أنا مبتكر حاقن التبعية . هذا هو إطار عمل حقن التبعية لبايثون.
هذا هو الدليل النهائي لبناء التطبيقات باستخدام حاقن التبعية. وتشمل الدروس الماضية كيفية بناء تطبيقات الويب مع قارورة ، REST API مع Aiohttp، و رصد الخفي مع Asyncio باستخدام حقن التبعية.
أريد اليوم أن أوضح كيف يمكنك إنشاء تطبيق وحدة التحكم (CLI).
بالإضافة إلى ذلك ، أعددت إجابات للأسئلة المتداولة وسوف أنشر التذييل الخاص بهم.
يتكون الدليل من الأجزاء التالية:
- ماذا سنبني؟
- تهيئة البيئة
- هيكل المشروع
- تثبيت التبعيات
- تركيبات
- حاوية
- العمل مع ملف csv
- العمل مع sqlite
- محدد المزود
- الاختبارات
- خاتمة
- ملاحظة: أسئلة وأجوبة
يمكن العثور على المشروع المكتمل على Github .
للبدء ، يجب أن يكون لديك:
- Python 3.5+
- بيئة افتراضية
ومن المستحسن أن يكون لديك فهم عام لمبدأ حقن التبعية.
ماذا سنبني؟
سنقوم ببناء تطبيق CLI (وحدة تحكم) يبحث عن الأفلام. دعنا نسميها فيلم ليستر.
كيف يعمل Movie Lister؟
- لدينا قاعدة بيانات للأفلام
- المعلومات التالية معروفة عن كل فيلم:
- اسم
- سنة الصنع
- اسم المخرج
- يتم توزيع قاعدة البيانات في شكلين:
- ملف CSV
- قاعدة بيانات Sqlite
- يبحث التطبيق في قاعدة البيانات باستخدام المعايير التالية:
- اسم المخرج
- سنة الصنع
- قد يتم إضافة تنسيقات قواعد البيانات الأخرى في المستقبل
Movie Lister هو تطبيق نموذجي مستخدم في مقالة Martin Fowler حول حقن التبعية وعكس التحكم.
هكذا يبدو مخطط الفصل لتطبيق Movie Lister:
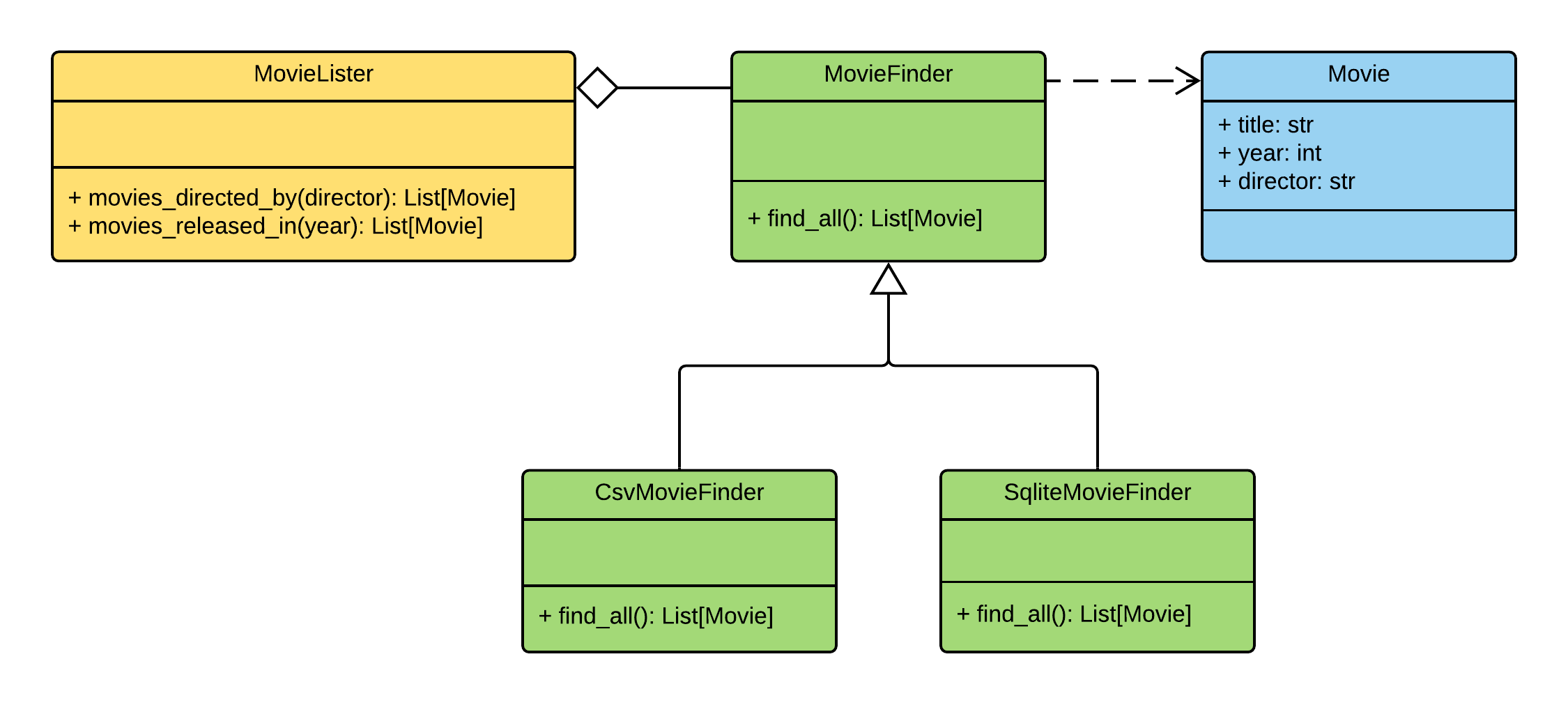
يتم توزيع المسؤوليات بين الفصول على النحو التالي:
MovieLister- مسؤول عن البحثMovieFinder- مسؤول عن استخراج البيانات من قاعدة البياناتMovie- فئة الكيان "فيلم"
تهيئة البيئة
لنبدأ بإعداد البيئة.
بادئ ذي بدء ، نحتاج إلى إنشاء مجلد مشروع وبيئة افتراضية:
mkdir movie-lister-tutorial
cd movie-lister-tutorial
python3 -m venv venv
لنقم الآن بتنشيط البيئة الافتراضية:
. venv/bin/activate
البيئة جاهزة. الآن دعنا ندخل في هيكل المشروع.
هيكل المشروع
في هذا القسم ، سننظم هيكل المشروع.
لنقم بإنشاء الهيكل التالي في المجلد الحالي. اترك كل الملفات فارغة الآن.
الهيكل الأولي:
./
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
تثبيت التبعيات
حان الوقت لتثبيت التبعيات. سوف نستخدم حزم مثل هذه:
dependency-injector- إطار حقن التبعيةpyyaml- مكتبة لتحليل ملفات YAML ، وتستخدم لقراءة ملف configpytest- إطار الاختبارpytest-cov- مكتبة مساعدة لقياس تغطية الكود بالاختبارات
دعنا نضيف الأسطر التالية إلى الملف
requirements.txt:
dependency-injector
pyyaml
pytest
pytest-cov
ونفذ في الجهاز:
pip install -r requirements.txt
اكتمل تثبيت التبعيات. الانتقال إلى المباريات.
تركيبات
في هذا القسم ، سنضيف تركيبات. بيانات الاختبار تسمى تركيبات.
سنقوم بإنشاء برنامج نصي يقوم بإنشاء قواعد بيانات اختبار.
أضف دليلًا
data/إلى جذر المشروع وأضف ملفًا بداخله fixtures.py:
./
├── data/
│ └── fixtures.py
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
بعد ذلك ، قم بتحرير
fixtures.py:
"""Fixtures module."""
import csv
import sqlite3
import pathlib
SAMPLE_DATA = [
('The Hunger Games: Mockingjay - Part 2', 2015, 'Francis Lawrence'),
('Rogue One: A Star Wars Story', 2016, 'Gareth Edwards'),
('The Jungle Book', 2016, 'Jon Favreau'),
]
FILE = pathlib.Path(__file__)
DIR = FILE.parent
CSV_FILE = DIR / 'movies.csv'
SQLITE_FILE = DIR / 'movies.db'
def create_csv(movies_data, path):
with open(path, 'w') as opened_file:
writer = csv.writer(opened_file)
for row in movies_data:
writer.writerow(row)
def create_sqlite(movies_data, path):
with sqlite3.connect(path) as db:
db.execute(
'CREATE TABLE IF NOT EXISTS movies '
'(title text, year int, director text)'
)
db.execute('DELETE FROM movies')
db.executemany('INSERT INTO movies VALUES (?,?,?)', movies_data)
def main():
create_csv(SAMPLE_DATA, CSV_FILE)
create_sqlite(SAMPLE_DATA, SQLITE_FILE)
print('OK')
if __name__ == '__main__':
main()
الآن دعنا ننفذ في المحطة:
python data/fixtures.py
يجب أن يخرج النص
OKعلى النجاح.
ونحن تحقق من أن الملفات
movies.csvو movies.dbظهرت في الدليل data/:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
يتم إنشاء التركيبات. فلنكمل.
حاوية
في هذا القسم ، سنضيف الجزء الرئيسي من تطبيقنا - الحاوية.
تتيح لك الحاوية وصف بنية التطبيق بأسلوب تعريفي. سيحتوي على جميع مكونات التطبيق وتبعياتها. سيتم تحديد جميع التبعيات بشكل صريح. يتم استخدام الموفرين لإضافة مكونات التطبيق إلى الحاوية. يتحكم الموفرون في عمر المكونات. عند إنشاء موفر ، لا يتم إنشاء أي مكون. نخبر المزود بكيفية إنشاء الكائن ، وسيقوم بإنشائه في أقرب وقت ممكن. إذا كانت تبعية أحد مقدمي الخدمة هي مزود آخر ، فسيتم استدعاؤه وهكذا على طول سلسلة التبعيات.
دعنا نحرر
containers.py:
"""Containers module."""
from dependency_injector import containers
class ApplicationContainer(containers.DeclarativeContainer):
...
الحاوية لا تزال فارغة. سنقوم بإضافة مقدمي في الأقسام التالية.
دعنا نضيف وظيفة أخرى
main(). مسؤوليتها هي تشغيل التطبيق. في الوقت الحالي ، ستقوم فقط بإنشاء حاوية.
دعنا نحرر
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
if __name__ == '__main__':
main()
الحاوية هي الكائن الأول في التطبيق. يتم استخدامه للحصول على جميع الأشياء الأخرى.
العمل مع ملف csv
الآن دعنا نضيف كل ما نحتاجه للعمل مع ملفات csv.
نحن نحتاج:
- الجوهر
Movie - فئة أساسية
MovieFinder - تنفيذه
CsvMovieFinder - صف دراسي
MovieLister
بعد إضافة كل مكون ، سنضيفه إلى الحاوية.
قم بإنشاء ملف
entities.pyفي حزمة movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ └── entities.py
├── venv/
├── config.yml
└── requirements.txt
وأضف الأسطر التالية بالداخل:
"""Movie entities module."""
class Movie:
def __init__(self, title: str, year: int, director: str):
self.title = str(title)
self.year = int(year)
self.director = str(director)
def __repr__(self):
return '{0}(title={1}, year={2}, director={3})'.format(
self.__class__.__name__,
repr(self.title),
repr(self.year),
repr(self.director),
)
الآن نحن بحاجة إلى إضافة مصنع
Movieإلى الحاوية. لهذا نحتاج إلى وحدة providersمن dependency_injector.
دعنا نحرر
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import entities
class ApplicationContainer(containers.DeclarativeContainer):
movie = providers.Factory(entities.Movie)
لا تنس إزالة علامة الحذف ( ...). تحتوي الحاوية بالفعل على موفرين ولم تعد هناك حاجة إليها.
دعنا ننتقل إلى إنشاء
finders.
قم بإنشاء ملف
finders.pyفي حزمة movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ └── finders.py
├── venv/
├── config.yml
└── requirements.txt
وأضف الأسطر التالية بالداخل:
"""Movie finders module."""
import csv
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
الآن دعنا نضيف
CsvMovieFinderإلى الحاوية.
دعنا نحرر
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
هل
CsvMovieFinderيملك الاعتماد على المصنع Movie. CsvMovieFinderيحتاج إلى مصنع لأنه سينشئ كائنات Movieلأنه يقرأ البيانات من ملف. من أجل اجتياز المصنع ، نستخدم السمة .provider. هذا يسمى تفويض الموفر. إذا حددنا مصنعًا على movieأنه تبعية ، فسيتم استدعاؤه عند csv_finderإنشائه CsvMovieFinderوسيتم تمرير كائن كحقن Movie. استخدام السمة .providerكحقنة سيمررها الموفر نفسه.
انها
csv_finderلديها أيضا الاعتماد على عدة خيارات التكوين. لقد أضفنا مزودًا onfigurationلتمرير هذه التبعيات.
استخدمنا معلمات التكوين قبل تحديد قيمها. هذا هو المبدأ الذي يعمل به المزودConfiguration.
أولا نستخدم ، ثم نضع القيم.
الآن دعنا نضيف قيم التكوين.
دعنا نحرر
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
يتم تعيين القيم إلى ملف التكوين. دعونا نقوم بتحديث الوظيفة
main()للإشارة إلى موقعها.
دعنا نحرر
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
if __name__ == '__main__':
main()
دعنا نذهب إلى
listers.
قم بإنشاء ملف
listers.pyفي حزمة movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ └── listers.py
├── venv/
├── config.yml
└── requirements.txt
وأضف الأسطر التالية بالداخل:
"""Movie listers module."""
from .finders import MovieFinder
class MovieLister:
def __init__(self, movie_finder: MovieFinder):
self._movie_finder = movie_finder
def movies_directed_by(self, director):
return [
movie for movie in self._movie_finder.find_all()
if movie.director == director
]
def movies_released_in(self, year):
return [
movie for movie in self._movie_finder.find_all()
if movie.year == year
]
نقوم بتحديث
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=csv_finder,
)
يتم إنشاء جميع المكونات وإضافتها إلى الحاوية.
أخيرًا ، نقوم بتحديث الوظيفة
main().
دعنا نحرر
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
كل شيء جاهز. الآن دعنا نطلق التطبيق.
لننفذ في المحطة:
python -m movies
سوف ترى:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
يعمل تطبيقنا مع قاعدة بيانات للأفلام بتنسيق
csv. نحتاج أيضًا إلى إضافة دعم التنسيق sqlite. سنتعامل مع هذا في القسم التالي.
العمل مع sqlite
في هذا القسم ، سنضيف نوعًا آخر
MovieFinder- SqliteMovieFinder.
دعنا نحرر
finders.py:
"""Movie finders module."""
import csv
import sqlite3
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
class SqliteMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
) -> None:
self._database = sqlite3.connect(path)
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with self._database as db:
rows = db.execute('SELECT title, year, director FROM movies')
return [self._movie_factory(*row) for row in rows]
أضف الموفر
sqlite_finderإلى الحاوية وحدده كعنصر تابع للموفر lister.
دعنا نحرر
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=sqlite_finder,
)
يعتمد الموفر
sqlite_finderعلى خيارات التكوين التي لم نحددها بعد. لنقم بتحديث ملف التكوين:
تحرير
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
sqlite:
path: "data/movies.db"
منجز. دعونا تحقق.
ننفذ في المحطة:
python -m movies
سوف ترى:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
يدعم تطبيقنا كلاً من تنسيقات قاعدة البيانات:
csvو sqlite. في كل مرة نحتاج فيها إلى تغيير التنسيق ، يتعين علينا تغيير الكود في الحاوية. سنقوم بتحسين هذا في القسم التالي.
محدد المزود
في هذا القسم ، سنجعل طلبنا أكثر مرونة.
ستحتاج لم تعد لإجراء تغييرات في قانون للتبديل بين
csvو sqliteالأشكال. سننفذ مفتاحًا بناءً على متغير البيئة MOVIE_FINDER_TYPE:
- عندما
MOVIE_FINDER_TYPE=csvيستخدم التطبيق ملفcsv. - عندما
MOVIE_FINDER_TYPE=sqliteيستخدم التطبيق ملفsqlite.
سوف يساعدنا المزود في هذا
Selector. يختار مزودًا بناءً على خيار التكوين ( الوثائق ).
دعنا نحرر
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
أنشأنا موفرًا
finderوحددناه على أنه تبعية للمزود lister. finderيختار المزود بين مقدمي الخدمة csv_finderوفي sqlite_finderوقت التشغيل. الاختيار يعتمد على قيمة التبديل.
التبديل هو خيار التكوين
config.finder.type. عندما يتم csvاستخدام قيمته من قبل المزود من المفتاح csv. وبالمثل ل sqlite.
الآن نحن بحاجة إلى قراءة القيمة
config.finder.typeمن متغير البيئة MOVIE_FINDER_TYPE.
دعنا نحرر
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
container.config.finder.type.from_env('MOVIE_FINDER_TYPE')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
منجز.
قم بتشغيل الأوامر التالية في الجهاز:
MOVIE_FINDER_TYPE=csv python -m movies
MOVIE_FINDER_TYPE=sqlite python -m movies
سيبدو إخراج كل أمر كما يلي:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
في هذا القسم ، تعرفنا على المزود
Selector. مع هذا المزود ، يمكنك جعل طلبك أكثر مرونة. يمكن تعيين قيمة التبديل من أي مصدر: ملف التكوين ، القاموس ، مزود آخر.
تلميح:
يتيح لك تجاوز قيمة التكوين من مزود آخر تنفيذ التحميل الزائد للتكوين في أحد التطبيقات دون إعادة التشغيل السريع.
للقيام بذلك ، تحتاج إلى استخدام تفويض الموفر و.override().
في القسم التالي ، سنضيف بعض الاختبارات.
الاختبارات
أخيرًا ، دعنا نضيف بعض الاختبارات.
قم بإنشاء ملف
tests.pyفي حزمة movies:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ ├── listers.py
│ └── tests.py
├── venv/
├── config.yml
└── requirements.txt
وأضف إليها الأسطر التالية:
"""Tests module."""
from unittest import mock
import pytest
from .containers import ApplicationContainer
@pytest.fixture
def container():
container = ApplicationContainer()
container.config.from_dict({
'finder': {
'type': 'csv',
'csv': {
'path': '/fake-movies.csv',
'delimiter': ',',
},
'sqlite': {
'path': '/fake-movies.db',
},
},
})
return container
def test_movies_directed_by(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_directed_by('Jon Favreau')
assert len(movies) == 1
assert movies[0].title == 'The Jungle Book'
def test_movies_released_in(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_released_in(2015)
assert len(movies) == 1
assert movies[0].title == 'The 33'
لنبدأ الآن في الاختبار والتحقق من التغطية:
pytest movies/tests.py --cov=movies
سوف ترى:
platform darwin -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
plugins: cov-2.10.0
collected 2 items
movies/tests.py .. [100%]
---------- coverage: platform darwin, python 3.8.3-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
movies/__init__.py 0 0 100%
movies/__main__.py 10 10 0%
movies/containers.py 9 0 100%
movies/entities.py 7 1 86%
movies/finders.py 26 13 50%
movies/listers.py 8 0 100%
movies/tests.py 24 0 100%
------------------------------------------
TOTAL 84 24 71%
استخدمنا طريقة.override()المزودfinder. تم تجاوز الموفر بواسطة وهمي. عند الاتصال بالموفر ،finderسيتم الآن إعادة النموذج الأساسي .
يتم العمل. الآن دعونا نلخص.
خاتمة
قمنا ببناء تطبيق CLI باستخدام مبدأ حقن التبعية. استخدمنا حاقن التبعية كإطار حقن تبعية.
الميزة التي تحصل عليها مع Dependency Injector هي الحاوية.
تبدأ الحاوية في الدفع عندما تحتاج إلى فهم أو تغيير هيكل التطبيق الخاص بك. باستخدام الحاوية ، يكون هذا أمرًا سهلاً لأن جميع مكونات التطبيق وتبعياتها محددة بوضوح في مكان واحد:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
الحاوية كخريطة لتطبيقك. أنت تعرف دائمًا ما يعتمد على ما.
ملاحظة: أسئلة وأجوبة
في التعليقات على البرنامج التعليمي السابق ، تم طرح أسئلة رائعة: "لماذا هذا ضروري؟" ، "لماذا نحتاج إلى إطار عمل؟" ، "كيف يساعد إطار العمل في التنفيذ؟"
أعددت إجابات:
ما هو حقن التبعية؟
- هذا هو المبدأ الذي يقلل من الاقتران ويزيد من التماسك
لماذا يجب علي استخدام حقن التبعية؟
- تصبح التعليمات البرمجية الخاصة بك أكثر مرونة ومفهومة وقابلية للاختبار بشكل أفضل
- لديك مشاكل أقل عندما تحتاج إلى فهم كيفية عملها أو تغييرها
كيف أبدأ بتطبيق حقن التبعية؟
- تبدأ في كتابة التعليمات البرمجية باتباع مبدأ حقن التبعية
- تقوم بتسجيل جميع المكونات وتبعياتها في الحاوية
- عندما تحتاج إلى مكون ، تحصل عليه من الحاوية
لماذا أحتاج إلى إطار عمل لهذا؟
- أنت بحاجة إلى إطار عمل حتى لا تنشئ إطارًا خاصًا بك. سيتم تكرار رمز إنشاء الكائن ويصعب تغييره. لتجنب هذا ، تحتاج إلى وعاء.
- يمنحك إطار العمل حاوية وموفرين
- يتحكم الموفرون في عمر الكائنات. ستحتاج إلى مصانع وأجزاء فردية وكائنات تكوين
- تعمل الحاوية كمجموعة من مقدمي الخدمات
ما الثمن الذي سأدفعه؟
- تحتاج إلى تحديد التبعيات بشكل صريح في الحاوية
- هذا عمل إضافي
- سيبدأ في دفع الأرباح عندما يبدأ المشروع في النمو
- أو بعد أسبوعين من اكتماله (عندما تنسى القرارات التي اتخذتها وما هي بنية المشروع)
مفهوم حاقن التبعية
بالإضافة إلى ذلك ، سأصف مفهوم حاقن التبعية كإطار عمل.
يعتمد حاقن التبعية على مبدأين:
- الصريح أفضل من الضمني (PEP20).
- لا تفعل أي سحر مع التعليمات البرمجية الخاصة بك.
كيف يختلف حاقن التبعية عن الأطر الأخرى؟
- لا يوجد ربط تلقائي. إطار العمل لا يربط تلقائيًا التبعيات. لا يتم استخدام الاستبطان والربط بأسماء و / أو أنواع الوسيطات. لأن "الصريح أفضل من الضمني (PEP20)".
- لا تلوث رمز التطبيق الخاص بك. التطبيق الخاص بك غير مدرك ومستقل عن حاقن التبعية. لا توجد
@injectزينة أو شروح أو ترقيع أو حيل سحرية أخرى.
يقدم Dependency Injector عقدًا بسيطًا:
- أنت تظهر الإطار كيفية جمع الأشياء
- يجمعهم الإطار
تكمن قوة حاقن التبعية في بساطته ووضوحه. إنها أداة بسيطة لتنفيذ مبدأ قوي.
ماذا بعد؟
إذا كنت مهتمًا ، لكنك متردد ، فإن توصيتي هي:
جرب هذا الأسلوب لمدة شهرين. إنه ليس بديهيًا. يستغرق الأمر وقتًا للتعود عليه والشعور به. تصبح الفوائد ملموسة عندما ينمو المشروع إلى أكثر من 30 مكونًا في الحاوية. إذا كنت لا تحب ذلك ، فلا تخسر الكثير. إذا كنت ترغب في ذلك ، احصل على ميزة كبيرة.
- تعرف على المزيد حول Dependency Injector على GitHub
- تحقق من الوثائق في قراءة المستندات
سأكون سعيدًا لتلقي التعليقات والإجابة على الأسئلة في التعليقات.