المقدمة
مرحبا هبر!
أحب الكثير من الأشخاص الجزء السابق ، لذلك قمت مرة أخرى بتجريف نصف وثائق التعزيز ووجدت شيئًا أكتب عنه. من الغريب جدًا أنه لا يوجد مثل هذا الإثارة حول Boost.compute كما هو الحال حول boost.asio. بعد كل شيء ، يكفي أن تكون هذه المكتبة مشتركة بين الأنظمة الأساسية ، كما أنها توفر واجهة ملائمة (ضمن إطار c ++) للتفاعل مع الحوسبة المتوازية على وحدة معالجة الرسومات ووحدة المعالجة المركزية.
كل الأجزاء
- الجزء الأول
- الجزء 2
المحتوى
- العمليات غير المتزامنة
- وظائف مخصصة
- مقارنة سرعة الأجهزة المختلفة في أوضاع مختلفة
- خاتمة
العمليات غير المتزامنة
يبدو أسرع بكثير؟ تتمثل إحدى طرق تسريع عملك مع الحاويات في مساحة اسم الحساب في استخدام وظائف غير متزامنة. يوفر لنا Boost.compute العديد من الأدوات. من بينها ، فئة compute :: future للتحكم في استخدام الدوال و copy_async () و fill_async () لنسخ أو تعبئة المصفوفة. بالطبع ، هناك أيضًا أدوات للعمل مع الأحداث ، لكن لا داعي لأخذها في الاعتبار. سيكون ما يلي مثالاً على استخدام كل ما سبق:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
لا يوجد شيء خاص يمكن شرحه هنا. الأسطر الثلاثة الأولى هي التهيئة القياسية للفئات الضرورية ، ثم متجهين للنسخ ، ناقل للتعبئة ، متغير منها سيملأ المتجه السابق ووظائف التعبئة والنسخ مباشرة ، على التوالي. ثم ننتظر إعدامهم.
بالنسبة لأولئك الذين عملوا مع std :: future from STL ، كل شيء هو نفسه هنا ، فقط في مساحة اسم مختلفة ولا يوجد تناظرية لـ std :: async ().
وظائف مخصصة للحسابات
في الجزء السابق ، قلت إنني سأشرح كيفية استخدام طرقي الخاصة لمعالجة مجموعة البيانات. حسبت 3 طرق للقيام بذلك: استخدم الماكرو ، واستخدم make_function_from_source <> () واستخدم إطار عمل خاصًا لتعبيرات lambda.
سأبدأ بالخيار الأول - ماكرو. أولاً سوف أرفق نموذج كود وبعد ذلك سأشرح كيف يعمل.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
الوسيطة الأولى هي نوع القيمة المعادة ، ثم اسم الوظيفة ، وسيطاتها وجسم الوظيفة. علاوة على ذلك ، تحت الاسم add ، يمكن استخدام هذه الوظيفة ، على سبيل المثال ، في وظيفة compute :: transform (). استخدام هذا الماكرو مشابه جدًا لتعبير لامدا العادي ، لكنني تحققت من أنها لن تعمل.
الطريقة الثانية وربما الأكثر صعوبة تشبه إلى حد بعيد الطريقة الأولى. لقد ألقيت نظرة على كود الماكرو السابق واتضح أنه يستخدم الطريقة الثانية.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
هنا يكون كل شيء أكثر وضوحًا مما قد يبدو للوهلة الأولى ، تستخدم الدالة make_function_from_source () وسيطين فقط ، إحداهما اسم الوظيفة ، والثانية هي تنفيذها. بعد التصريح عن دالة ، يمكن استخدامها بنفس الطريقة بعد تطبيق الماكرو.
حسنًا ، الخيار الأخير هو إطار تعبير lambda. مثال على الاستخدام:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
كحجة رابعة ، نشير إلى أننا نريد ضرب كل عنصر من المتجه الأول في 2 ، كل شيء بسيط للغاية ويتم تنفيذه في مكانه.
يمكن تحديد التعبيرات المنطقية بنفس الطريقة. على سبيل المثال ، في طريقة compute :: count_if ():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
وهكذا ، قمنا بحساب جميع الأرقام الزوجية في المصفوفة ، وسوف يساوي العداد واحدًا.
مقارنة سرعة الأجهزة المختلفة في أوضاع مختلفة
حسنًا ، آخر شيء أود كتابته في هذه المقالة هو مقارنة سرعة المعالجة على أجهزة مختلفة وفي أوضاع مختلفة (فقط لوحدة المعالجة المركزية). ستثبت هذه المقارنة عندما يكون من المنطقي استخدام وحدات معالجة الرسومات للحوسبة والحوسبة المتوازية بشكل عام.
سأختبر مثل هذا: باستخدام الحوسبة لجميع الأجهزة ، سأقوم باستدعاء دالة compute :: sort () لفرز مصفوفة من 100 مليون قيمة عائمة. لاختبار الوضع المفرد ، استدعِ std :: sort على مصفوفة من نفس الحجم. بالنسبة لكل جهاز ، سأذكر الوقت بالمللي ثانية باستخدام مكتبة chrono القياسية وأخرج كل شيء إلى وحدة التحكم.
والنتيجة هي ما يلي:

الآن سأفعل الشيء نفسه فقط لألف قيمة. هذه المرة سيكون الوقت بالميكروثانية.

هذه المرة كان المعالج في وضع الخيط المفرد متقدمًا على الجميع. من هذا نستنتج أن هذا النوع من العمليات يستحق القيام به فقط عندما يتعلق الأمر بالبيانات الضخمة حقًا.
أود إجراء المزيد من الاختبارات ، لذلك دعونا نجري اختبارًا لحساب جيب التمام والجذر التربيعي والتربيع.
عند حساب جيب التمام ، يكون الاختلاف كبيرًا جدًا (تعمل وحدة معالجة الرسومات 60 مرة أسرع من وحدة المعالجة المركزية في مؤشر ترابط واحد).
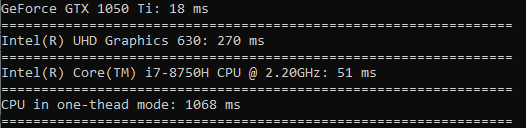
يُحسب الجذر التربيعي بنفس سرعة الفرز تقريبًا.
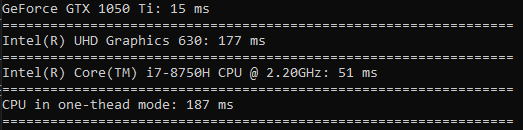
الوقت الذي يقضيه في التربيع أقل فرقًا من الفرز (GPU أسرع 3.5 مرة فقط).

خاتمة
لذلك ، بعد قراءة هذه المقالة ، تعلمت كيفية استخدام الوظائف غير المتزامنة لنسخ المصفوفات وتعبئتها. لقد تعلمنا كيف يمكنك استخدام وظائفك الخاصة لإجراء العمليات الحسابية على البيانات. كما رأيت بوضوح متى يستحق استخدام وحدة معالجة الرسومات أو وحدة المعالجة المركزية للحوسبة المتوازية ، ومتى يمكنك الحصول عليها بخيط واحد.
سأكون سعيدًا لتلقي ردود فعل إيجابية ، شكرًا على وقتك!
حظا موفقا للجميع!