في شركتنا ، نعمل بنشاط على الاستخراج التلقائي للوثائق ، ولم تتضمن هذه المقالة جميع التفاصيل والرموز ، ولكنها وصفت الأساليب والنتائج الرئيسية باستخدام مثال مجموعة بيانات محايدة: 30.000 مقالة إخبارية رياضية لكرة القدم تم جمعها من بوابة معلومات Sport-Express.
لذلك ، يمكن تعريف التلخيص على أنه الإنشاء التلقائي لملخص (العنوان ، الملخص ، التعليق التوضيحي) للنص الأصلي. هناك طريقتان مختلفتان بشكل كبير لهذه المشكلة: الاستخراجية والتجريدية.
تلخيص استخلاصي
يتمثل الأسلوب الاستخراجي في استخراج أهم كتل المعلومات "أهمية" من النص المصدر. يمكن أن تكون الكتلة عبارة عن فقرات مفردة أو جمل أو كلمات رئيسية.

تتميز طرق هذا النهج بوجود وظيفة تقييم لأهمية كتلة المعلومات. من خلال ترتيب هذه الكتل حسب الأهمية واختيار عدد محدد مسبقًا منها ، نشكل الملخص النهائي للنص.
دعنا ننتقل إلى وصف بعض الأساليب الاستخراجية.
التجميع الاستخراجي على أساس حدوث الكلمات الشائعة
هذه الخوارزمية سهلة الفهم والتنفيذ. نحن هنا نعمل فقط مع الكود المصدري ، وعلى العموم لا نحتاج إلى تدريب أي نموذج استخراج. في حالتي ، ستمثل كتل المعلومات المستردة جملًا معينة من النص.
لذلك ، في الخطوة الأولى ، نقوم بتقسيم نص الإدخال إلى جمل ونقسم كل جملة إلى رموز مميزة (كلمات منفصلة) ، وتنفيذ lemmatization لهم (إحضار الكلمة إلى الشكل "الكنسي"). هذه الخطوة ضرورية من أجل أن تجمع الخوارزمية كلمات متطابقة في المعنى ولكنها تختلف في أشكال الكلمات.
ثم نقوم بتعيين دالة التشابه لكل زوج من الجمل. سيتم حسابها كنسبة عدد الكلمات الشائعة الموجودة في كلتا الجملتين إلى الطول الإجمالي... نتيجة لذلك ، نحصل على معاملات التشابه لكل زوج من الجمل.
بعد أن استبعدنا سابقًا الجمل التي ليس لها كلمات مشتركة مع الآخرين ، نقوم ببناء رسم بياني حيث تكون الرؤوس هي الجمل نفسها ، والحواف بينها تظهر وجود الكلمات الشائعة فيها.
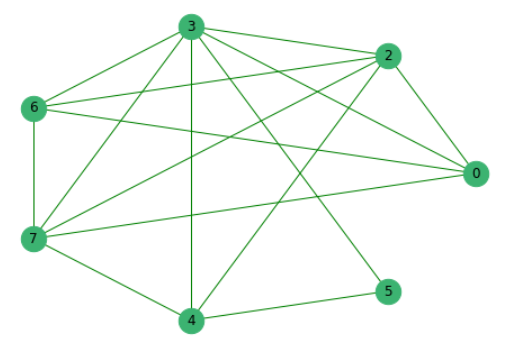
بعد ذلك ، نقوم بترتيب جميع المقترحات وفقًا لأهميتها.

باختيار عدة جمل ذات أعلى معاملات ثم فرزها حسب عدد تكراراتها في النص ، نحصل على الملخص النهائي.
التجميع الاستخراجي على أساس تمثيلات ناقلات المدربة
تم استخدام بيانات الأخبار الكاملة التي تم جمعها مسبقًا لإنشاء الخوارزمية التالية.
نقوم بتقسيم الكلمات في جميع النصوص إلى رموز مميزة ودمجها في قائمة. في المجموع ، احتوت النصوص على 2270778 كلمة ، منها 114247 كلمة فريدة.
باستخدام نموذج Word2Vec الشهير ، سنجد تمثيلًا متجهًا لكل كلمة فريدة. يخصص النموذج متجهات عشوائية لكل كلمة ، علاوة على ذلك ، في كل خطوة من خطوات التعلم ، "دراسة السياق" ، يصحح قيمها. أبعاد المتجه ، والتي هي قادرة على "تذكر" ميزة الكلمة ، يمكنك تعيين أي. بناءً على حجم مجموعة البيانات المتاحة ، سنأخذ متجهات تتكون من 100 رقم. ألاحظ أيضًا أن Word2Vec هو نموذج قابل لإعادة التدريب ، والذي يسمح لك بإرسال بيانات جديدة إلى المدخلات ، وعلى أساسها ، تصحيح تمثيلات المتجه الحالية للكلمات.
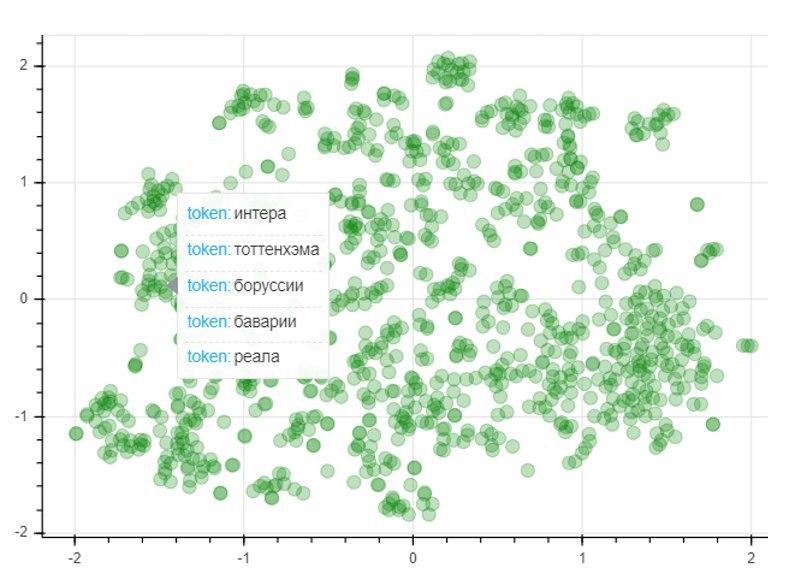
لتقييم جودة النموذج ، سنطبق طريقة تقليل أبعاد T-SNE ، والتي تنشئ بشكل تكراري مخططًا متجهًا لأكثر 1000 كلمة استخدامًا في مساحة ثنائية الأبعاد. يمثل الرسم البياني الناتج موقع النقاط ، كل منها يتوافق مع كلمة معينة بحيث تكون الكلمات المتشابهة في المعنى قريبة من بعضها البعض ، بينما الكلمات المختلفة على العكس من ذلك. إذن على الجانب الأيسر من الرسم البياني توجد أسماء أندية كرة القدم ، وتمثل النقاط الموجودة في الزاوية اليسرى السفلية أسماء وألقاب لاعبي كرة القدم والمدربين:
بعد الحصول على تمثيلات المتجه المدربة للكلمات ، يمكنك المتابعة إلى الخوارزمية نفسها. كما في الحالة السابقة ، عند الإدخال لدينا نص نقسمه إلى جمل. من خلال ترميز كل جملة ، نقوم بتكوين تمثيلات متجهة لها. للقيام بذلك ، نأخذ نسبة مجموع المتجهات لكل كلمة في الجملة إلى طول الجملة نفسها. تساعدنا ناقلات الكلمات المدربة مسبقًا هنا. في حالة عدم وجود كلمة في القاموس ، يتم إضافة متجه صفري إلى متجه الجملة الحالي. وبالتالي ، فإننا نحيد تأثير ظهور كلمة جديدة غائبة في القاموس على المتجه العام للجملة.
بعد ذلك ، نقوم بتكوين مصفوفة تشابه الجملة التي تستخدم صيغة تشابه جيب التمام لكل زوج من الجمل.
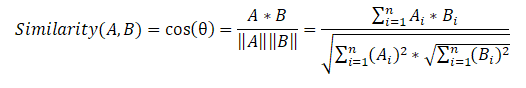
في المرحلة الأخيرة ، بناءً على مصفوفة التشابه ، نقوم أيضًا بإنشاء رسم بياني وإجراء ترتيب للجمل حسب الأهمية. كما في الخوارزمية السابقة ، نحصل على قائمة بالجمل المصنفة وفقًا لأهميتها في النص.

في النهاية ، سأصوّر بشكل تخطيطي وأصف مرة أخرى المراحل الرئيسية لتنفيذ الخوارزمية (بالنسبة للخوارزمية الاستخراجية الأولى ، يكون تسلسل الإجراءات هو نفسه تمامًا ، باستثناء أننا لا نحتاج إلى العثور على تمثيلات متجهية للكلمات ، ويتم حساب وظيفة التشابه لكل زوج من الجمل بناءً على حدوث المشترك المشترك كلمات):

- تقسيم نص الإدخال إلى جمل منفصلة ومعالجتها.
- ابحث عن تمثيل متجه لكل جملة.
- حساب وتخزين التشابه بين متجهات الجملة في مصفوفة.
- تحويل المصفوفة الناتجة إلى رسم بياني بجمل على شكل رؤوس وتقديرات تشابه في شكل حواف لحساب رتبة الجمل.
- اختيار المقترحات الحاصلة على أعلى الدرجات للسيرة الذاتية النهائية.
مقارنة الخوارزميات الاستخراجية
باستخدام Flask microframework ( أداة لإنشاء تطبيقات ويب مبسطة ) ، تم تطوير خدمة ويب اختبارية للمقارنة المرئية لإخراج النماذج الاستخراجية باستخدام مثال لمجموعة متنوعة من نصوص الأخبار المصدر. لقد قمت بتحليل الملخص الناتج عن كلا النموذجين (استرجاع أهم جملتين) لمائة مقالة إخبارية رياضية مختلفة.

بناءً على نتائج مقارنة نتائج تحديد العروض الأكثر ملاءمة لكلا النموذجين ، يمكنني تقديم التوصيات التالية لاستخدام الخوارزميات:
- . , . , .
- . , , , . , , , .
تلخيص تجريدي
يختلف النهج التجريدي اختلافًا كبيرًا عن سابقتها ويتكون من إنشاء ملخص مع توليد نص جديد ، يلخص الوثيقة الأولية بشكل هادف.
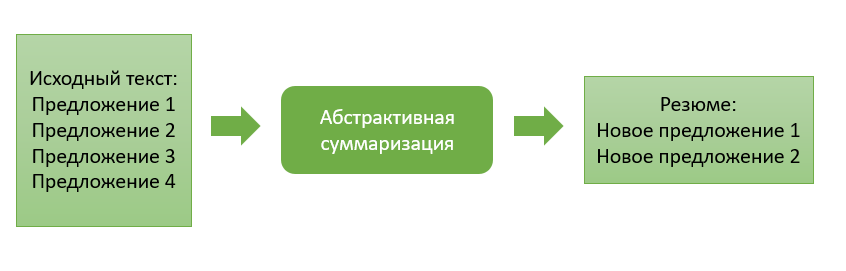
الفكرة الرئيسية لهذا النهج هي أن النموذج قادر على إنشاء ملخص فريد تمامًا ، والذي قد يحتوي على كلمات غير موجودة في النص الأصلي. الاستدلال النموذجي هو إعادة سرد للنص ، وهو أقرب إلى التجميع اليدوي لملخص النص بواسطة الأشخاص.
مرحلة التعلم
لن أتطرق إلى الإثبات الرياضي للخوارزمية ، فكل النماذج التي أعرفها تستند إلى بنية "وحدة فك التشفير" ، والتي بدورها مبنية باستخدام طبقات LSTM المتكررة (يمكنك أن تقرأ عن مبدأ عملها هنا ). سوف أصف بإيجاز خطوات فك تشفير تسلسل الاختبار.
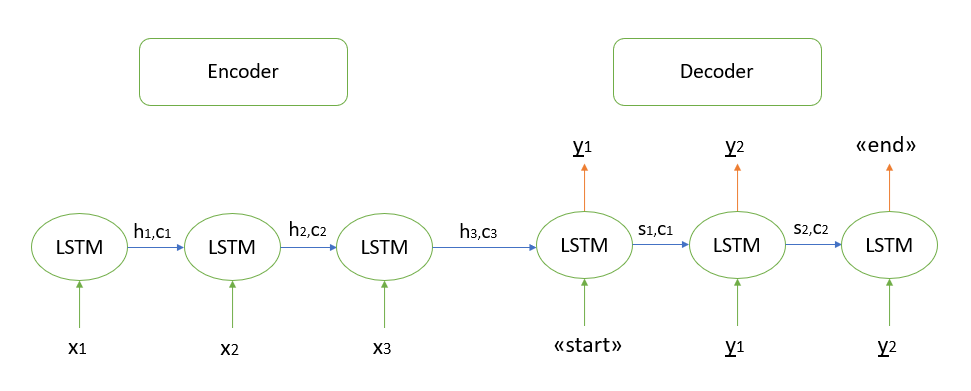
- نقوم بتشفير تسلسل الإدخال بالكامل وتهيئة وحدة فك الترميز بالحالات الداخلية لجهاز التشفير
- قم بتمرير رمز "البدء" كمدخل إلى وحدة فك التشفير
- نبدأ وحدة فك التشفير بالحالات الداخلية للمشفّر لخطوة زمنية واحدة ، ونتيجة لذلك نحصل على احتمال الكلمة التالية (الكلمة ذات الاحتمال الأقصى)
- قم بتمرير الكلمة المحددة كمدخل إلى وحدة فك التشفير في الخطوة التالية وقم بتحديث الحالات الداخلية
- كرر الخطوتين 3 و 4 حتى نقوم بإنشاء رمز "النهاية"
يمكن العثور على مزيد من التفاصيل حول بنية "وحدة فك التشفير" هنا .
تنفيذ التلخيص التجريدي
لبناء نموذج تجريدي أكثر تعقيدًا لاستخراج محتوى الملخص ، يلزم وجود نصوص إخبارية كاملة وعناوينها. سيكون عنوان الأخبار بمثابة ملخص ، لأن النموذج "لا يتذكر جيدًا" التسلسلات النصية الطويلة.
عند تنظيف البيانات ، نستخدم الترجمة بالأحرف الصغيرة ونتجاهل الأحرف غير الروسية. إن إزالة الكلمات من الكلمات وإزالة حروف الجر والجسيمات والأجزاء الأخرى غير المفيدة من الكلام سيكون لها تأثير سلبي على الناتج النهائي للنموذج ، حيث ستفقد العلاقة بين الكلمات في الجملة.
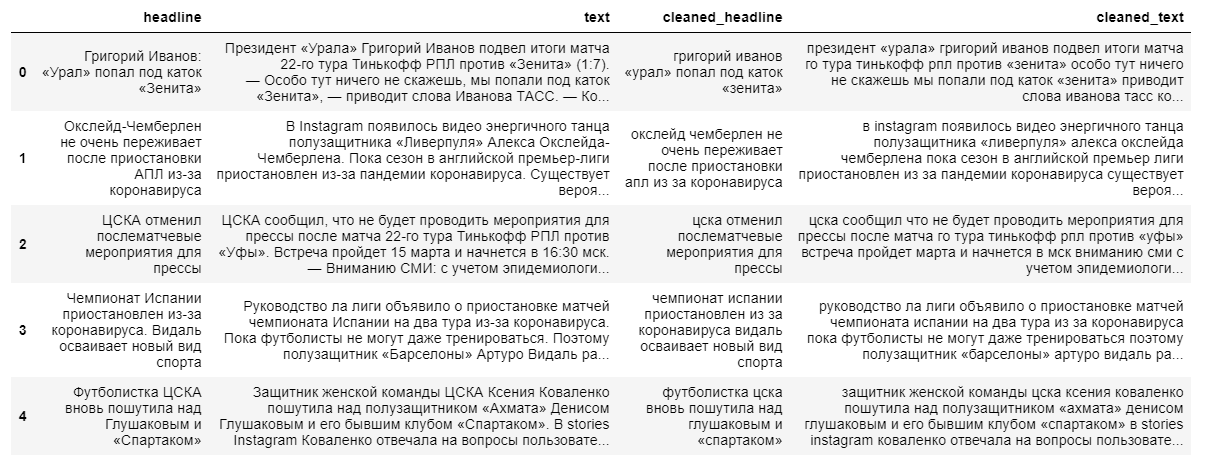
بعد ذلك ، قمنا بتقسيم النصوص وعناوينها إلى عينات تدريب واختبار بنسبة 9 إلى 1 ، وبعد ذلك نقوم بتحويلها إلى متجهات (بشكل عشوائي).
في الخطوة التالية ، نقوم بإنشاء النموذج نفسه ، والذي سيقرأ متجهات الكلمات المنقولة إليه وتنفيذ معالجتها باستخدام 3 طبقات متكررة من مشفر LSTM وطبقة واحدة من وحدة فك التشفير.
بعد تهيئة النموذج ، نقوم بتدريبه باستخدام دالة خسارة إنتروبيا تظهر التناقض بين عنوان الهدف الحقيقي والعنوان الذي تنبأ به نموذجنا.

أخيرًا ، قمنا بإخراج نتيجة النموذج لمجموعة التدريب. كما ترى في الأمثلة ، تحتوي النصوص المصدر والملخصات على معلومات غير دقيقة بسبب تجاهل الكلمات النادرة قبل بناء النموذج (نتجاهلها من أجل "تبسيط التعلم").

إخراج النموذج في هذه المرحلة يترك الكثير مما هو مرغوب فيه. "يتذكر" النموذج بنجاح بعض أسماء الأندية وأسماء لاعبي كرة القدم ، لكنه عملياً لم يلتقط السياق نفسه.
على الرغم من النهج الأكثر حداثة لاستئناف الاستخراج ، لا تزال هذه الخوارزمية أدنى من النماذج الاستخراجية التي تم إنشاؤها مسبقًا. ومع ذلك ، من أجل تحسين جودة النموذج ، من الممكن تدريب النموذج على مجموعة بيانات أكبر ، ولكن ، في رأيي ، من أجل الحصول على ناتج نموذج جيد حقًا ، من الضروري تغيير أو ، ربما ، تغيير بنية الشبكات العصبية المستخدمة.
إذن أي نهج أفضل؟
بتلخيص هذه المقالة ، سأقوم بإدراج الإيجابيات والسلبيات الرئيسية للمقاربات التي تمت مراجعتها لاستخراج الملخص:
1. النهج الاستخراجي:
المزايا:
- جوهر الخوارزمية بديهي
- سهولة نسبية في التنفيذ
سلبيات:
- يمكن أن تكون جودة المحتوى في كثير من الحالات أسوأ من المحتوى المكتوب بخط اليد
2. النهج التجريدي:
المزايا:
- الخوارزمية جيدة التنفيذ قادرة على إنتاج نتيجة أقرب إلى كتابة السيرة الذاتية اليدوية
سلبيات:
- الصعوبات في إدراك الأفكار النظرية الرئيسية للخوارزمية
- تكاليف العمالة الكبيرة في تنفيذ الخوارزمية
لا توجد إجابة لا لبس فيها على السؤال عن النهج الأفضل لتشكيل السيرة الذاتية النهائية. كل هذا يتوقف على المهمة والأهداف المحددة للمستخدم. على سبيل المثال ، من المرجح أن تكون الخوارزمية الاستخراجية مناسبة بشكل أفضل لإنشاء محتوى مستندات متعددة الصفحات ، حيث يمكن لاستخراج الجمل ذات الصلة أن ينقل فكرة النص الكبير بشكل صحيح.
في رأيي ، المستقبل ينتمي إلى الخوارزميات التجريدية. على الرغم من حقيقة أنه في الوقت الحالي يتم تطويرها بشكل ضعيف وعلى مستوى معين من جودة الإخراج لا يمكن استخدامها إلا لإنشاء ملخصات صغيرة (1-2 جمل) ، فمن الجدير توقع اختراق من أساليب الشبكة العصبية. في المستقبل ، سيكونون قادرين على تكوين محتوى لأي حجم من النصوص تمامًا ، والأهم من ذلك ، سيكون المحتوى نفسه أقرب ما يمكن إلى الإعداد اليدوي للسيرة الذاتية بواسطة خبير في مجال معين.
فيكلينكو فلاد ، محلل نظم ،
مجموعة كوديكس