ذات مرة ، عشية مؤتمر العملاء الذي تعقده سنويًا مجموعة DAN ، فكرنا في أنه يمكن التفكير في أشياء مثيرة للاهتمام حتى يكون لشركائنا وعملائنا انطباعات وذكريات ممتعة عن الحدث. قررنا تحليل أرشيف لآلاف الصور من هذا المؤتمر والعديد من الصور السابقة (وكان هناك 18 صورة في ذلك الوقت): يرسل لنا شخص صورته ، وفي بضع ثوان نرسل إليه مجموعة مختارة من الصور معه لعدة سنوات من أرشيفنا.
لم نبتكر دراجة ، بل أخذنا مكتبة دلب المعروفة وتلقينا زخارف (تمثيلات متجهة) لكل شخص.
أضفنا روبوت Telegram من أجل الراحة ، وكان كل شيء على ما يرام. من وجهة نظر خوارزميات التعرف على الوجه ، عمل كل شيء مع اثارة ضجة ، ولكن المؤتمر انتهى ، ولم أرغب في التخلي عن التقنيات المجربة والمختبرة. أردنا الانتقال من عدة آلاف من الأشخاص إلى مئات الملايين ، ولكن لم يكن لدينا مهمة عمل محددة. بعد فترة ، كان لدى زملائنا مهمة تتطلب العمل مع مثل هذه الكميات الكبيرة من البيانات.
كان السؤال هو كتابة نظام مراقبة روبوت ذكي داخل شبكة Instagram. هنا أفضت فكرتنا إلى نهج بسيط ومعقد:
الطريقة البسيطة: ضع في اعتبارك جميع الحسابات التي تحتوي على اشتراكات أكثر بكثير من المشتركين ، ولا صور رمزية ، ولا يتم تعبئة الاسم الكامل ، وما إلى ذلك. ونتيجة لذلك ، نحصل على حشد غير مفهوم من الحسابات شبه الميتة.
بالطريقة الصعبة: نظرًا لأن الروبوتات الحديثة أصبحت أكثر ذكاءً ، والآن ينشرون المحتوى وينامون وحتى يكتبون المحتوى ، فإن السؤال الذي يطرح نفسه: كيف يتم التقاط هذه؟ أولاً ، راقب أصدقاءهم عن كثب ، لأنهم غالبًا ما يكونون روبوتات أيضًا ، وتتبع الصور المكررة. ثانيًا ، نادرًا ما يعرف الروبوت كيفية إنشاء صوره الخاصة (على الرغم من أن ذلك ممكن) ، مما يعني أن الصور المكررة لأشخاص في حسابات مختلفة على Instagram هي محفز جيد للعثور على شبكة من الروبوتات.
ماذا بعد؟
إذا كان المسار البسيط قابلاً للتنبؤ به تمامًا وسرعان ما أعطى بعض النتائج ، فإن المسار الصعب يكون صعبًا على وجه التحديد لأنه من أجل تنفيذه ، سيتعين علينا تحويل وفهرسة كميات كبيرة للغاية من الصور الفوتوغرافية لإجراء مقارنات لاحقة لأوجه التشابه - الملايين ، وحتى المليارات. كيفية وضعها موضع التنفيذ؟ بعد كل شيء ، تثور أسئلة فنية:
- سرعة ودقة البحث
- مساحة القرص المستخدمة بواسطة البيانات
- حجم ذاكرة RAM المستخدمة.
إذا لم يكن هناك سوى عدد قليل من الصور ، على الأقل ما لا يزيد عن عشرة آلاف ، فيمكننا أن نقصر أنفسنا على حلول بسيطة مع تجمع المتجهات ، ولكن العمل مع كميات كبيرة من المتجهات والعثور على أقرب الجوار لمتجه معين ، مطلوب خوارزميات معقدة ومحسنة.
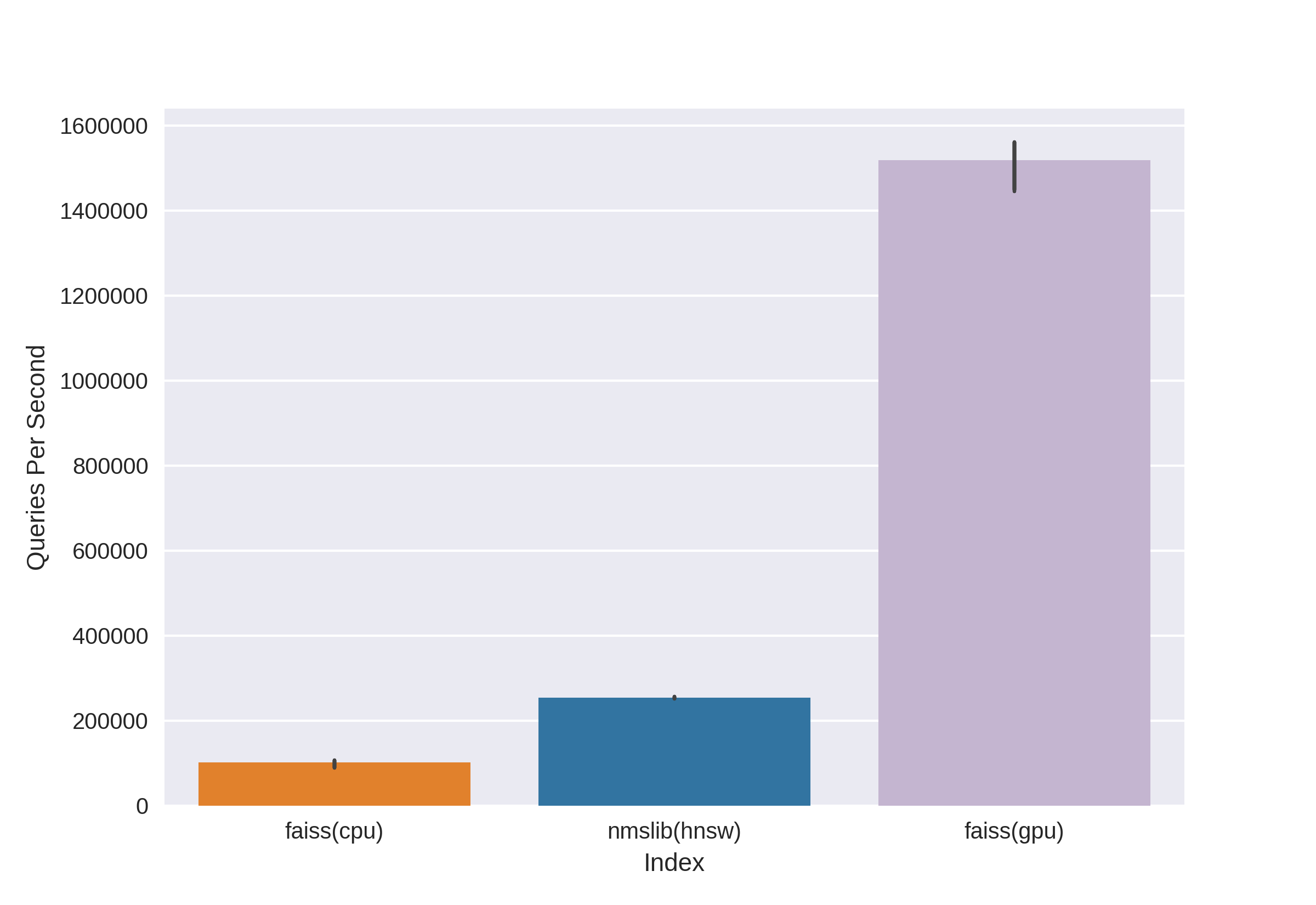
هناك تقنيات معروفة ومثبتة ، مثل Annoy و FAISS و HNSW. الصيام HNSW خوارزمية البحث جار المتاحة في nmslib و المكتبات hnswlib، يظهر نتائج متطورة على وحدة المعالجة المركزية ، كما يمكن رؤيته في نفس المعايير. لكننا قطعناها على الفور ، لأننا لسنا سعداء بحجم الذاكرة المستخدمة عند العمل مع كميات كبيرة من البيانات. بدأنا في الاختيار بين Annoy و FAISS واختارنا في النهاية FAISS بسبب ملاءمتها ، واستخدام أقل للذاكرة ، والاستخدام المحتمل على وحدات معالجة الرسومات ومعايير الأداء (يمكنك أن ترى ، على سبيل المثال ، هنا ). بالمناسبة ، في FAISS ، يتم تنفيذ خوارزمية HNSW كخيار.
ما هو FAISS؟
Facebook التشابه في بحث AI AI - تم تطويره بواسطة Facebook AI Research Team للعثور بسرعة على أقرب الجيران والتجمع في مساحة النواقل. تتيح سرعة البحث العالية العمل باستخدام بيانات كبيرة جدًا - حتى عدة مليارات من المتجهات.
الميزة الرئيسية لـ FAISS هي نتائجها المتطورة على وحدة معالجة الرسومات ، في حين أن تنفيذها على وحدة المعالجة المركزية أقل قليلاً من hnsw (nmslib). أردنا أن نكون قادرين على البحث في كل من وحدة المعالجة المركزية ووحدة معالجة الرسومات. بالإضافة إلى ذلك ، تم تحسين FAISS من حيث استخدام الذاكرة والبحث على مجموعات كبيرة. يتيح لك
Source
FAISS البحث بسرعة عن أقرب ناقلات k لمتجه معين x. لكن كيف يعمل هذا البحث تحت غطاء المحرك؟
المؤشرات
المفهوم الرئيسي في FAISS هو الفهرس ، وفي الواقع ، إنه مجرد مجموعة من المتجهات والمتجهات. مجموعات المعلمات مختلفة تمامًا وتعتمد على احتياجات المستخدم. يمكن أن تبقى المتجهات بدون تغيير ، أو يمكن إعادة ترتيبها. تتوفر بعض المؤشرات للعمل فورًا بعد إضافة المتجهات إليها ، وبعضها يتطلب تدريبًا أوليًا. يتم تخزين أسماء المتجهات في الفهرس: إما في الترقيم من 0 إلى n ، أو كرقم يناسب نوع Int64.
المؤشر الأول ، والأبسط الذي استخدمناه في المؤتمر ، هو Flat . يخزن فقط جميع المتجهات في حد ذاته ، ويتم البحث عن متجه معين عن طريق البحث الشامل ، لذلك لا توجد حاجة لتدريبه (ولكن المزيد عن التدريب أدناه). مع كمية صغيرة من البيانات ، يمكن لهذا الفهرس البسيط أن يغطي بالكامل احتياجات البحث.
مثال:
import numpy as np
dim = 512 # 512
nb = 10000 #
nq = 5 #
np.random.seed(228)
vectors = np.random.random((nb, dim)).astype('float32')
query = np.random.random((nq, dim)).astype('float32')
قم بإنشاء فهرس مسطح وأضف المتجهات بدون تدريب:
import faiss
index = faiss.IndexFlatL2(dim)
print(index.ntotal) #
index.add(vectors)
print(index.ntotal) # 10 000
الآن نجد 7 أقرب جيران للمتجهات الخمسة الأولى من المتجهات:
topn = 7
D, I = index.search(vectors[:5], topn) # : Distances, Indices
print(I)
print(D)
انتاج |
[[0 5662 6778 7738 6931 7809 7184]
[1 5831 8039 2150 5426 4569 6325]
[2 7348 2476 2048 5091 6322 3617]
[3 791 3173 6323 8374 7273 5842]
[4 6236 7548 746 6144 3906 5455]]
[[ 0. 71.53578 72.18823 72.74326 73.2243 73.333244 73.73317 ]
[ 0. 67.604805 68.494774 68.84221 71.839905 72.084335 72.10817 ]
[ 0. 66.717865 67.72709 69.63666 70.35903 70.933304 71.03237 ]
[ 0. 68.26415 68.320595 68.82381 68.86328 69.12087 69.55179 ]
[ 0. 72.03398 72.32417 73.00308 73.13054 73.76181 73.81281 ]]نرى أن أقرب الجيران بمسافة 0 هي المتجهات نفسها ، ويتم ترتيب الباقي من خلال زيادة المسافة. دعونا نبحث عن ناقلاتنا من الاستعلام:
D, I = index.search(query, topn)
print(I)
print(D)
انتاج |
[[2467 2479 7260 6199 8640 2676 1767]
[2623 8313 1500 7840 5031 52 6455]
[1756 2405 1251 4136 812 6536 307]
[3409 2930 539 8354 9573 6901 5692]
[8032 4271 7761 6305 8929 4137 6480]]
[[73.14189 73.654526 73.89804 74.05615 74.11058 74.13567 74.443436]
[71.830215 72.33813 72.973885 73.08897 73.27939 73.56996 73.72397 ]
[67.49588 69.95635 70.88528 71.08078 71.715965 71.76285 72.1091 ]
[69.11357 69.30089 70.83269 71.05977 71.3577 71.62457 71.72549 ]
[69.46417 69.66577 70.47629 70.54611 70.57645 70.95326 71.032005]]الآن المسافات في العمود الأول من النتائج ليست صفراً ، لأن المتجهات من الاستعلام ليست في الفهرس.
يمكن حفظ الفهرس على القرص ثم تنزيله من القرص:
faiss.write_index(index, "flat.index")
index = faiss.read_index("flat.index")يبدو أن كل شيء أساسي! بضعة أسطر من التعليمات البرمجية - ولدينا بالفعل بنية للبحث عن طريق ناقلات ذات أبعاد عالية. لكن مثل هذا المؤشر مع عشرة ملايين متجه فقط من البعد 512 سيزن حوالي 20 جيجابايت وسيأخذ نفس مقدار ذاكرة الوصول العشوائي عند استخدامه.
في مشروع المؤتمر ، استخدمنا فقط مثل هذا النهج الأساسي مع مؤشر مسطح ، كل شيء كان رائعًا بفضل كمية صغيرة نسبيًا من البيانات ، لكننا نتحدث الآن عن عشرات ومئات الملايين من المتجهات عالية الأبعاد!
قم بتسريع عمليات البحث باستخدام القوائم المقلوبة

المصدر
السمة الرئيسية والأروع من FAISS هي مؤشر IVF أوفهرس الملفات المعكوسة . فكرة الملفات المقلوبة مقتضبة ، وموضحة بشكل جميل على الأصابع :
دعونا نتخيل جيشًا ضخمًا ، يتألف من أكثر المحاربين المتعددين ، الذين يبلغ عددهم ، على سبيل المثال ، 1،000،000 شخص. سيكون من المستحيل قيادة الجيش بأكمله في الحال. كما هو معتاد في الشؤون العسكرية ، من الضروري تقسيم جيشنا إلى وحدات. دعونا نقسم علىأجزاء متساوية تقريبًا ، واختيار دور القادة كممثل من كل وحدة. وسنحاول إرسال الرسائل المتشابهة قدر الإمكان في الشخصية والأصل والبيانات المادية وما إلى ذلك. المحاربين في وحدة واحدة ، وسوف نختار القائد بحيث يمثل وحدته بأكبر قدر ممكن من الدقة - إنه شخص "متوسط". ونتيجة لذلك ، تم تخفيض مهمتنا من قيادة مليون جندي إلى قيادة 1000 وحدة من خلال قادتهم ، ولدينا فكرة ممتازة عن تكوين جيشنا ، لأننا نعرف ما هو القادة.
هذه هي فكرة مؤشر IVF: نقوم بتجميع مجموعة كبيرة من المتجهات في أجزاء باستخدام خوارزمية k- الوسائلوضع المراسلات مع كل جزء هو مركز متجه هو المركز المختار لمجموعة معينة. سيتم إجراء البحث من خلال الحد الأدنى للمسافة إلى centroid ، وعندها فقط سنبحث عن الحد الأدنى للمسافات بين المتجهات في المجموعة التي تتوافق مع centroid المحدد. معادلة k بالتساويأين - عدد المتجهات في الفهرس ، سنحصل على بحث مثالي على مستويين - أولاً من بين centroid ثم بين المتجهات في كل عنقود. البحث أسرع بكثير من البحث عن القوة الغاشمة ، والذي يحل إحدى مشاكلنا عند العمل مع ملايين المتجهات.

تنقسم مساحة المتجه بطريقة k- يعني إلى مجموعات k. يتم تعيين كل عنقود مركزي.
مثال على الكود:
dim = 512
k = 1000 # “”
quantiser = faiss.IndexFlatL2(dim)
index = faiss.IndexIVFFlat(quantiser, dim, k)
vectors = np.random.random((1000000, dim)).astype('float32') # 1 000 000 “”
أو يمكنك كتابتها بشكل أكثر أناقة ، باستخدام الشيء FAISS المفيد لبناء فهرس:
index = faiss.index_factory(dim, “IVF1000,Flat”)
:
print(index.is_trained) # False.
index.train(vectors) # Train
# , , :
print(index.is_trained) # True
print(index.ntotal) # 0
index.add(vectors)
print(index.ntotal) # 1000000
بعد النظر في هذا النوع من الفهرس بعد Flat ، قمنا بحل إحدى مشاكلنا المحتملة - سرعة البحث ، التي تصبح أبطأ عدة مرات مقارنة بالبحث الكامل.
D, I = index.search(query, topn)
print(I)
print(D)
انتاج |
[[19898 533106 641838 681301 602835 439794 331951]
[654803 472683 538572 126357 288292 835974 308846]
[588393 979151 708282 829598 50812 721369 944102]
[796762 121483 432837 679921 691038 169755 701540]
[980500 435793 906182 893115 439104 298988 676091]]
[[69.88127 71.64444 72.4655 72.54283 72.66737 72.71834 72.83057]
[72.17552 72.28832 72.315926 72.43405 72.53974 72.664055 72.69495]
[67.262115 69.46998 70.08826 70.41119 70.57278 70.62283 71.42067]
[71.293045 71.6647 71.686615 71.915405 72.219505 72.28943 72.29849]
[73.27072 73.96091 74.034706 74.062515 74.24464 74.51218 74.609695]]
ولكن هناك "لكن" واحد - تعتمد دقة البحث ، وكذلك السرعة ، على عدد المجموعات التي تمت زيارتها ، والتي يمكن تعيينها باستخدام معلمة nprobe:
print(index.nprobe) # 1 –
index.nprobe = 16 # -16 top-n
D, I = index.search(query, topn)
print(I)
print(D)
انتاج |
[[ 28707 811973 12310 391153 574413 19898 552495]
[540075 339549 884060 117178 878374 605968 201291]
[588393 235712 123724 104489 277182 656948 662450]
[983754 604268 54894 625338 199198 70698 73403]
[862753 523459 766586 379550 324411 654206 871241]]
[[67.365585 67.38003 68.17187 68.4904 68.63618 69.88127 70.3822]
[65.63759 67.67015 68.18429 68.45782 68.68973 68.82755 69.05]
[67.262115 68.735535 68.83473 68.88733 68.95465 69.11365 69.33717]
[67.32007 68.544685 68.60204 68.60275 68.68633 68.933334 69.17106]
[70.573326 70.730286 70.78615 70.85502 71.467674 71.59512 71.909836]]كما ترون ، بعد زيادة nprobe ، لدينا نتائج مختلفة تمامًا ، تحسنت قمة أصغر المسافات في D.
يمكنك أن تأخذ nprobe مساوٍ لعدد النقط المئوية في الفهرس ، ثم ستكون مكافئة للبحث عن القوة الغاشمة ، وستكون الدقة أعلى ، ولكن سرعة البحث ستنخفض بشكل ملحوظ.
البحث في القرص - على القوائم المقلوبة على القرص
رائع ، لقد حللنا المشكلة الأولى ، والآن نحصل على سرعة بحث مقبولة على عشرات الملايين من المتجهات! ولكن كل هذا لا فائدة منه طالما أن فهرسنا الضخم لا يتناسب مع ذاكرة الوصول العشوائي.
على وجه التحديد لمهمتنا ، فإن الميزة الرئيسية لـ FAISS هي القدرة على تخزين فهارس IV المقلوبة على القرص ، وتحميل البيانات الوصفية فقط في ذاكرة الوصول العشوائي.
كيف ننشئ مثل هذا الفهرس: نقوم بتدريب indexIVF بالمعلمات الضرورية على أكبر قدر ممكن من البيانات التي تدخل في الذاكرة ، ثم نضيف ناقلات إلى الفهرس المدرب في أجزاء (بعد التدريب وليس فقط) ونكتب الفهرس لكل جزء على القرص.
index = faiss.index_factory(512, “,IVF65536, Flat”, faiss.METRIC_L2)يتم التدريب على مؤشر GPU بهذه الطريقة:
res = faiss.StandardGpuResources()
index_ivf = faiss.extract_index_ivf(index)
index_flat = faiss.IndexFlatL2(512)
clustering_index = faiss.index_cpu_to_gpu(res, 0, index_flat) # 0 – GPU
index_ivf.clustering_index = clustering_indexيمكن استبدال faiss.index_cpu_to_gpu (الدقة ، 0 ، index_flat) بـ faiss.index_cpu_to_all_gpus (index_flat) لاستخدام جميع وحدات معالجة الرسومات معًا.
من المستحسن للغاية أن تكون عينة التدريب ممثلة قدر الإمكان ولديها توزيع موحد ، لذلك نقوم بتكوين مجموعة بيانات التدريب مقدمًا من العدد المطلوب من المتجهات ، ونختارها عشوائيًا من مجموعة البيانات بأكملها.
train_vectors = ... #
index.train(train_vectors)
# , :
faiss.write_index(index, "trained_block.index")
#
# :
for bno in range(first_block, last_block+ 1):
block_vectors = vectors_parts[bno]
block_vectors_ids = vectors_parts_ids[bno] # id ,
index = faiss.read_index("trained_block.index")
index.add_with_ids(block_vectors, block_vectors_ids)
faiss.write_index(index, "block_{}.index".format(bno))
بعد ذلك ، نجمع كل القوائم المقلوبة معًا. هذا ممكن ، لأن كل من الكتل ، في الواقع ، هو نفس المؤشر المدرب ، فقط مع ناقلات مختلفة في الداخل.
ivfs = []
for bno in range(first_block, last_block+ 1):
index = faiss.read_index("block_{}.index".format(bno), faiss.IO_FLAG_MMAP)
ivfs.append(index.invlists)
# index inv_lists
# :
index.own_invlists = False
# :
index = faiss.read_index("trained_block.index")
# invlists
# invlists merged_index.ivfdata
invlists = faiss.OnDiskInvertedLists(index.nlist, index.code_size, "merged_index.ivfdata")
ivf_vector = faiss.InvertedListsPtrVector()
for ivf in ivfs:
ivf_vector.push_back(ivf)
ntotal = invlists.merge_from(ivf_vector.data(), ivf_vector.size())
index.ntotal = ntotal #
index.replace_invlists(invlists)
faiss.write_index(index, data_path + "populated.index") #
خلاصة القول: الآن مؤشر لدينا هو populated.index و merged_blocks.ivfdata الملفات .
في populated.index سجلت المسار الكامل الأصلي للملف باستخدام القوائم المقلوبة ، لذلك إذا كان مسار الملف ivfdata لسبب ما ، فإن التغيير في قراءة الفهرس سيحتاج إلى استخدام إشارة faiss.IO_FLAG_ONDISK_SAME_DIR ، مما يسمح لك بالبحث في ملف ivfdata في نفس الدليل مثل مأهولة. مؤشر:
index = faiss.read_index('populated.index', faiss.IO_FLAG_ONDISK_SAME_DIR)
تم أخذ المثال التجريبي من مشروع Github FAISS كأساس .
يمكن العثور على دليل صغير لاختيار فهرس في FAISS Wiki . على سبيل المثال ، تمكنا من احتواء مجموعة بيانات تدريبية مكونة من 12 مليون متجه في ذاكرة الوصول العشوائي ، لذلك اخترنا مؤشر IVFFlat عند 262144 سنترويد لتتحول بعد ذلك إلى مئات الملايين. يُقترح أيضًا استخدام الفهرس IVF262144_HNSW32 في الدليل ، حيث يتم تحديد انتماء متجه لمجموعة ما بواسطة خوارزمية HNSW مع 32 جارًا قريبًا (بعبارة أخرى ، باستخدام مؤشر التكليس HNSWFlat) ، ولكن ، كما بدا لنا في المزيد من الاختبارات ، البحث عن طريق هذا المؤشر أقل دقة. بالإضافة إلى ذلك ، يجب أن يوضع في الاعتبار أن مثل هذا المحدد يستبعد إمكانية استخدامه على GPU.
المفسد:
قلل بشكل كبير من استخدام القرص مع تكمية المنتج
بفضل طريقة البحث عن القرص ، كان من الممكن إزالة الحمل من ذاكرة الوصول العشوائي ، ولكن الفهرس الذي يحتوي على مليون متجه لا يزال يشغل حوالي 2 غيغابايت من مساحة القرص ، ونحن نناقش إمكانية العمل مع مليارات المتجهات ، الأمر الذي يتطلب أكثر من اثنين تيرابايت! بالطبع ، الحجم ليس كبيرًا إذا قمت بتعيين هدف وتخصيص مساحة إضافية على القرص ، لكنه أزعجنا قليلاً.
وهنا يأتي الترميز ناقلات، وهي عددي تكميم (SQ) و المنتج تكميم (PQ)... SQ - تشفير كل مكون للمتجه في n بت (عادة 8 أو 6 أو 4 بت). سننظر في خيار PQ ، لأن فكرة تشفير مكون واحد من النوع float32 بثمانية بت تبدو محبطة للغاية من حيث الدقة. على الرغم من أنه في بعض الحالات ، فإن ضغط SQfp16 لكتابة float16 سيكون تقريبًا بدون فقد في الدقة.
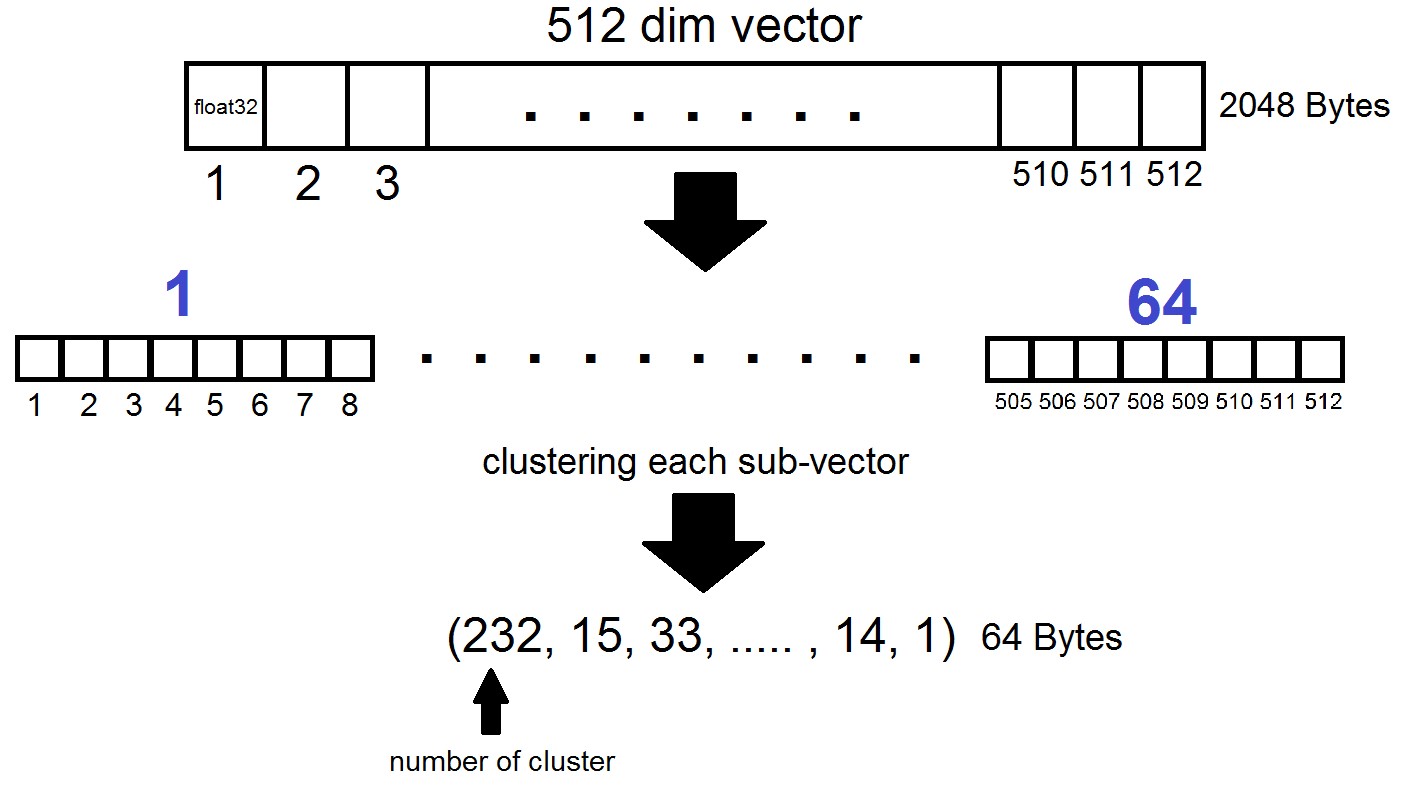
جوهر كمية المنتج هو كما يلي: يتم تقسيم ناقلات البعد 512 إلى أجزاء n ، كل منها يتجمع في 256 مجموعات ممكنة (1 بايت) ، أي نحن نمثل متجهًا بـ n بايت ، حيث يكون n عادةً 64 على الأكثر في تنفيذ FAISS. لكن مثل هذا التحديد لا يتم تطبيقه على المتجهات نفسها من مجموعة البيانات ، ولكن على الاختلافات بين هذه المتجهات والنسب المئوية المركزية المقابلة التي تم الحصول عليها في مرحلة إنشاء القوائم المقلوبة! اتضح أن القوائم المقلوبة ستكون مجموعات مشفرة من المسافات بين النواقل ونقاطها المركزية.
index = faiss.index_factory(dim, "IVF262144,PQ64", faiss.METRIC_L2)اتضح أننا الآن لسنا بحاجة إلى تخزين جميع المتجهات - يكفي تخصيص n بايت لكل متجه و 2048 بايت لكل متجه سنترويد. في حالتنا ، أخذنا، بمعنى آخر - طول ناقل واحد ، يتم تحديده في واحدة من 256 مجموعة.
عند البحث عن طريق المتجه x ، سيتم تحديد أقرب نقطتين مركزيتين أولاً باستخدام المكثف المسطح المعتاد ، ثم يتم تقسيم x أيضًا إلى نواقل فرعية ، يتم ترميز كل منها برقم واحد من 256 النقط المركزية المقابلة. والمسافة إلى المتجه محددة كمجموع 64 مسافة بين المتجهات الفرعية.
ما هو الحد الأدنى؟
أوقفنا تجاربنا على مؤشر "IVF262144، PQ64" ، لأنه يلبي تمامًا جميع احتياجاتنا لسرعة ودقة البحث ، ويضمن أيضًا الاستخدام المعقول لمساحة القرص مع زيادة تحجيم المؤشر. وبشكل أكثر تحديدًا ، في الوقت الحالي ، مع 315 مليون متجه ، يشغل المؤشر 22 غيغابايت من مساحة القرص وحوالي 3 غيغابايت من ذاكرة الوصول العشوائي عند استخدامه.
تفاصيل أخرى مثيرة للاهتمام لم نذكرها سابقًا هي المقياس الذي يستخدمه الفهرس. بشكل افتراضي ، يتم حساب المسافات بين أي متجهين بمقياس Euclidean L2 ، أو بلغة أكثر قابلية للفهم ، يتم حساب المسافات على أنها الجذر التربيعي لمجموع مربعات اختلافات الإحداثيات الحكيمة. ولكن يمكنك تحديد مقياس آخر ، على وجه الخصوص ، اختبرنا المقياس METRIC_INNER_PRODUCTأو مقياس مسافات جيب التمام بين المتجهات. إنه جيب التمام لأن جيب التمام للزاوية بين متجهين في نظام الإحداثيات الإقليدية يتم التعبير عنه كنسبة المنتج المتجهي (الإحداثيات الحكيمة) إلى منتج أطوالها ، وإذا كانت جميع المتجهات في فضاءنا بطول 1 ، فإن جيب تمام الزاوية سيكون مساوياً تمامًا لمنتج التنسيق الحكيم. في هذه الحالة ، كلما كانت المتجهات أقرب في الفضاء ، كلما اقتربت الوحدة من منتجها القياسي.
يحتوي مقياس L2 على انتقال رياضي مباشر إلى مقياس منتج النقطة. ومع ذلك ، عند المقارنة التجريبية بين المقياسين ، كان الانطباع هو أن مقياس المنتجات العددية يساعدنا على تحليل معاملات التشابه للصور بطريقة أكثر نجاحًا. بالإضافة إلى ذلك ، تم الحصول على تضمين صورنا باستخدامInsightFace ، الذي ينفذ بنية ArcFace باستخدام مسافات جيب التمام. هناك أيضًا مقاييس أخرى في فهارس FAISS يمكنك القراءة عنها هنا .
بضع كلمات حول GPU
الخلاصة وأمثلة مثيرة للاهتمام
لذا ، عد إلى حيث بدأ كل شيء. وبدأ ، على سبيل التذكير ، بدافع حل مشكلة العثور على برامج الروبوت على شبكة Instagram ، وبشكل أكثر تحديدًا - للبحث عن مشاركات مكررة مع أشخاص أو صور رمزية في مجموعات معينة من المستخدمين. في عملية كتابة المادة ، أصبح من الواضح أن الوصف التفصيلي لمنهجية البحث عن الروبوتات الخاص بنا قد تم رسمه إلى مقالة منفصلة ، والتي سنناقشها في المنشورات المستقبلية ، ولكن في الوقت الحالي سنقتصر على أمثلة تجاربنا مع FAISS.
يمكنك توجيه الصور أو الوجوه بطرق مختلفة ، لقد اخترنا تقنية InsightFace (يعد تحويل الصور واستخراج الميزات ذات الأبعاد n منها قصة طويلة منفصلة). في سياق التجارب على البنية التحتية التي حصلنا عليها ، تم اكتشاف خصائص مثيرة للاهتمام ومضحكة.
على سبيل المثال ، بعد أن حصلنا على إذن الزملاء والمعارف ، قمنا بتحميل وجوههم في البحث وسرعان ما وجدنا الصور التي يتواجدون فيها:

حصل زميلنا على صورة لزائر كوميك كون في الخلفية في حشد من الناس.

نزهة مصدر في مجموعة كبيرة من الأصدقاء ، صورة من حساب صديق. المصدر

يمر فقط. القبض على مصور مجهول الرجال لملف تعريفه المواضيعي. لم يعرفوا إلى أين ذهبت صورتهم ، وبعد 5 سنوات نسوا تمامًا كيف تم تصويرهم. المصدر

في هذه الحالة المصور غير معروف وتم تصويره سرا!
تذكرت على الفور الفتاة المشبوهة مع SLR ، وهي تجلس في الوقت الحالي أمام :) Source
وهكذا ، من خلال إجراءات بسيطة ، يسمح لك FAISS بتجميع تناظري لـ FindFace المعروف على ركبتك.
ميزة أخرى مثيرة للاهتمام: في مؤشر FAISS ، كلما كانت الوجوه متشابهة أكثر ، كلما كانت أقرب إلى بعضها البعض هي المتجهات المقابلة في الفضاء. قررت أن ألقي نظرة فاحصة على نتائج البحث الأقل دقة قليلاً لوجهي ووجدت استنساخًا مشابهًا بشكل رهيب :)

بعض استنساخ المؤلف.
مصادر الصور: 1 ، 2 ، 3
بشكل عام ، يفتح FAISS مجالًا ضخمًا لتنفيذ أي أفكار إبداعية. على سبيل المثال ، باستخدام نفس مبدأ قرب المتجه لوجوه متشابهة ، يمكن للمرء أن يبني مسارات من شخص إلى آخر. أو ، كملاذ أخير ، قم بإنشاء مصنع لإنتاج هذه الميمات من FAISS:

المصدر
أشكركم على اهتمامكم ونأمل أن تكون هذه المادة مفيدة لقراء هبر!
تمت كتابة هذه المقالة بدعم من زملائي أرتيوم كوروليوف (korolevart) وتيمور قديروف وأرينا ريشتنيكوفا.
R&D Dentsu Aegis Network روسيا.