length
}
override fun terminateToken(text: CharSequence): CharSequence = text
}
دعونا نكتشف ذلك:
TOKEN - سلسلة تحتوي على أحرف تفصل كلمة واحدة عن أخرى. في الأساليب findTokenStartو findTokenEndنذهب من خلال النص بحثا عن هذه الرموز التي تفصل جدا. terminateTokenتسمح لك الطريقة بإرجاع نتيجة معدلة ، لكننا لسنا بحاجة إليها ، لذلك نعيد النص دون تغيير.
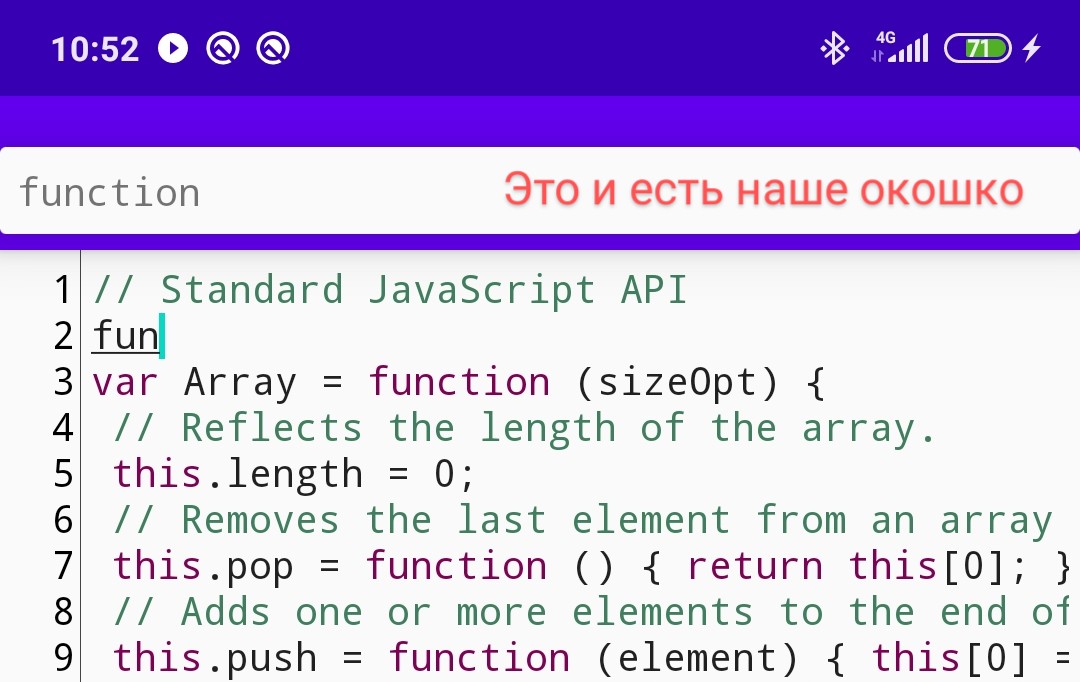
أنا أفضل أيضًا إضافة تأخير إدخال مكون من حرفين قبل عرض القائمة:
textProcessor.threshold = 2تثبيت وتشغيل وكتابة النص - يعمل! ولكن لسبب ما ، تتصرف النافذة ذات المطالبات بشكل غريب - يتم عرضها بعرض كامل ، وارتفاعها صغير ، ومن الناحية النظرية يجب أن تظهر تحت المؤشر ، كيف سنصلحها؟
تصحيح العيوب البصرية
هذا هو المكان الذي يبدأ فيه المتعة ، لأن واجهة برمجة التطبيقات تسمح لنا بتغيير ليس فقط حجم النافذة ، ولكن أيضًا تغيير موضعها.
أولاً ، دعنا نقرر الحجم. في رأيي ، سيكون الخيار الأكثر ملاءمة هو نافذة نصف ارتفاع الشاشة وعرضها ، ولكن نظرًا لأن حجمنا
Viewيتغير اعتمادًا على حالة لوحة المفاتيح ، فسنحدد الأحجام في الطريقة onSizeChanged:
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
dropDownWidth = w * 1 / 2
dropDownHeight = h * 1 / 2
}
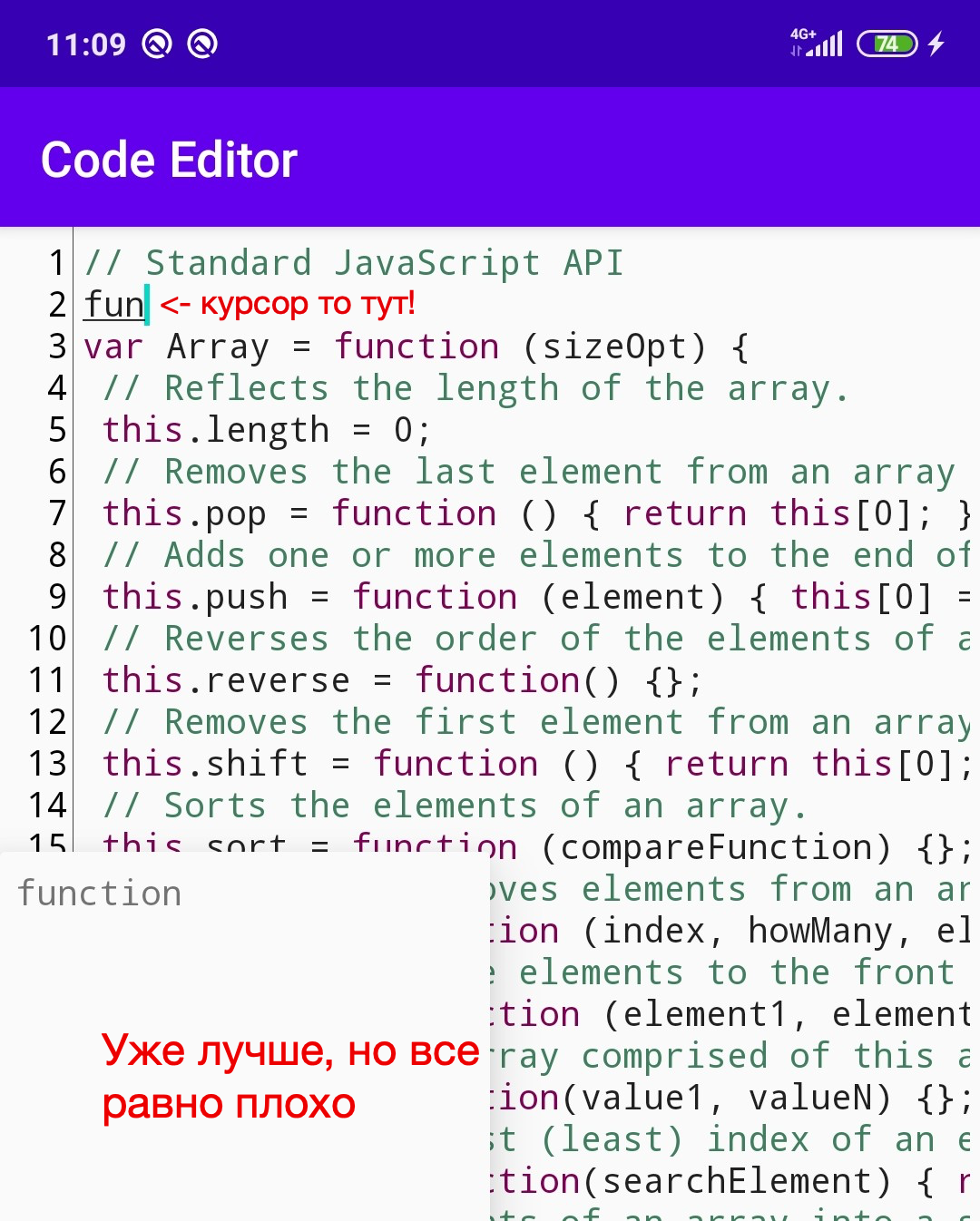 يبدو أفضل ، ولكن ليس كثيرًا. نريد أن نحقق أن النافذة تظهر تحت المؤشر وتتحرك معها أثناء التحرير.
يبدو أفضل ، ولكن ليس كثيرًا. نريد أن نحقق أن النافذة تظهر تحت المؤشر وتتحرك معها أثناء التحرير.
إذا كان كل شيء بسيطًا للغاية مع التحرك على طول X - فنحن نأخذ إحداثيات بداية الحرف ونعين هذه القيمة إلى
dropDownHorizontalOffset، فسيكون اختيار الارتفاع أكثر صعوبة.
جوجل حول خصائص الخطوط ، يمكنك أن تتعثر في هذا المنشور . توضح الصورة التي أرفقها المؤلف بوضوح الخصائص التي يمكننا استخدامها لحساب الإحداثيات الرأسية.

الآن دعنا نكتب طريقة سنتصل بها عندما يتغير النص إلى
onTextChanged:
private fun onPopupChangePosition() {
val line = layout.getLineForOffset(selectionStart) //
val x = layout.getPrimaryHorizontal(selectionStart) //
val y = layout.getLineBaseline(line) // baseline
val offsetHorizontal = x + gutterWidth //
dropDownHorizontalOffset = offsetHorizontal.toInt()
val offsetVertical = y - scrollY // -scrollY ""
dropDownVerticalOffset = offsetVertical
}
يبدو أنهم لم ينسوا أي شيء - تعمل إزاحة X ، ولكن يتم حساب إزاحة Y بشكل غير صحيح. هذا لأننا لم نحدد
dropDownAnchorفي الترميز:
android:dropDownAnchor="@id/toolbar"من خلال تحديد
Toolbarالجودة ، dropDownAnchorنسمح للأداة بمعرفة أن القائمة المنسدلة سيتم عرضها أدناه .
الآن ، إذا بدأنا في تحرير النص ، فسيعمل كل شيء ، ولكن بمرور الوقت ، سنلاحظ أنه إذا كانت النافذة لا تتناسب مع المؤشر ، يتم سحبها لأعلى بمسافة بادئة ضخمة ، والتي تبدو قبيحة. حان الوقت لكتابة عكاز:

val offset = offsetVertical + dropDownHeight
if (offset < getVisibleHeight()) {
dropDownVerticalOffset = offsetVertical
} else {
dropDownVerticalOffset = offsetVertical - dropDownHeight
}
...
private fun getVisibleHeight(): Int {
val rect = Rect()
getWindowVisibleDisplayFrame(rect)
return rect.bottom - rect.top
}
لا نحتاج إلى تغيير المسافة البادئة إذا كان المجموع
offsetVertical + dropDownHeightأقل من الارتفاع المرئي للشاشة ، لأنه في هذه الحالة يتم وضع النافذة تحت المؤشر. ولكن إذا كانت لا تزال أكثر ، فإننا نطرح من المسافة البادئة dropDownHeight- لذلك سوف تتناسب مع المؤشر بدون مسافة بادئة ضخمة تضيفها الأداة نفسها.
ملاحظة: يمكنك رؤية وميض لوحة المفاتيح على gif ، ولأكون صادقًا ، لا أعرف كيفية إصلاحها ، لذا إذا كان لديك حل ، اكتب.
تسليط الضوء على الأخطاء
مع تسليط الضوء على الخطأ ، كل شيء أبسط بكثير مما يبدو ، لأننا أنفسنا لا نستطيع اكتشاف أخطاء بناء الجملة في التعليمات البرمجية مباشرة - سنستخدم مكتبة محلل تابع لجهة خارجية. نظرًا لأنني أكتب محررًا لجافا سكريبت ، وقع اختياري على Rhino ، وهو محرك جافا سكريبت شائع تم اختباره بمرور الوقت وما زال مدعومًا.
كيف سنحلل؟
يعد إطلاق الكركدن عملية مرهقة ، لذا فإن تشغيل المحلل اللغوي بعد إدخال كل شخصية (كما فعلنا مع التمييز) ليس خيارًا على الإطلاق. لحل هذه المشكلة ، سأستخدم مكتبة RxBinding ، وبالنسبة لأولئك الذين لا يريدون سحب RxJava إلى المشروع ، يمكنك تجربة خيارات مماثلة . سيساعدنا
عامل الهاتف
debounceعلى تحقيق ما نريد ، وإذا لم تكن على دراية به ، أنصحك بقراءة هذه المقالة .
textProcessor.textChangeEvents()
.skipInitialValue()
.debounce(1500, TimeUnit.MILLISECONDS)
.filter { it.text.isNotEmpty() }
.distinctUntilChanged()
.observeOn(AndroidSchedulers.mainThread())
.subscribeBy {
//
}
.disposeOnFragmentDestroyView()
الآن دعنا نكتب نموذجًا سيعود المحلل اللغوي إلينا:
data class ParseResult(val exception: RhinoException?)أنا أقترح استخدام منطق التالية: إذا وجدت أية أخطاء، ثم هناك
exceptionسيكون null. خلاف ذلك ، سوف نحصل على كائن RhinoExceptionيحتوي على جميع المعلومات الضرورية - رقم السطر ، رسالة الخطأ ، StackTrace ، إلخ.
حسنًا ، في الواقع ، التحليل نفسه:
// !
val context = Context.enter() // org.mozilla.javascript.Context
context.optimizationLevel = -1
context.maximumInterpreterStackDepth = 1
try {
val scope = context.initStandardObjects()
context.evaluateString(scope, sourceCode, fileName, 1, null)
return ParseResult(null)
} catch (e: RhinoException) {
return ParseResult(e)
} finally {
Context.exit()
}
الفهم:
أهم شيء هنا هو الطريقة
evaluateString- فهي تسمح لك بتشغيل الكود الذي مررناه كسلسلة sourceCode. يشار إلى fileNameاسم الملف في - سيتم عرضه في الأخطاء ، الوحدة هي رقم السطر لبدء العد ، الوسيطة الأخيرة هي مجال الأمان ، لكننا لسنا بحاجة إليه ، لذلك قمنا بتعيينه null.
تحسين المستوى والحد الأقصى IntertereterStackDepth
تسمح لك المعلمة التي
optimizationLevelتتراوح قيمتها من 1 إلى 9 بتمكين "تحسينات" معينة للكود (تحليل تدفق البيانات ، تحليل تدفق النوع ، وما إلى ذلك) ، والتي ستحول التحقق من بناء الجملة البسيط إلى عملية مستهلكة للوقت للغاية ، ولا نحتاج إليها.
إذا كنت تستخدمه بقيمة 0 ، فلن يتم تطبيق كل هذه "التحسينات" ، ومع ذلك ، إذا فهمت بشكل صحيح ، فسيستمر Rhino في استخدام بعض الموارد غير اللازمة للتحقق البسيط من الأخطاء ، مما يعني أنه لا يناسبنا.
لا تزال هناك قيمة سلبية فقط - بتحديد -1 نقوم بتنشيط وضع "المترجم" ، وهو بالضبط ما نحتاجه. و ثائق تقول أن هذه هي الطريقة الأسرع والأكثر اقتصادية لتشغيل وحيد القرن.
maximumInterpreterStackDepthتسمح لك
المعلمة بتحديد عدد المكالمات المتكررة.
دعنا نتخيل ما يحدث إذا لم تحدد هذه المعلمة:
- سوف يكتب المستخدم الرمز التالي:
function recurse() { recurse(); } recurse(); - سيقوم Rhino بتشغيل الكود ، وفي ثانية سيتعطل تطبيقنا
OutOfMemoryError. النهاية.
عرض الأخطاء
كما قلت سابقًا ، بمجرد أن نحصل على المجموعة
ParseResultالتي تحتوي على RhinoException، سيكون لدينا جميع البيانات اللازمة لعرضها ، بما في ذلك رقم الخط - نحتاج فقط إلى استدعاء الطريقة lineNumber().
الآن دعنا نكتب امتداد الخط الأحمر المتعرج الذي قمت بنسخه إلى StackOverflow . هناك الكثير من التعليمات البرمجية ، ولكن المنطق بسيط - ارسم خطين أحمر قصير بزوايا مختلفة.
ErrorSpan.kt
class ErrorSpan(
private val lineWidth: Float = 1 * Resources.getSystem().displayMetrics.density + 0.5f,
private val waveSize: Float = 3 * Resources.getSystem().displayMetrics.density + 0.5f,
private val color: Int = Color.RED
) : LineBackgroundSpan {
override fun drawBackground(
canvas: Canvas,
paint: Paint,
left: Int,
right: Int,
top: Int,
baseline: Int,
bottom: Int,
text: CharSequence,
start: Int,
end: Int,
lineNumber: Int
) {
val width = paint.measureText(text, start, end)
val linePaint = Paint(paint)
linePaint.color = color
linePaint.strokeWidth = lineWidth
val doubleWaveSize = waveSize * 2
var i = left.toFloat()
while (i < left + width) {
canvas.drawLine(i, bottom.toFloat(), i + waveSize, bottom - waveSize, linePaint)
canvas.drawLine(i + waveSize, bottom - waveSize, i + doubleWaveSize, bottom.toFloat(), linePaint)
i += doubleWaveSize
}
}
}
الآن يمكنك كتابة طريقة لتثبيت الامتداد على خط المشكلة:
fun setErrorLine(lineNumber: Int) {
if (lineNumber in 0 until lineCount) {
val lineStart = layout.getLineStart(lineNumber)
val lineEnd = layout.getLineEnd(lineNumber)
text.setSpan(ErrorSpan(), lineStart, lineEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
من المهم أن تتذكر أنه نظرًا لأن النتيجة تأتي مع تأخير ، فقد يكون لدى المستخدم الوقت لمحو بضعة أسطر من التعليمات البرمجية ، ثم
lineNumberقد يتبين أنها غير صالحة.
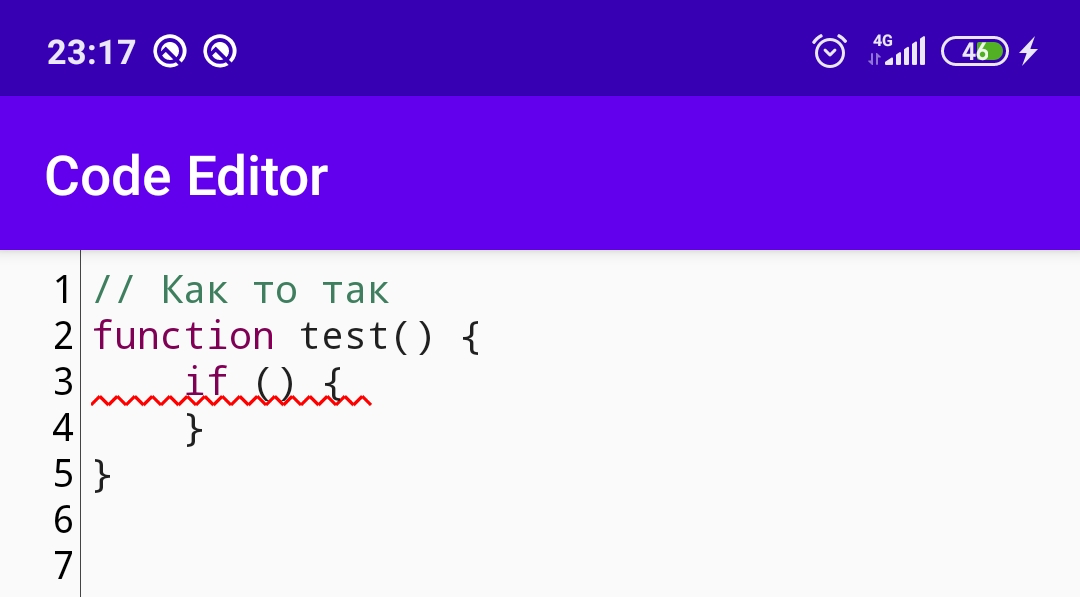 لذلك ، حتى لا نحصل عليه ،
لذلك ، حتى لا نحصل عليه ، IndexOutOfBoundsExceptionنضيف شيكًا في البداية. حسنًا ، وفقًا للمخطط المألوف ، نحسب الحرف الأول والأخير من السلسلة ، وبعد ذلك نعين الامتداد.
الشيء الرئيسي هو عدم نسيان مسح النص من الامتدادات المحددة بالفعل في
afterTextChanged:
fun clearErrorSpans() {
val spans = text.getSpans<ErrorSpan>(0, text.length)
for (span in spans) {
text.removeSpan(span)
}
}
لماذا يتأخر محررو الكود؟
في مقالتين ، كتبنا محررًا جيدًا للشفرة يرث من
EditTextو MultiAutoCompleteTextView، ولكن لا يمكننا أن نتباهى بالأداء عند العمل مع الملفات الكبيرة.
إذا قمت بفتح نفس TextView.java ل 9K + خطوط للقانون، ثم أي محرر نصوص مكتوبة وفقا لنفس المبدأ لنا سوف يتخلف.
س: لماذا لا يتأخر QuickEdit بعد ذلك؟
ج: لأنه تحت غطاء محرك السيارة ، لا يستخدم
EditTextولا TextView.
في الآونة الأخيرة، والمحررين التعليمات البرمجية على CustomView تكتسب شعبية ( هنا و هناك ، أيضا، أو هنا و هناك، وهناك الكثير منهم). تاريخياً ، يمتلك TextView الكثير من المنطق الزائد الذي لا يحتاجه محررو التعليمات البرمجية. أول الأشياء التي تتبادر إلى الذهن هي الملء التلقائي ، والرموز التعبيرية ، والأشكال المركبة ، والروابط القابلة للنقر ، وما إلى ذلك.
إذا فهمت بشكل صحيح ، تخلص مؤلفو المكتبات من كل هذا ببساطة ، ونتيجة لذلك حصلوا على محرر نصوص قادر على العمل مع ملفات مليون سطر دون تحميل الكثير على UI Thread. (على الرغم من أنني قد يكون مخطئا جزئيا، لم أكن أفهم مصدر من ذلك بكثير)
وهناك خيار آخر، ولكن في رأيي أقل جاذبية - المحررين التعليمات البرمجية على عرض ويب ( هنا و هناك، هناك الكثير منهم أيضًا). أنا لا أحبها لأن واجهة المستخدم على WebView تبدو أسوأ من الواجهة الأصلية ، كما أنها تفقد أمام المحررين في CustomView من حيث الأداء.
خاتمة
إذا كانت مهمتك هي كتابة محرر التعليمات البرمجية والوصول إلى أعلى Google Play ، فلا تضيع الوقت وخذ مكتبة جاهزة في CustomView. إذا كنت ترغب في الحصول على تجربة فريدة ، فاكتب كل شيء بنفسك باستخدام الحاجيات الأصلية.
سأترك أيضًا رابطًا لشفرة المصدر لمحرر الشفرة الخاص بي على GitHub ، حيث لن تجد فقط تلك الميزات التي أخبرتها عنها في هاتين المادتين ، ولكن أيضًا العديد من الميزات الأخرى التي تم تركها دون اهتمام.
شكرا!