int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}هذا تطبيق بسيط مخصص للتجارب ، فهو يبحث عن الأعداد الأولية باستخدام غربال إراتوستينس . لنقم بتشغيل الحل 20 مرة ونحسب وقت المستخدم لكل تنفيذ.
وصف مقعد الاختبار
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
مبعثر وقت التنفيذ قبل التحسينات:
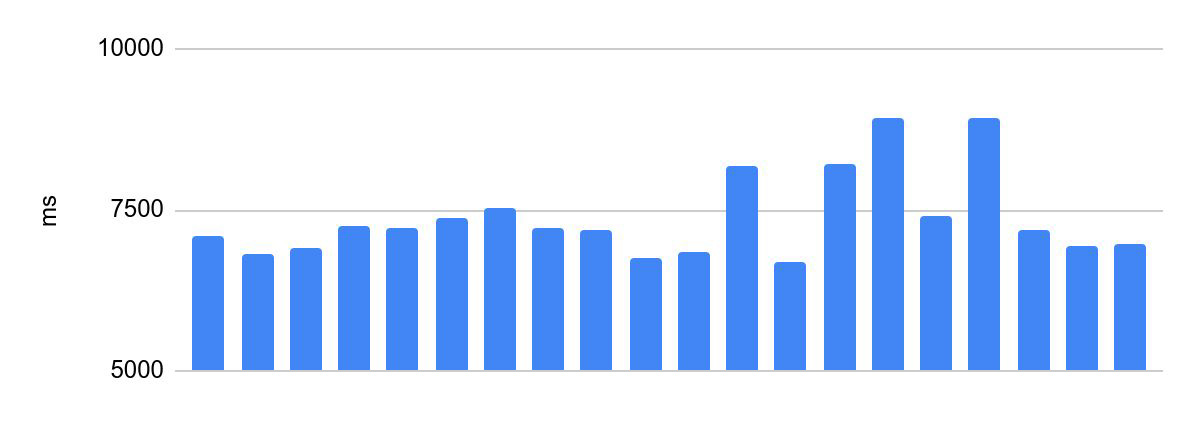
الفرق بين التنفيذ الأسرع والأبطأ هو 2230 مللي ثانية.
هذا غير مقبول لبرمجة الأولمبياد. وقت تنفيذ كود المشارك هو أحد معايير نجاح حله وأحد شروط المسابقة توزيع الجوائز يعتمد على ذلك. لذلك ، هناك مطلب مهم لمثل هذه الأنظمة - نفس وقت التحقق لنفس الرمز. فيما يلي ، سوف نسمي هذا تناسق تنفيذ الكود.
دعنا نحاول مواءمة وقت التنفيذ.
العزلة الأساسية
لنبدأ بما هو واضح. تتنافس العمليات على النوى ، وتحتاج بطريقة ما إلى عزل النواة لتنفيذ الحل. بالإضافة إلى ذلك ، مع تمكين Hyper Threading ، يحدد نظام التشغيل نواة معالج ماديًا واحدة على أنها نواتان منطقية منفصلة. لعزل النواة بصدق ، نحتاج إلى تعطيل Hyper Threading. يمكن القيام بذلك في إعدادات BIOS.
يدعم Linux kernel out-of-the-box علامة بدء التشغيل لعزل النواة المعزولة. أضف هذه العلامة إلى GRUB_CMDLINE_LINUX_DEFAULT في إعدادات اليرقة: / etc / default / grub. على سبيل المثال: قم
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
بتشغيل update-grub وأعد تشغيل النظام.
يبدو كل شيء كما هو متوقع - لا يستخدم النظام أول نواة:

لنبدأ بنواة معزولة. يسمح لك تكوين CPU Affinity بربط عملية بنواة معينة. هناك عدة طرق للقيام بذلك. على سبيل المثال ، لنقم بتشغيل الحل في حاوية porto (يتم تحديد kernel باستخدام وسيطة cpu_set):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: نستخدم QEMU-KVM لتشغيل الحلول في الإنتاج. تُستخدم حاوية البورتو في جميع أنحاء هذه المقالة لتسهيل عرضها.
بدء التشغيل بنواة مخصصة للحل ، بدون تحميل نواة مجاورة:

الفارق 375 مللي ثانية. لقد تحسنت ، لكنها ما زالت كثيرة جدًا.
أداء Tyunim
لنجرب اختبار التحمل. أي واحدة؟ مهمتنا هي تحميل جميع النوى بخيوط متعددة. ويمكن القيام بذلك بعدة طرق:
- اكتب تطبيقًا بسيطًا من شأنه إنشاء العديد من سلاسل الرسائل والبدء في حساب شيء ما في كل منها.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
الانطلاق بنواة مخصصة للحل ، مع حمل على النوى المجاورة:

الفرق هو 1354 مللي ثانية: ثانية واحدة أكثر من بدون حمل. من الواضح أن الحمل أثر على وقت التنفيذ ، على الرغم من حقيقة أننا كنا نعمل على نواة معزولة. يمكن ملاحظة أنه في لحظة معينة انخفض وقت التنفيذ. للوهلة الأولى ، هذا غير بديهي: مع زيادة الحمل ، يزداد الأداء أيضًا.
في الإنتاج ، قد يكون إطلاق هذا السلوك (عندما يبدأ وقت التنفيذ في التعويم تحت الحمل) مؤلمًا للغاية. ما هو الحمل في هذه الحالة؟ تيار من القرارات من المشاركين ، غالبًا في المسابقات الكبرى والأولمبياد.
والسبب هو أن Intel Turbo Boost يتم تنشيطه تحت الحمل - وهي تقنية لزيادة التردد. قم بتعطيله. بالنسبة لموقفي ، قمت أيضًا بإيقاف تشغيل SpeedStep... بالنسبة لمعالج AMD ، يجب إيقاف تشغيل Turbo Core Cool'n'Quiet. كل ما سبق يتم في BIOS ، والفكرة الرئيسية هي تعطيل ما يتحكم تلقائيًا في تردد المعالج.
يعمل على نواة معزولة مع تعطيل Turbo Boost

وتحميله على النوى المجاورة: يبدو جيدًا ، لكن الفرق لا يزال 252 مللي ثانية. ولا يزال هذا كثيرًا.
Offtop: لاحظ كيف انخفض متوسط وقت التنفيذ بنحو 25٪. في الحياة اليومية ، تعتبر التقنيات المعوقة جيدة.
تخلصنا من المنافسة على النوى ، واستقرنا التردد الأساسي - والآن لا شيء يؤثر عليهم. إذن من أين يأتي الاختلاف؟
نما
الوصول غير الموحد للذاكرة ، أو بنية الذاكرة غير الموحدة ، "بنية ذات ذاكرة غير متساوية." في أنظمة NUMA (أي تقليديًا ، على أي كمبيوتر حديث متعدد المعالجات) ، يحتوي كل معالج على ذاكرة محلية ، والتي تعتبر جزءًا من الإجمالي. يمكن لكل معالج الوصول إلى كل من ذاكرته المحلية والذاكرة المحلية للمعالجات الأخرى (الذاكرة البعيدة). يتمثل التفاوت في أن الوصول إلى الذاكرة المحلية أسرع بشكل ملحوظ.
وقت الأداء "يمشي" على وجه التحديد بسبب هذا التفاوت. دعنا نصلحها من خلال ربط التنفيذ الخاص بنا بعقدة رقمية معينة. للقيام بذلك ، أضف عقدة رقمية إلى تكوين حاوية porto:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0يعمل على نواة معزولة مع تعطيل Turbo Boost ، وتكوين NUMA وتحميل على النوى المجاورة:
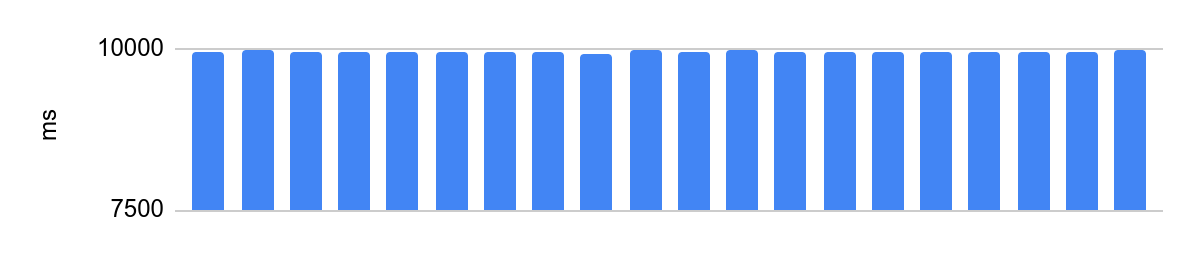
الفرق هو 48 مللي ثانية ، ومتوسط وقت التنفيذ بعد تعطيل تحسينات المعالج هو 10 ثوانٍ. 48 مللي ثانية عند 10 ثوانٍ يعادل خطأ 0.5٪ ، جيد جدًا.
مفسد مهم
أكثر قليلا عن العزلة
توجد مشكلة في علامة العزلة: لا يزال بإمكان بعض سلاسل عمليات النظام الجدولة إلى نواة معزولة.
لذلك ، في الإنتاج ، نستخدم نواة مصححة بوظائف موسعة لهذه العلامة. وبالتالي ، نختار النواة ، مع مراعاة العلم ، عند حدوث جدولة الخيوط.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
خطط للمستقبل
التجمعات
إذا كانت إحدى الأجهزة الحاسمة أقوى من الأخرى ، فلن يساعدك أي قدر من تعديلات العزل الأساسية - ونتيجة لذلك ، سنظل نحصل على فرق كبير في وقت التنفيذ. لذلك ، عليك التفكير في البيئات غير المتجانسة. حتى الآن ، لم نؤيد عدم التجانس - تم تجهيز أسطول آلات القرار بالكامل بنفس الأجهزة. ولكن في المستقبل القريب ، سنبدأ في تقسيم الأجهزة غير المتشابهة إلى مجموعات متجانسة ، وستقام كل مسابقة ضمن نفس المجموعة بنفس الأجهزة.
الانتقال إلى السحابة
سيكون التحدي الجديد للنظام هو الحاجة إلى الإطلاق في Yandex.Cloud. وفقًا لمعايير اليوم ، لا يمكن الاعتماد على الخوادم الحديدية ، وهي خطوة ضرورية ، ولكن من المهم الحفاظ على الاتساق في تنفيذ الطرود. هنا لا تزال الإمكانيات التقنية قيد التحقيق. هناك فكرة مفادها أنه ، في الحالات القصوى ، يمكن للآلات السحابية تشغيل حلول لا تتطلب وقت تنفيذ صارمًا. وبالتالي ، سنقلل الحمل على ماكينات الحديد ولن يتعاملوا إلا مع الحلول التي تتطلب الاتساق فقط. هناك خيار آخر: تحقق أولاً من الطرد في السحابة ، وإذا لم يستوف الحد الزمني ، فأعد فحصه على جهاز حقيقي.
جمع الإحصائيات
حتى بعد كل التعديلات ، ستختنق المعالجات حتمًا. لتقليل التأثير السلبي ، سننفذ الحلول بالتوازي ، ونقارن النتائج ، وإذا كانت مختلفة ، فقم بإعادة فحصها. بالإضافة إلى ذلك ، إذا كانت إحدى الآلات الحاسمة مهينة باستمرار ، فهذا عذر لإخراجها من الخدمة والتعامل مع الأسباب.
الاستنتاجات
تتميز المسابقة بخصوصية - قد يبدو أن الأمر كله يتعلق ببساطة بتشغيل الكود والحصول على النتيجة. في هذا المقال ، كشفت عن جانب صغير واحد فقط من هذه العملية. هناك شيء مثل هذا في كل طبقة من الخدمة.