1 ما هي مخطوطة فوينيتش؟
مخطوطة فوينيتش هي مخطوطة غامضة (مجلد مخطوطة ، مخطوطة أو مجرد كتاب) في 240 صفحة وصلت إلينا ، على الأرجح ، من القرن الخامس عشر. تم الحصول على المخطوطة بالصدفة من أحد الأثريات من قبل زوج الكاتب الكربوني الشهير إثيل فوينيتش - ويلفريد فوينيتش - في عام 1912 وسرعان ما أصبحت ملكًا لعامة الناس.
لم يتم تحديد لغة المخطوطة بعد. يقترح عدد من الباحثين في المخطوطة أن نص المخطوطة مشفر. والبعض الآخر على يقين من أن المخطوطة كتبت بلغة لم تنج من النصوص التي نعرفها اليوم. لا يزال آخرون يعتبرون مخطوطة فوينيتش مجرد هراء (انظر الترنيمة الحديثة للعبثية Codex Seraphinianus ).
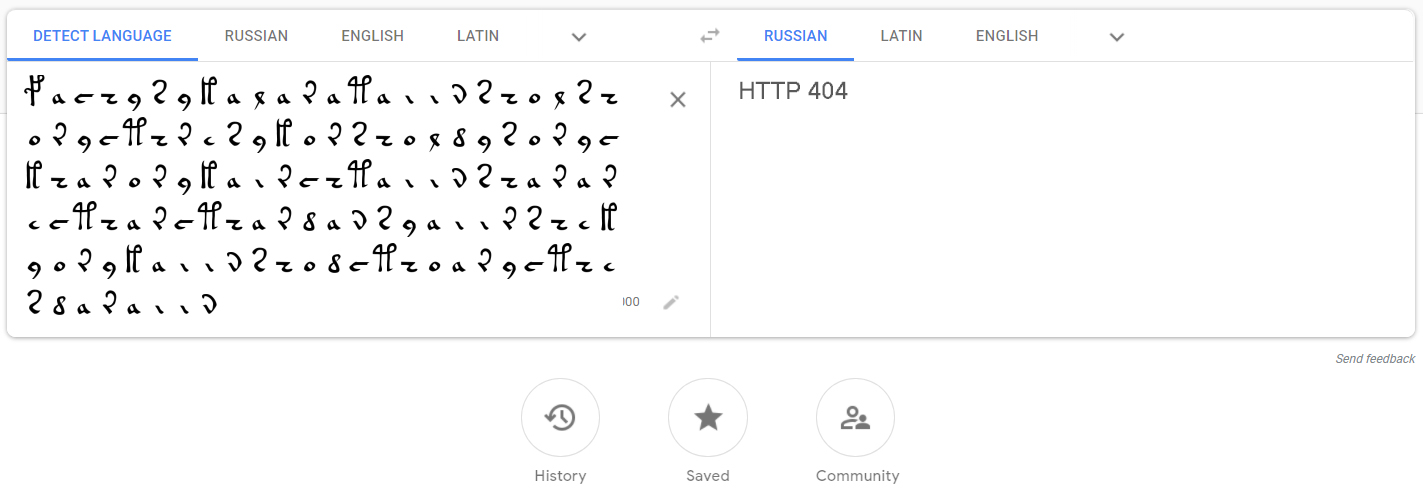
كمثال ، سأقدم جزءًا ممسوحًا ضوئيًا من موضوع يحتوي على نص وحوريات:

2 لماذا هذه المخطوطة الغريبة مثيرة للاهتمام؟
ربما هذا هو التزوير في وقت متأخر؟ على ما يبدو لا. على عكس كفن تورينو ، لم يعطِ تحليل الكربون المشع ولا المحاولات الأخرى لمعارضة العصور القديمة للرق إجابة لا لبس فيها. لكن فوينيتش لم يكن بإمكانه التنبؤ بتحليل النظائر في بداية القرن العشرين ...
لكن ماذا لو كانت المخطوطة عبارة عن مجموعة لا معنى لها من الحروف من قلم راهب لعوب ، رجل نبيل في وعي متغير؟ لا بالتأكيد لا. الضغط على المفاتيح بلا عقل ، سأقوم ، على سبيل المثال ، بتصوير الضوضاء البيضاء المألوفة للوحة مفاتيح QWERTY- Keyboard مثل " asfds dsf". يظهر الفحص الخطي أن المؤلف كتب بيده الثابتة رموز الأبجدية المعروفة لديه. بالإضافة إلى ذلك ، فإن ارتباط توزيع الأحرف والكلمات في نص المخطوطة يتوافق مع النص "الحي". على سبيل المثال ، في مخطوطة ، مقسمة شرطيًا إلى 6 أقسام ، توجد كلمات - "مستوطنة" ، غالبًا ما توجد في أحد الأقسام ، ولكنها غائبة في الأقسام الأخرى.
ولكن ماذا لو كانت المخطوطة عبارة عن تشفير معقد ، ومحاولات كسرها لا معنى لها نظريًا؟ إذا أخذنا بالإيمان العصر الجليل للنص ، فمن غير المحتمل للغاية إصدار التشفير. كان من الممكن أن تقدم العصور الوسطى فقط شفرة بديلة ، والتي كسرها إدغار آلان بو بسهولة وبأناقة . مرة أخرى ، فإن الارتباط بين الحروف والكلمات في النص ليس نموذجيًا بالنسبة للغالبية العظمى من الأصفار.
على الرغم من النجاح الهائل في ترجمة النصوص القديمة ، بما في ذلك استخدام موارد الحوسبة الحديثة ، لا تزال مخطوطة Voynich تتحدى اللغويين المحترفين ذوي الخبرة أو علماء البيانات الشباب الطموحين.
3 ولكن ماذا لو كانت لغة المخطوطة معروفة لنا
... لكن الإملاء مختلف؟ من ، على سبيل المثال ، يتعرف على اللاتينية في هذا النص ؟

وهنا مثال آخر - الترجمة الصوتية لنص إنجليزي إلى اليونانية:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονمكتبة لغة بايثون الصوتية . ملاحظة: لم يعد هذا تشفيرًا بديلاً - يتم إرسال بعض التركيبات متعددة الأحرف في حرف واحد والعكس صحيح.
سأحاول تحديد (تصنيف) لغة المخطوطة ، أو العثور على الأقرب بالنسبة لها من اللغات المعروفة ، وإبراز السمات المميزة وتدريب النموذج عليها:
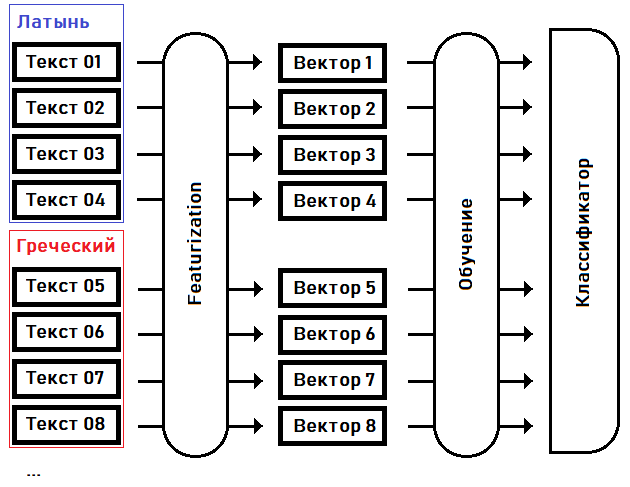
في المرحلة الأولى - التوصيف- نقوم بتحويل النصوص إلى متجهات خاصية: مصفوفات ذات حجم ثابت من أرقام حقيقية ، حيث يكون كل بُعد من أبعاد المتجه مسؤولاً عن ميزته الخاصة (ميزة) للنص المصدر. على سبيل المثال ، دعونا نتفق في البعد الخامس عشر للمتجه على الحفاظ على تكرار استخدام الكلمة الأكثر شيوعًا في النص ، في البعد السادس عشر - ثاني أكثر الكلمات شيوعًا ... في البعد N - أقصى طول لسلسلة من نفس الكلمة المكررة ، إلخ.
في الخطوة الثانية - التدريب - نختار معاملات المصنف بناءً على المعرفة المسبقة للغة كل نص.
بمجرد تدريب المصنف ، يمكننا استخدام هذا النموذج لتحديد لغة النص التي لم يتم تضمينها في عينة التدريب. على سبيل المثال ، لنص مخطوطة فوينيتش.
4 الصورة بسيطة للغاية - ما الفائدة؟
الجزء الصعب هو كيفية تحويل ملف نصي إلى متجه. فصل الحنطة عن القشر وترك فقط الخصائص المميزة للغة ككل وليس لكل نص معين.
للتبسيط ، إذا حولت النصوص المصدر إلى ترميز (أي أرقام) ، و "تغذية" هذه البيانات كما هي في أحد نماذج الشبكات العصبية العديدة ، فمن المحتمل ألا ترضينا النتيجة. على الأرجح ، سيتم ربط نموذج تم تدريبه على مثل هذه البيانات بالأبجدية وسيكون على أساس الرموز ، أولاً وقبل كل شيء ، سيحاول تحديد لغة نص غير معروف.
لكن أبجدية المخطوطة "ليس لها نظائرها". علاوة على ذلك ، لا يمكننا الاعتماد بشكل كامل على الأنماط في توزيع الحروف. من الناحية النظرية ، من الممكن أيضًا نقل صوتيات إحدى اللغات وفقًا لقواعد لغة أخرى ( اللغة هي Elvish - والرونية هي Mordor).
لم يستخدم الناسخ الماكر أي علامات ترقيم أو أرقام كما نعرفها. يمكن اعتبار كل النص بمثابة تيار من الكلمات ، مقسم إلى فقرات. لا يوجد حتى يقين حول أين تنتهي جملة وتبدأ أخرى.
هذا يعني أننا سنرتقي إلى مستوى أعلى فيما يتعلق بالحروف وسنعتمد على الكلمات. سنقوم بتجميع قاموس بناءً على نص المخطوطة وتتبع الأنماط الموجودة بالفعل على مستوى الكلمة.
5 النص الأصلي للمخطوطة
بالطبع ، لا تحتاج إلى ترميز الأحرف المعقدة لمخطوطة فوينيتش في مكافئاتها في Unicode والعكس بالعكس بنفسك - لقد تم بالفعل هذا العمل لنا ، على سبيل المثال ، هنا . باستخدام الخيارات الافتراضية ، أحصل على المكافئ التالي للسطر الأول من المخطوطة:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-النقاط وعلامات التعجب (بالإضافة إلى عدد من الرموز الأخرى لأبجدية EVA ) هي مجرد فواصل ، والتي لأغراضنا يمكن استبدالها بمسافات. علامات الاستفهام والعلامات النجمية هي كلمات / أحرف غير معروفة.
للتحقق ، دعنا نستبدل النص هنا ونحصل على جزء من المخطوطة:
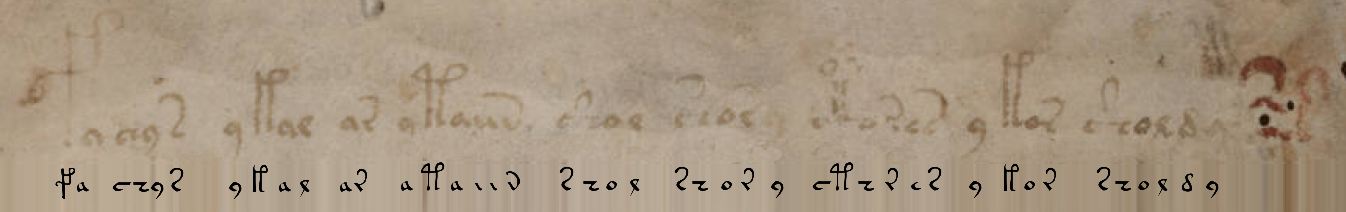
6 برنامج - مصنف النص (بايثون)
فيما يلي رابط إلى مستودع الكود مع الحد الأدنى من تلميحات README التي تحتاجها لاختبار الكود أثناء العمل.
جمعت أكثر من 20 نصًا باللغات اللاتينية والروسية والإنجليزية والبولندية واليونانية ، في محاولة للحفاظ على حجم كل نص في 35000 كلمة (حجم مخطوطة فوينيتش).
حاولت تحديد المواعدة القريبة في النصوص ، في تهجئة واحدة - على سبيل المثال ، في النصوص باللغة الروسية تجنبت الحرف ، وأدت المتغيرات في كتابة الأحرف اليونانية مع علامات التشكيل المختلفة إلى قاسم مشترك. قمت أيضًا بإزالة الأرقام والعروض الخاصة من النصوص. أحرف ومسافات زائدة وتحويل الحروف إلى حالة واحدة.
الخطوة التالية هي بناء "قاموس" يحتوي على معلومات مثل:
- تكرار استخدام كل كلمة في النص (النصوص) ،
- "جذر" الكلمة - أو بالأحرى جزء مشترك وغير قابل للتغيير لمجموعة من الكلمات ،
- "البادئات" الشائعة و "النهايات" - أو بالأحرى ، بداية الكلمات ونهايتها ، جنبًا إلى جنب مع "الجذر" الذي يشكل الكلمات الفعلية ،
- التسلسل المشترك من 2 و 3 كلمات متطابقة وتكرار حدوثها.
أخذت "جذر" الكلمة في علامات الاقتباس - خوارزمية بسيطة (وأحيانًا أنا نفسي) غير قادرة على تحديد ، على سبيل المثال ، ما هو أصل كلمة دعم؟ قبل أن تصبح كا؟ تحت المعدل ؟
بشكل عام ، هذه المفردات عبارة عن بيانات معدة جزئيًا لبناء ناقل سمة. لماذا خصصت هذه المرحلة - تجميع القواميس وتخزينها مؤقتًا للنصوص الفردية ومجموعة من النصوص لكل لغة من اللغات؟ الحقيقة هي أن إنشاء مثل هذا القاموس يستغرق وقتًا طويلاً ، حوالي نصف دقيقة لكل ملف نصي. ولدي بالفعل أكثر من 120 ملفًا نصيًا.
7 تميز
يعد الحصول على ناقل ميزة مجرد مرحلة أولية لمزيد من سحر المصنف. بصفتي شخص غريب الأطوار ، بالطبع ، قمت بإنشاء فئة تجريدية BaseFeaturizer لمنطق المنبع ، حتى لا تنتهك مبدأ انعكاس التبعية . يورث هذا الفصل أحفادًا ليكونوا قادرين على تحويل ملف نصي واحد أو أكثر في وقت واحد إلى ناقلات رقمية.
ويجب أن تعطي فئة الوراثة اسمًا لكل ميزة فردية (إحداثي i لمتجه الميزة). سيكون هذا مفيدًا إذا قررنا تصور منطق الآلة للتصنيف. على سبيل المثال ، سيتم تمييز البعد 0 للمتجه على أنه CRw1 - الارتباط التلقائي لتردد الكلمات المأخوذة من النص في الموضع المجاور (مع التأخر 1).
من فئة BaseFeaturizer ، ورثت الفئةWordMorphFeaturizer ، يعتمد منطقه على تكرار استخدام الكلمات في جميع أنحاء النص وداخل نافذة منزلقة من 12 كلمة.
أحد الجوانب المهمة هو أن الكود الخاص بالوارث المحدد لـ BaseFeaturizer ، بالإضافة إلى النصوص نفسها ، يحتاج أيضًا إلى قواميس معدة على أساسها (فئة CorpusFeatures ) ، والتي من المرجح أن تكون مخزنة بالفعل على القرص في وقت بدء التدريب واختبار النموذج.
8 التصنيف
الفئة المجردة التالية هي BaseClassifier . يمكن تدريب هذا الكائن ثم تصنيف النصوص حسب نواقل السمات الخاصة بهم.
من أجل التنفيذ (فئة RandomForestLangClassifier ) ، اخترت خوارزمية Random Forest Classifier من مكتبة sklearn . لماذا هذا المصنف بالذات؟
- يناسبني Random Forest Classifier بمعلماته الافتراضية ،
- لا يتطلب تطبيع بيانات الإدخال ،
- يقدم تصورًا بسيطًا وبديهيًا لخوارزمية اتخاذ القرار.
نظرًا لأن Random Forest Classifier ، في رأيي ، قد تعامل جيدًا مع مهمته ، فلم أكتب أي تطبيقات أخرى.
9 التدريب والاختبار
80٪ من الملفات - أجزاء كبيرة من تأليف بايرون وأكساكوف وأبوليوس وبوسانياس وغيرهم من المؤلفين ، الذين يمكن أن أجد نصوصهم بتنسيق txt - تم اختيارها عشوائيًا لتدريب المصنف. تم تحديد نسبة 20٪ المتبقية (28 ملفًا) للاختبار خارج العينة.
بينما اختبرت المصنف على حوالي 30 نصًا باللغة الإنجليزية و 20 نصًا روسيًا ، أعطى المصنف نسبة كبيرة من الأخطاء: في نصف الحالات تقريبًا ، تم تحديد لغة النص بشكل غير صحيح. ولكن عندما بدأت ~ 120 ملفًا نصيًا بخمس لغات (الروسية والإنجليزية واللاتينية واليونانية القديمة والبولندية) توقف المصنف عن ارتكاب الأخطاء وبدأ في التعرف بشكل صحيح على لغة 27-28 ملفًا من 28 حالة اختبار.
ثم قمت بتعقيد المشكلة قليلاً: قمت بنسخ الرواية الأيرلندية من القرن التاسع عشر "راشيل جراي" إلى اليونانية وقدمتها إلى مصنف مدرب. تم تحديد لغة النص المكتوب بحروف أخرى بشكل صحيح مرة أخرى.
10 خوارزمية التصنيف واضحة
هذه هي الطريقة التي تبدو بها واحدة من 100 شجرة في Random Forest Classifier (لجعل الصورة أكثر قابلية للقراءة ، قمت بقطع 3 عقد من الشجرة الفرعية اليمنى):
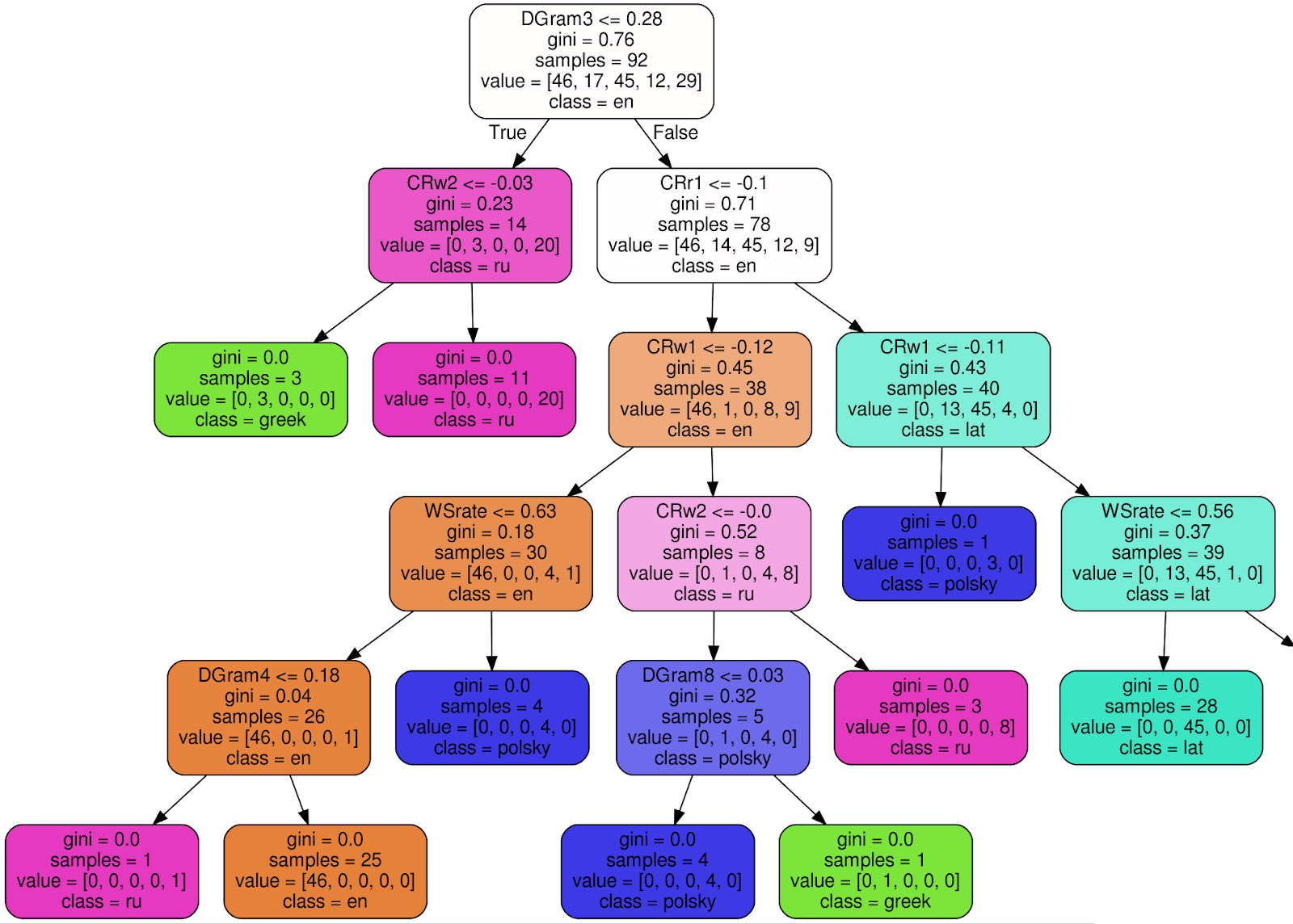
باستخدام عقدة الجذر كمثال ، سأشرح معنى كل توقيع:
- DGram3 <= 0.28 - معيار التصنيف. في هذه الحالة ، يعد DGram3 قياسًا محددًا لمتجه الميزات المسمى بفئة WordMorphFeaturizer ، أي تكرار الكلمة الثالثة الأكثر شيوعًا في نافذة منزلقة من 12 كلمة ،
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
إذا تم استيفاء المعيار (DGram3 <= 0.28 لعقدة الجذر) ، انتقل إلى الشجرة الفرعية اليسرى ، وإلا - إلى اليمين. في كل ورقة ، يجب تعيين جميع النصوص إلى فئة واحدة (لغة) ومعيار عدم اليقين Gini ≡ 0. يتم
اتخاذ القرار النهائي من قبل مجموعة من 100 شجرة مماثلة تم بناؤها أثناء تدريب المصنف.
11 وكيف حدد البرنامج لغة المخطوطة؟
اللاتينية ، تقدير الاحتمال 0.59. وبالطبع ، هذا ليس الحل بعد لمشكلة القرن.
إن المراسلات الفردية بين قاموس المخطوطات واللغة اللاتينية ليست سهلة - إن لم تكن مستحيلة. على سبيل المثال ، فيما يلي عشرة من الكلمات الأكثر استخدامًا: مخطوطات فوينيتش

واللغات اللاتينية واليونانية القديمة والروسية:
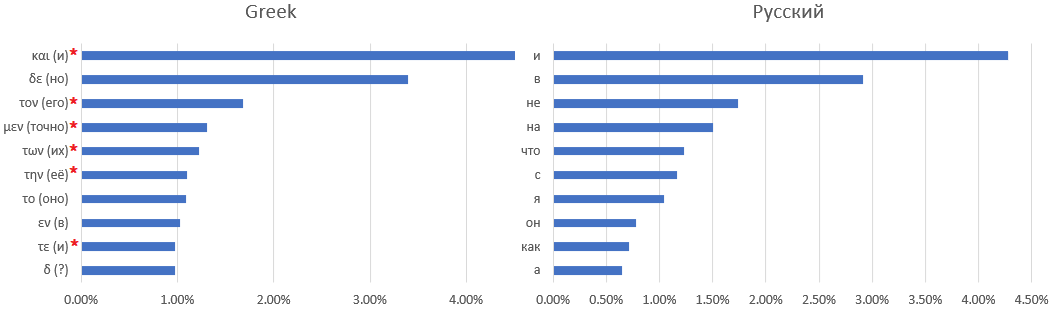
تحدد العلامة النجمية الكلمات التي يصعب العثور على مكافئ روسي - على سبيل المثال ، المقالات أو حروف الجر التي تغير المعنى اعتمادًا على السياق.
تطابق واضح مثل
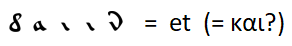
مع تمديد قواعد استبدال الحروف بكلمات أخرى مستخدمة بشكل متكرر ، لم أتمكن من العثور عليها. يمكنك فقط وضع افتراضات - على سبيل المثال ، الكلمة الأكثر شيوعًا هي "و" - كما هو الحال في جميع اللغات الأخرى التي يتم النظر فيها باستثناء اللغة الإنجليزية ، حيث تم دفع أداة العطف "و" إلى المرتبة الثانية بواسطة المقالة المحددة "the".
ماذا بعد؟
أولاً ، يجدر بنا محاولة استكمال عينة اللغات بنصوص حديثة بالفرنسية والإسبانية و ... ولغات الشرق الأوسط ، إن أمكن - الإنجليزية القديمة واللغات الفرنسية (قبل القرن الخامس عشر) وغيرها. حتى لو لم تكن أي من هذه اللغات هي لغة المخطوطة ، فإن دقة تعريف اللغات المعروفة ستستمر في الزيادة ، ومن المحتمل أن يتم اختيار لغة مماثلة للغة المخطوطة.
التحدي الأكثر إبداعًا هو محاولة تحديد جزء من الكلام لكل كلمة. بالنسبة لعدد من اللغات (بالطبع ، أولاً وقبل كل شيء - اللغة الإنجليزية) ، فإن رموز PoS (جزء من الكلام) المميزة كجزء من الحزم المتاحة للتنزيل ، قم بهذه المهمة جيدًا. لكن كيف تحدد أدوار الكلمات بلغة غير معروفة؟
تم حل مشاكل مماثلة من قبل اللغوي السوفيتي ب. Sukhotin - على سبيل المثال ، وصف الخوارزميات:
- فصل أحرف أبجدية غير معروفة إلى أحرف العلة والحروف الساكنة - للأسف ، ليست موثوقة بنسبة 100٪ ، خاصة بالنسبة للغات ذات الصوتيات غير التافهة ، مثل الفرنسية ،
- اختيار الأشكال في النص بدون مسافات.
بالنسبة إلى رموز PoS ، يمكننا البدء من تكرار استخدام الكلمات ، والتواجد في مجموعات من 2/3 كلمات ، وتوزيع الكلمات على أقسام النص: يجب توزيع النقابات والجسيمات بشكل متساوٍ أكثر من الأسماء.
الأدب
لن أترك هنا روابط للكتب والبرامج التعليمية حول البرمجة اللغوية العصبية - هذا يكفي على الشبكة. بدلاً من ذلك ، سأقوم بإدراج الأعمال الفنية التي أصبحت اكتشافًا رائعًا بالنسبة لي كطفل ، حيث كان على الأبطال العمل بجد لكشف النصوص المشفرة:
- إي أيه بو: الخنفساء الذهبية هي لعبة كلاسيكية خالدة
- في بابينكو: "لقاء" قصة بوليسية مشهورة ملتوية وذات رؤية إلى حد ما في أواخر الثمانينيات ،
- كيريتا: "فرسان من شارع Chereshnevaya ، أو قلعة الفتاة ذات اللون الأبيض" هي رواية مراهقة رائعة ، كتبت دون خصم لسن القارئ.