ولكن كيف يعمل تعقب الكائن بالضبط؟ هناك العديد من حلول التعلم العميق لهذه المشكلة ، واليوم أريد أن أتحدث عن حل مشترك والرياضيات الكامنة وراءه.
لذلك ، سأحاول في هذه المقالة أن أخبرك بكلمات وصيغ بسيطة حول:
- YOLO هو كاشف رائع للأشياء
- مرشحات كالمان
- مسافة ماهالانوبيس
- ترتيب عميق
YOLO هو كاشف رائع للأشياء
تحتاج على الفور إلى تدوين ملاحظة مهمة للغاية تحتاج إلى تذكرها - لا يعد اكتشاف الكائن تتبعًا لكائن. بالنسبة للكثيرين ، لن تكون هذه أخبارًا ، لكن غالبًا ما يخلط الناس بين هذه المفاهيم. بكلمات بسيطة:
اكتشاف الكائن هو ببساطة تعريف الكائنات في الصورة / الإطار. أي أن الخوارزمية أو الشبكة العصبية تحدد كائنًا وتسجل موضعه والمربعات المحيطة به (معلمات المستطيلات حول الكائنات). حتى الآن ، لا يوجد حديث عن إطارات أخرى ، وتعمل الخوارزمية مع إطار واحد فقط.
مثال:
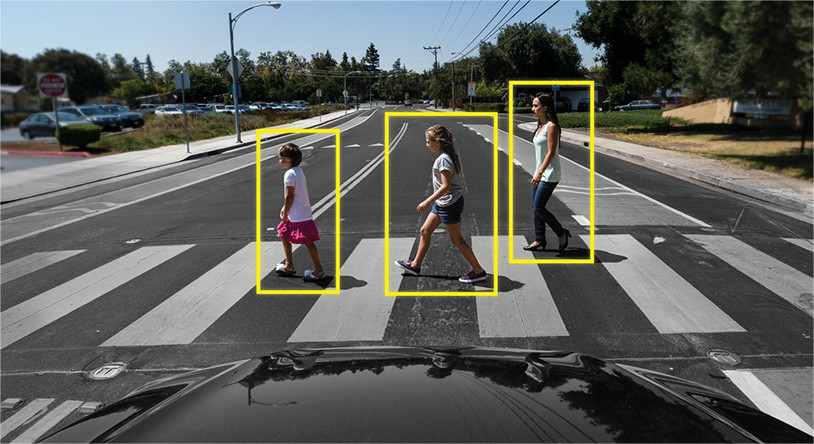
تتبع الكائن هو أمر آخر تمامًا. المهمة هنا ليست فقط تحديد الكائنات في الإطار ، ولكن أيضًا لربط المعلومات من الإطارات السابقة بطريقة لا تفقد الكائن ، أو تجعله فريدًا.
مثال:

أي أن Object Tracker يتضمن اكتشاف الكائنات لتحديد الكائنات وخوارزميات أخرى لفهم أي كائن في إطار جديد ينتمي إلى أي من الإطار السابق.
لذلك ، يلعب اكتشاف الكائن دورًا مهمًا جدًا في مهمة التتبع.
لماذا YOLO؟ نعم ، لأن YOLO تعتبر أكثر كفاءة من العديد من الخوارزميات الأخرى لتحديد الكائنات. فيما يلي رسم بياني صغير للمقارنة من المبدعين في YOLO:
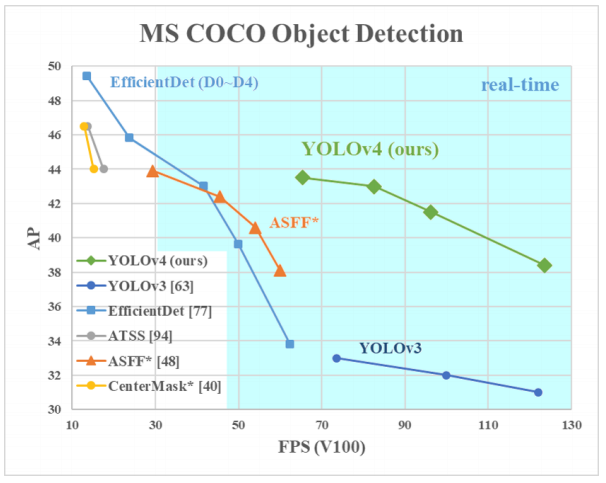
نحن هنا ننظر إلى YOLOv3-4 لأنها أحدث الإصدارات وأكثر كفاءة من الإصدارات السابقة.
معماريات أجهزة كشف الأجسام المختلفة
لذلك ، هناك العديد من بنيات الشبكات العصبية المصممة لتعريف الكائنات. يتم تصنيفها عمومًا إلى "مستويين" مثل RCNN و RCNN السريع و RCNN الأسرع و "الطبقة الواحدة" مثل YOLO.
تستخدم الشبكات العصبية "ذات الطبقتين" المذكورة أعلاه ما يسمى بالمناطق في الصورة لتحديد ما إذا كان كائن معين في تلك المنطقة.
عادةً ما يبدو هكذا (بالنسبة لـ RCNN الأسرع ، وهو الأسرع بين نظامي المستوى المدرجين):
- يتم تغذية الصورة / الإطار إلى الإدخال
- يتم تشغيل الإطار من خلال CNN لتشكيل خرائط المعالم
- تحدد الشبكة العصبية المنفصلة المناطق ذات الاحتمالية العالية للعثور على كائنات فيها
- بعد ذلك ، باستخدام تجميع ROI ، يتم ضغط هذه المناطق وإدخالها في الشبكة العصبية ، والتي تحدد فئة الكائن في المناطق

لكن هذه الشبكات العصبية لديها مشكلتان رئيسيتان: فهي لا تنظر إلى الصورة الكاملة ، ولكن فقط في المناطق الفردية ، وهي بطيئة نسبيًا.
ما هو الشيء الرائع في YOLO؟ حقيقة أن هذه البنية لا تحتوي على مشكلتين من الأعلى ، وقد أثبتت فعاليتها مرارًا وتكرارًا.
بشكل عام ، لا تختلف بنية YOLO في الكتل الأولى كثيرًا من حيث "منطق الكتلة" من أجهزة الكشف الأخرى ، أي يتم تغذية الصورة إلى الإدخال ، ثم يتم إنشاء خرائط الميزات باستخدام CNN (على الرغم من أن YOLO تستخدم شبكة CNN الخاصة بها والتي تسمى Darknet-53) ، ثم خرائط الميزات هذه يتم تحليلها بطريقة معينة (المزيد حول هذا لاحقًا) ، مع توضيح مواقع وأحجام المربعات المحيطة والفئات التي تنتمي إليها.

ولكن ما هو العنق والتنبؤ الكثيف والتنبؤ المتقطع؟
تعاملنا مع التنبؤ المتقطع قبل قليل - إنه مجرد إعادة تكرار لكيفية عمل الخوارزميات ذات المستويين: فهي تحدد المناطق بشكل فردي ثم تصنف تلك المناطق.
العنق (أو "العنق") عبارة عن كتلة منفصلة ، يتم إنشاؤها من أجل تجميع المعلومات من طبقات منفصلة من الكتل السابقة (كما هو موضح في الشكل أعلاه) لزيادة دقة التنبؤ. إذا كنت مهتمًا بهذا ، يمكنك البحث في Google عن مصطلحات "Path Aggregation Network" و "Spatial Attention Module" و "Spatial Pyramid Pooling".
وأخيرًا ، ما يميز YOLO عن جميع البنى الأخرى هو كتلة تسمى (في صورتنا أعلاه) Dense Prediction. سنركز عليها أكثر قليلاً ، لأن هذا حل مثير للاهتمام للغاية ، والذي سمح لـ YOLO فقط باقتحام الرائد في كفاءة اكتشاف الأشياء.
يحمل YOLO (أنت تنظر مرة واحدة فقط) فلسفة النظر إلى الصورة مرة واحدة ، ولهذه المشاهدة (أي ، تشغيل واحد للصورة من خلال شبكة عصبية واحدة) لعمل جميع تعريفات الكائن الضرورية. كيف يحدث هذا؟
لذلك ، عند إخراج عمل YOLO ، نريد عادةً هذا:
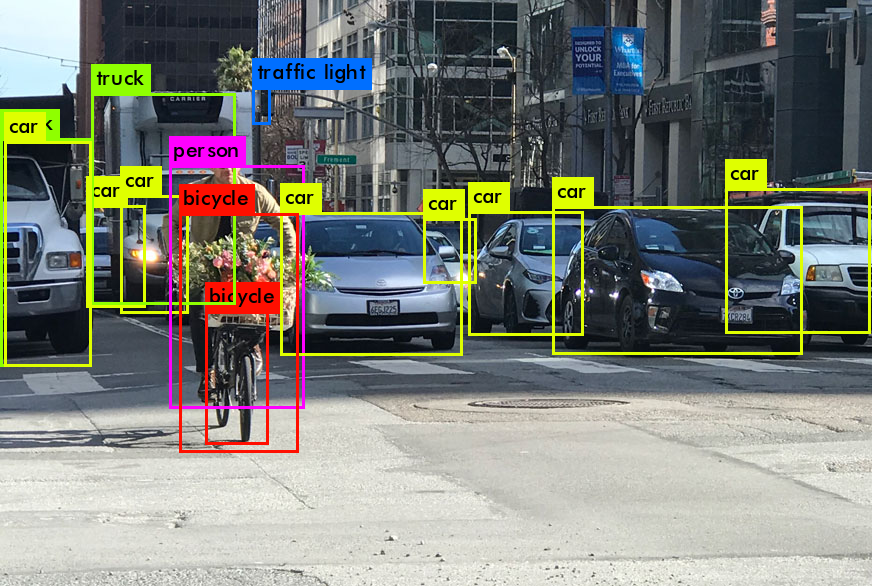
ماذا تفعل YOLO عندما تتعلم من البيانات (بكلمات بسيطة):
الخطوة 1: عادةً ، سيتم إعادة تشكيل الصور إلى حجم 416x416 قبل تدريب الشبكة العصبية ، بحيث يمكن تغذيتها على دفعات (لتسريع التعلم) ).
الخطوة 2: قسّم الصورة (حاليًا عقليًا) إلى خلايا بحجم a x a . في YOLOv3-4 ، من المعتاد التقسيم إلى خلايا بحجم 13 × 13 (سنتحدث عن مقاييس مختلفة بعد قليل لجعلها أكثر وضوحًا).

الآن دعونا نركز على هذه الخلايا التي قسمنا إليها الصورة / الإطار. هذه الخلايا ، التي تسمى الخلايا الشبكية ، هي جوهر فكرة YOLO. كل خلية هي "نقطة ارتساء" يتم إرفاق المربعات المحيطة بها. أي ، يتم رسم عدة مستطيلات حول الخلية لتحديد الكائن (نظرًا لعدم وضوح الشكل الذي سيكون المستطيل الأنسب له ، يتم رسمها في وقت واحد بأشكال متعددة ومختلفة) ، ويتم حساب مواضعها وعرضها وارتفاعها بالنسبة لمركز هذه الخلية.
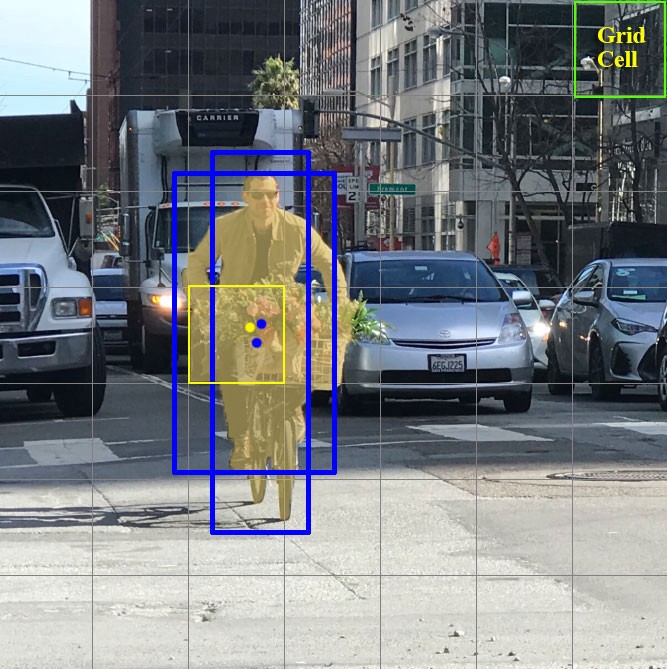
كيف يتم رسم هذه الصناديق المحيطة حول القفص؟ كيف يتم تحديد حجمهم وموقعهم؟ هذا هو المكان الذي تلعب فيه تقنية مربعات الارتساء (في الترجمة - مربعات الربط ، أو "مستطيلات الربط"). يتم تعيينها في البداية إما من قبل المستخدم نفسه ، أو يتم تحديد أحجامها بناءً على أحجام المربعات المحيطة الموجودة في مجموعة البيانات التي ستتدرب عليها YOLO (يتم استخدام مجموعات K-mean و IoU لتحديد الأحجام الأكثر ملاءمة). عادةً ما يكون هناك 3 مربعات ربط مختلفة يتم رسمها حول (أو داخل) خلية واحدة:

لماذا يتم ذلك؟ سيكون من الواضح الآن ونحن نناقش كيف يتعلم YOLO.
الخطوة 3. يتم تشغيل الصورة من مجموعة البيانات عبر شبكتنا العصبية (لاحظ أنه بالإضافة إلى الصورة الموجودة في مجموعة بيانات التدريب ، يجب أن يكون لدينا مواضع وأحجام المربعات المحيطة الحقيقية للكائنات الموجودة عليها. وهذا ما يسمى "التعليق التوضيحي" ويتم إجراؤه يدويًا في الغالب ).
دعنا الآن نفكر في ما نحتاج إلى الحصول عليه من الناتج.
لكل خلية ، نحتاج إلى فهم شيئين أساسيين:
- أي من صناديق التثبيت الثلاثة المرسومة حول القفص يناسبنا بشكل أفضل وكيف يمكننا تعديله قليلاً بحيث يتناسب تمامًا مع الكائن
- ما هو الشيء الموجود داخل صندوق التثبيت هذا وهل هو موجود على الإطلاق
ما الذي يجب أن يكون عندئذٍ ناتج YOLO؟
1. عند إخراج كل خلية ، نريد الحصول على:

2. يجب أن يشتمل الناتج على المعلمات التالية:
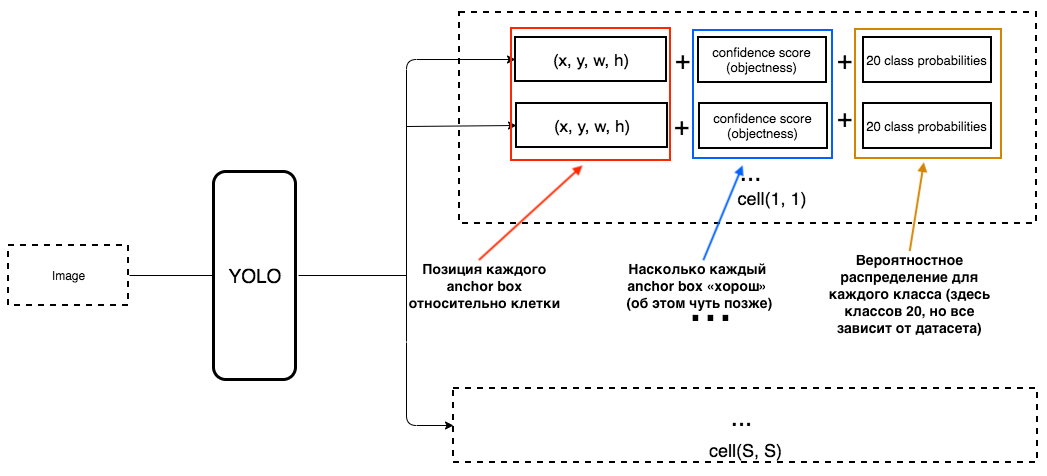
كيف يتم تحديد الكائن؟ في الواقع ، يتم تحديد هذه المعلمة باستخدام مقياس IoU أثناء التدريب. يعمل مقياس IoU على النحو التالي:
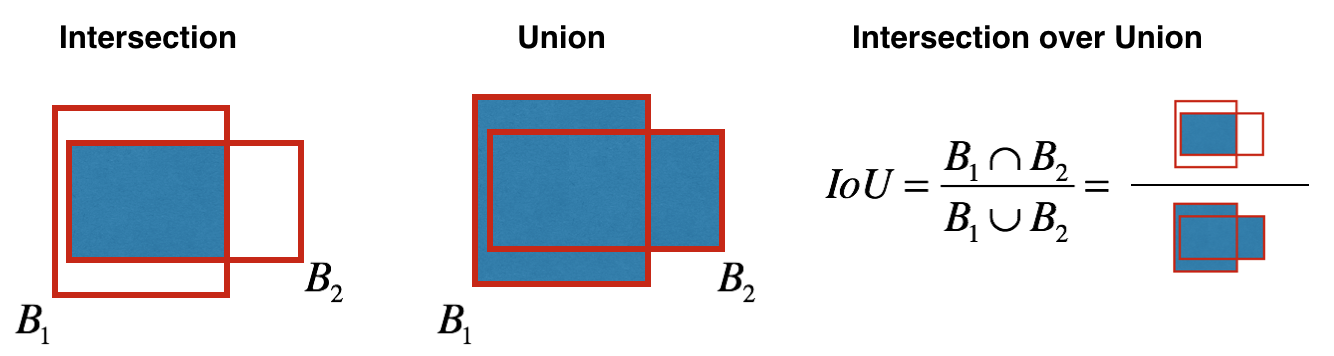
في البداية ، يمكنك تعيين حد لهذا المقياس ، وإذا كان المربع المحيط المتوقع أعلى من هذا الحد ، فسيكون له كائن يساوي واحدًا ، وسيتم استبعاد جميع المربعات المحيطة الأخرى ذات الكائن الأقل. سنحتاج إلى قيمة الكائن هذه عندما نحسب درجة الثقة الإجمالية (إلى أي مدى نحن على يقين من أن هذا هو الكائن الذي نحتاجه موجود داخل المستطيل المتوقع) لكل كائن محدد.
والآن تبدأ المتعة. دعنا نتخيل أننا منشئو YOLO ونحتاج إلى تدريبها على التعرف على الأشخاص في الإطار / الصورة. نقوم بتغذية الصورة من مجموعة البيانات إلى YOLO ، حيث يحدث استخراج الميزات في البداية ، وفي النهاية نحصل على طبقة CNN تخبرنا عن جميع الخلايا التي "قسمنا" صورتنا إليها. وإذا كانت هذه الطبقة تخبرنا "كذبة" عن الخلايا الموجودة في الصورة ، فلا بد أن يكون لدينا خسارة كبيرة ، بحيث يمكن تقليلها لاحقًا عند إدخال الصور التالية في الشبكة العصبية.
لكي نكون واضحين للغاية ، هناك رسم تخطيطي بسيط للغاية لكيفية إنشاء YOLO لهذه الطبقة الأخيرة:
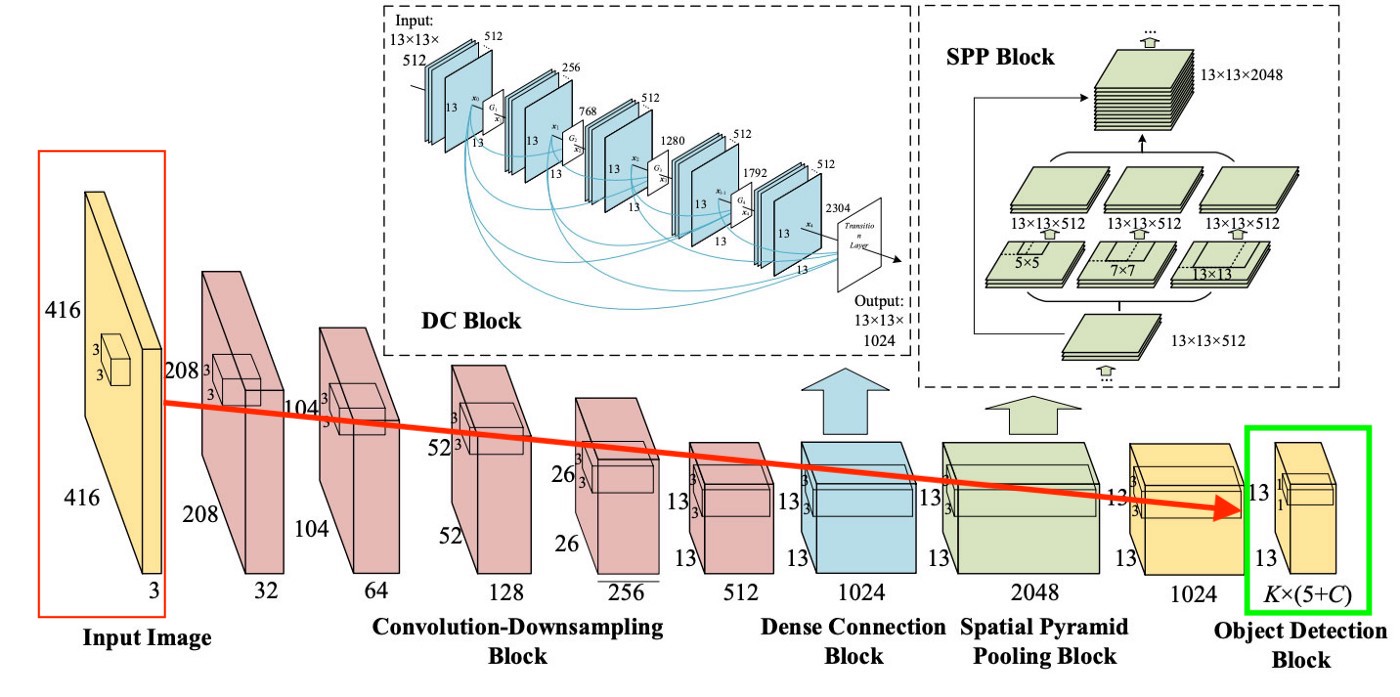
كما نرى من الصورة هذه الطبقة هي 13x13 (للصور الحجم الأولي 416x416) للتحدث عن "كل خلية" في الصورة. من هذه الطبقة الأخيرة ، يتم الحصول على المعلومات التي نريدها.
تتوقع YOLO 5 معلمات (لكل مربع ربط لخلية معينة):

لتسهيل الفهم ، هناك تصور جيد حول هذا الموضوع:

كما يمكنك فهمها من هذه الصورة ، تتمثل مهمة YOLO في توقع هذه المعلمات بأكبر قدر ممكن من الدقة لتحديد الكائن في الصورة بأكبر قدر ممكن من الدقة. ودرجة الثقة ، التي يتم تحديدها لكل مربع محيط متوقع ، هي نوع من المرشحات لتصفية التنبؤات غير الدقيقة تمامًا. لكل مربع محيط متوقع ، نقوم بضرب IoU الخاص به في احتمال أن يكون هذا كائنًا معينًا (يتم حساب توزيع الاحتمالات أثناء تدريب الشبكة العصبية) ، ونأخذ أفضل احتمال من كل ما هو ممكن ، وإذا تجاوز الرقم بعد الضرب عتبة معينة ، فيمكننا ترك هذا التنبؤ المربع المحيط في الصورة.
علاوة على ذلك ، عندما نتوقع فقط المربعات المحيطة بدرجة ثقة عالية ، فقد تبدو توقعاتنا (إذا تم تصورها) شيئًا كالتالي:

يمكننا الآن استخدام تقنية NMS (عدم الحد الأقصى للقمع) لتصفية المربعات المحيطة بطريقة من كائن واحد لم يكن هناك سوى مربع محيط واحد متوقع.

يجب أن تعلم أيضًا أنه يتم توقع YOLOv3-4 على 3 مستويات مختلفة. أي أن الصورة مقسمة إلى 64 خلية شبكية ، و 256 خلية ، و 1024 خلية من أجل رؤية الكائنات الصغيرة أيضًا. لكل مجموعة من الخلايا ، تكرر الخوارزمية الإجراءات اللازمة أثناء التنبؤ / التعلم ، والتي تم وصفها أعلاه.
تم استخدام العديد من التقنيات في YOLOv4 لزيادة دقة النموذج دون فقدان الكثير من السرعة. ولكن بالنسبة للتنبؤ نفسه ، تم ترك Dense Prediction كما هو في YOLOv3. إذا كنت مهتمًا بما فعله المؤلفون بطريقة سحرية لزيادة الدقة دون فقدان السرعة ، فهناك مقال ممتاز مكتوب عن YOLOv4 .
آمل أن أكون قادرًا على نقل القليل عن كيفية عمل YOLO بشكل عام (بشكل أكثر دقة ، الإصداران الأخيران ، أي YOLOv3 و YOLOv4) ، وهذا سوف يوقظ فيك الرغبة في استخدام هذا النموذج في المستقبل ، أو معرفة المزيد عن عمله.
الآن بعد أن اكتشفنا ما قد يكون أفضل شبكة عصبية لاكتشاف الكائنات (من حيث السرعة / الجودة) ، دعنا ننتقل أخيرًا إلى كيفية ربط المعلومات حول كائنات YOLO الخاصة بنا بين إطارات الفيديو. كيف يفهم البرنامج أن الشخص في الإطار السابق هو نفس الشخص في الإطار الجديد؟
ترتيب عميق
لفهم هذه التكنولوجيا ، يجب عليك أولاً فهم بعض الجوانب الرياضية - مسافة ماهالونوبيس ومرشح كالمان.
مسافة Mahalonobis
دعونا نلقي نظرة على مثال بسيط للغاية لفهم حدسي لمسافة Maholonobis ولماذا هناك حاجة إليها. ربما يعرف الكثير من الناس ما هي المسافة الإقليدية. عادة ، هذه هي المسافة من نقطة إلى أخرى في الفضاء الإقليدي:
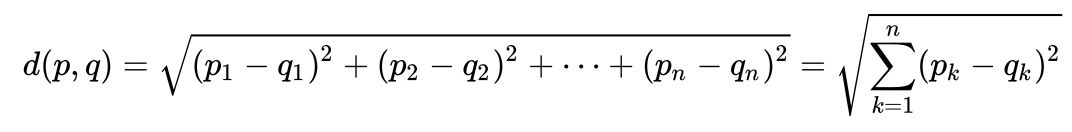

لنفترض أن لدينا متغيرين - X1 و X2. لكل منهم أبعاد كثيرة.
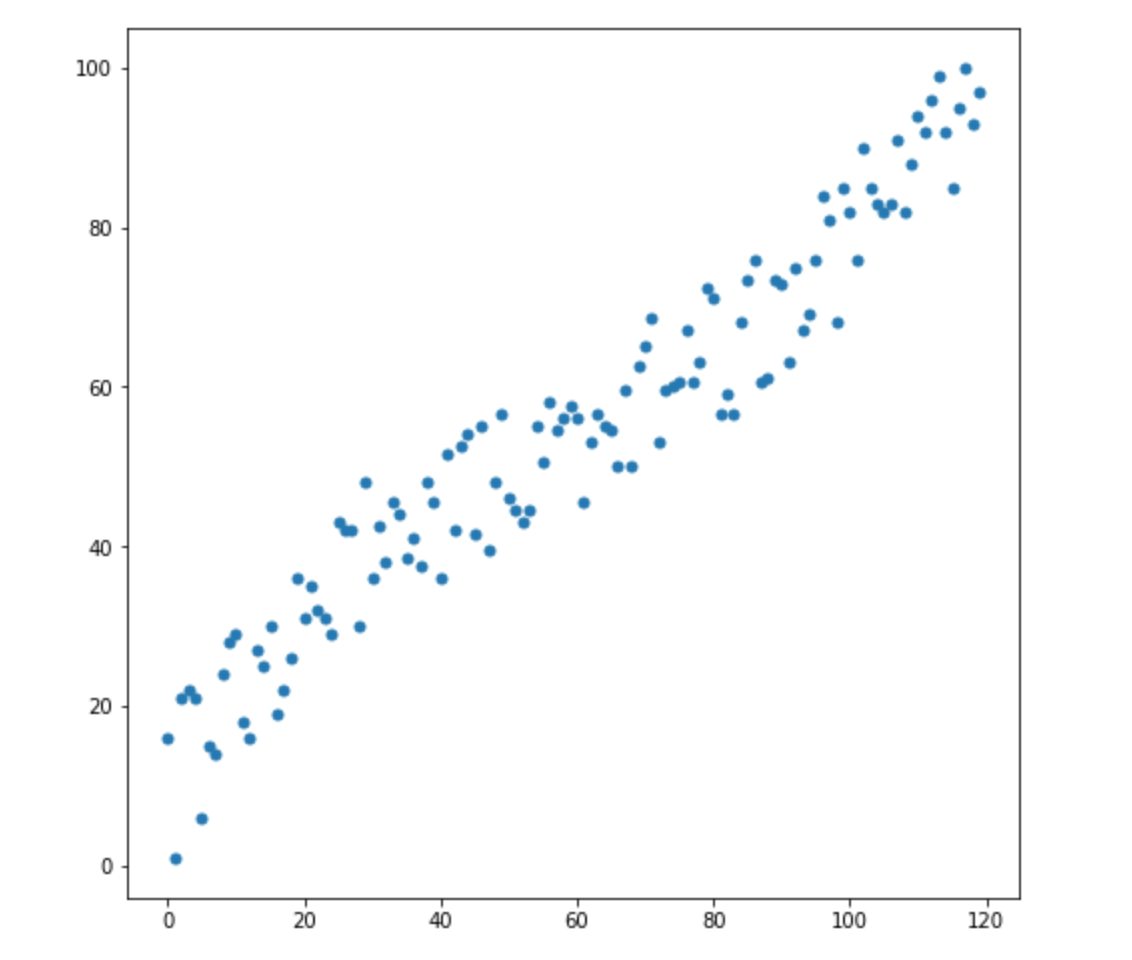
الآن ، لنفترض أن لدينا بعدين جديدين:
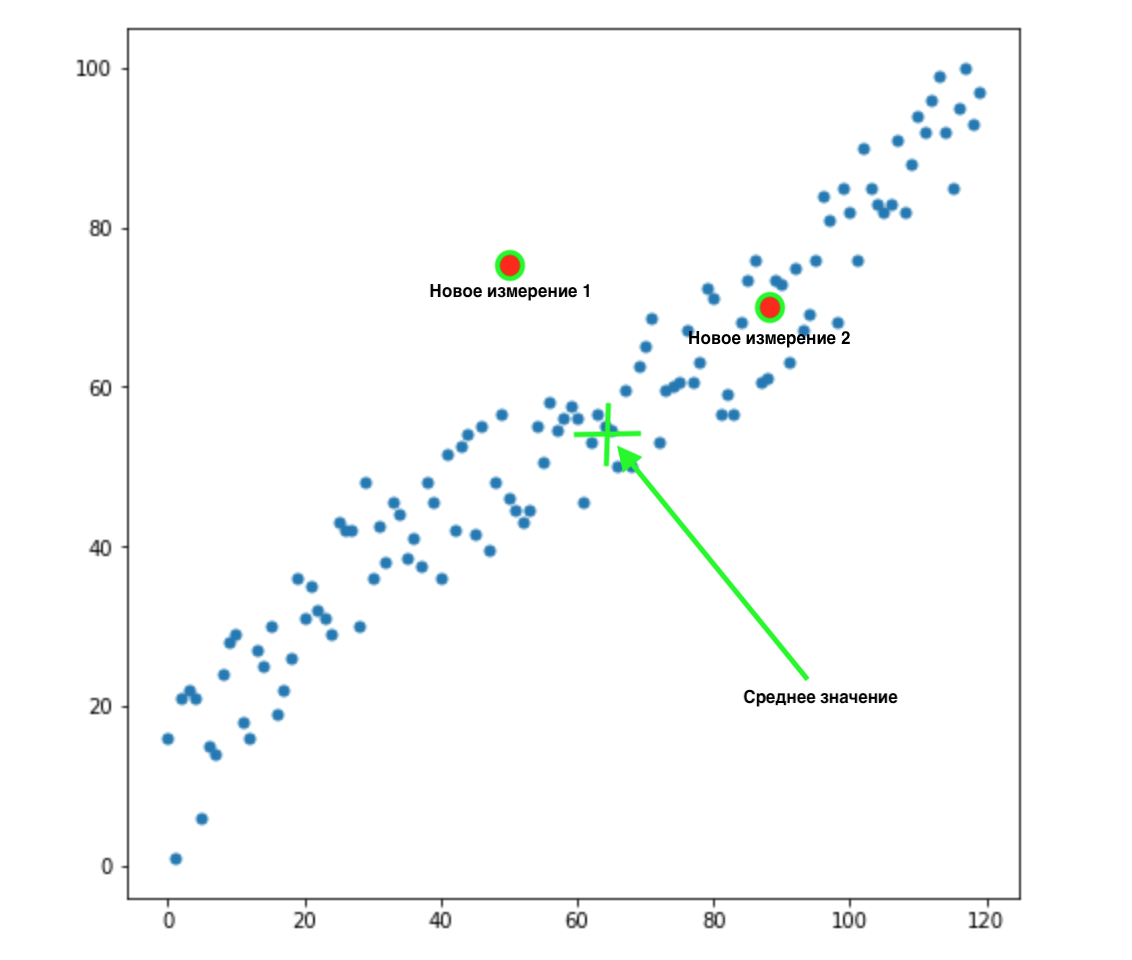
كيف نعرف أي من هاتين القيمتين هو الأنسب لتوزيعنا؟ كل شيء واضح للعين - النقطة 2 تناسبنا. لكن المسافة الإقليدية عن المتوسط هي نفسها لكلا النقطتين. وبناءً على ذلك ، فإن المسافة الإقليدية البسيطة إلى الوسط لن تعمل بالنسبة لنا.
كما نرى من الصورة أعلاه ، فإن المتغيرات مرتبطة ببعضها البعض بقوة. إذا لم يترابطوا مع بعضهم البعض ، أو كانوا أقل ارتباطًا ، فيمكننا أن نغلق أعيننا ونطبق المسافة الإقليدية لمهام معينة ، ولكن هنا نحتاج إلى تصحيح الارتباط وأخذها في الاعتبار.
هذا هو بالضبط ما تستطيع مسافة Mahalonobis التعامل معه. نظرًا لوجود أكثر من متغيرين في مجموعات البيانات ، فسنستخدم مصفوفة التغاير بدلاً من الارتباط:
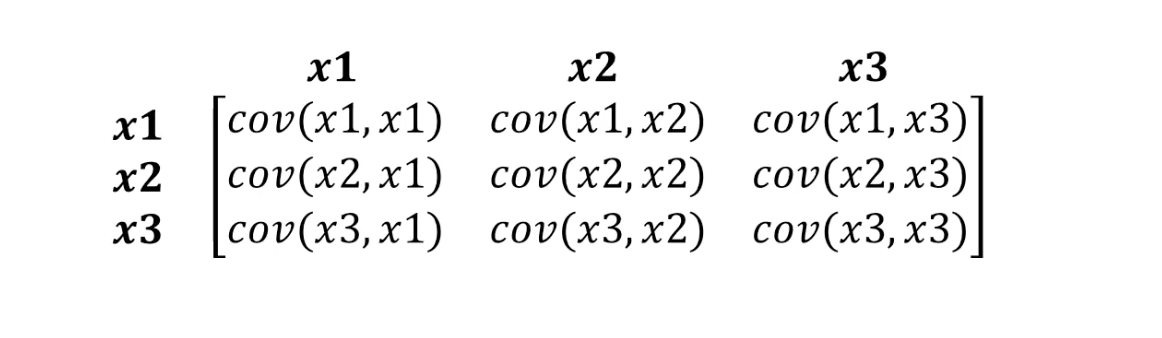
ما هي مسافة ماهالونوبيس في الواقع:
- تخلص من التغاير المتغير
- يجعل تباين المتغيرات يساوي 1
- ثم يستخدم المسافة الإقليدية المعتادة للبيانات المحولة.
لنلقِ نظرة على معادلة كيفية حساب مسافة ماهالونوبيس:

لنرى ما تعنيه مكونات الصيغة:
- هذا الاختلاف هو الفرق بين نقطتنا الجديدة ووسائل كل متغير
- S هي مصفوفة التغاير التي تحدثنا عنها قبل قليل.
يمكن فهم شيء مهم للغاية من الصيغة. نحن في الواقع نضرب في مصفوفة التغاير المقلوب. في هذه الحالة ، كلما زاد الارتباط بين المتغيرات ، زادت احتمالية تقصير المسافة ، لأننا سنضرب في معكوس رقم أكبر - أي رقم أصغر (بكلمات بسيطة).
دعونا لا ندخل في تفاصيل الجبر الخطي ، كل ما نحتاج إلى فهمه هو أننا نقيس المسافة بين النقاط بطريقة تأخذ في الاعتبار تباين المتغيرات والتغاير بينها.
مرشح كالمان
لإدراك أن هذا شيء رائع ومثبت ويمكن تطبيقه في العديد من المجالات ، يكفي أن تعرف أن مرشح كالمان قد تم استخدامه في الستينيات. نعم ، نعم ، أنا ألمح إلى هذا - الرحلة إلى القمر. تم تطبيقه هناك في عدة أماكن ، بما في ذلك العمل مع مسارات طيران ذهابًا وإيابًا. غالبًا ما يستخدم مرشح كالمان في تحليل السلاسل الزمنية في الأسواق المالية ، في تحليل مؤشرات أجهزة الاستشعار المختلفة في المصانع والمؤسسات والعديد من الأماكن الأخرى. آمل أن أكون قد نجحت في إثارة إعجابك قليلاً وسنصف بإيجاز مرشح Kalman وكيف يعمل. أنصحك أيضًا بقراءة هذا المقال عن حبري إذا كنت تريد معرفة المزيد عنه.
مرشح كالمان
, . , , .
, . 4 . , 72 .
3 :
1) (Kalman Gain):

, - ( ).
2) , ( , ), , .

3) (), :
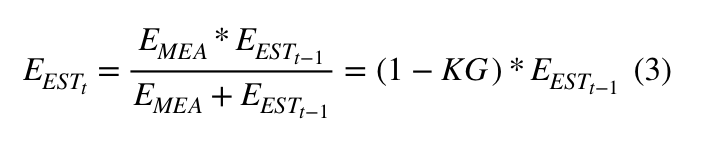
, :
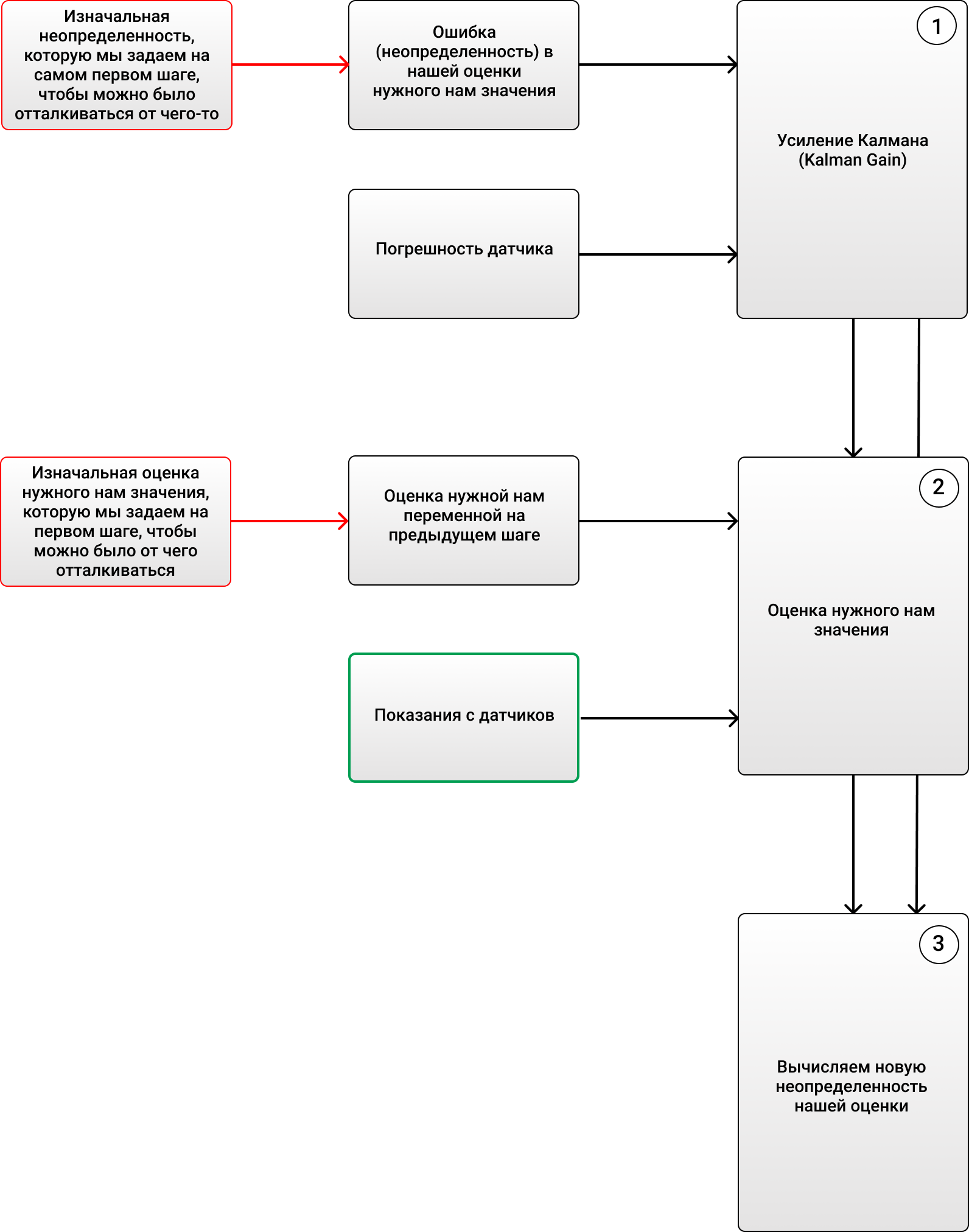
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
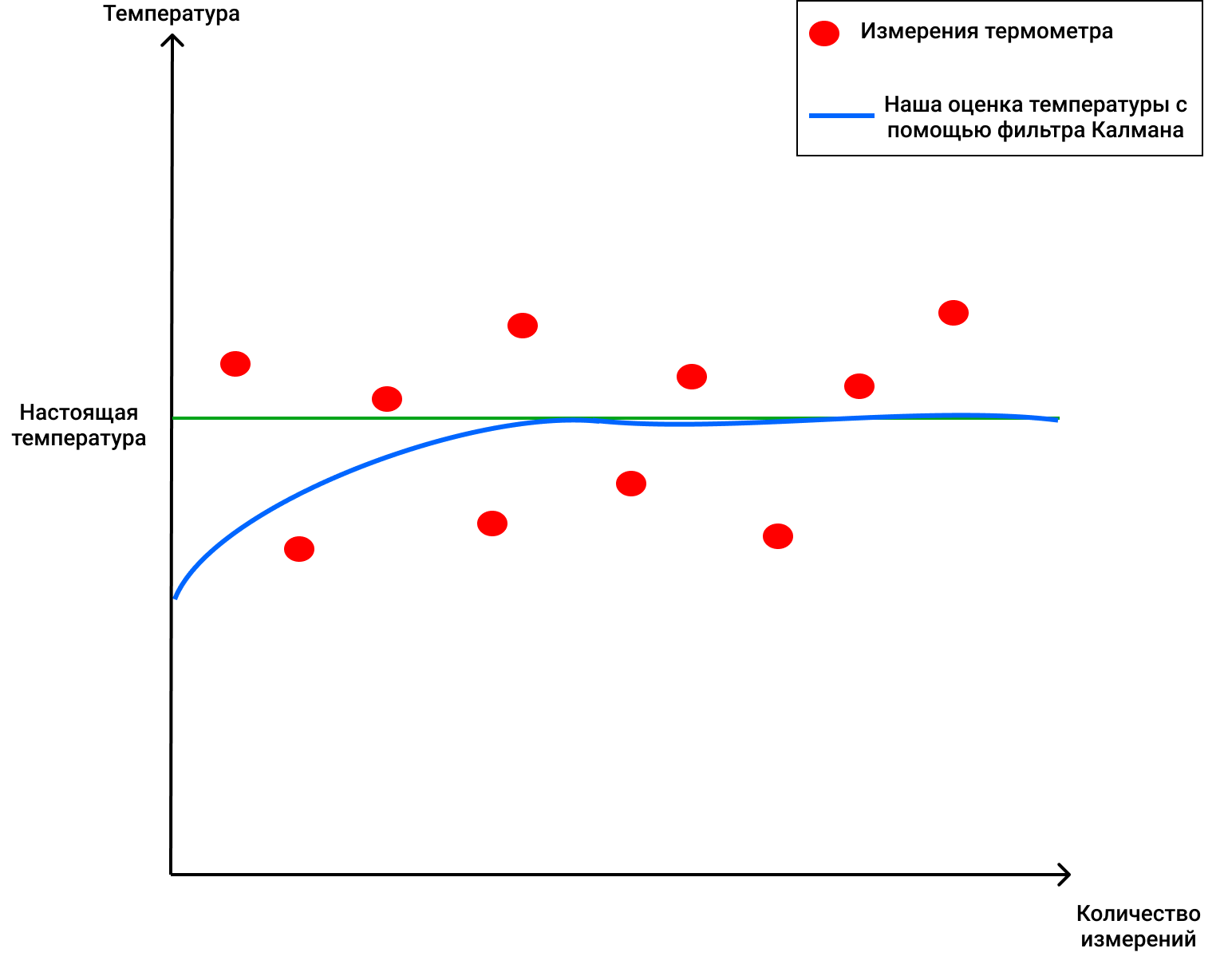
, !
, , , , , ( , ).
, . 4 . , 72 .
3 :
1) (Kalman Gain):
, - ( ).
2) , ( , ), , .
3) (), :
, :
, 69 ( ), 2 . , , 4 (, , ), KG (1) 2/(2+4) = 0.33. ( ), . 70 (), . (2), , 68+0.33(70-68)=68.66. (3) (1-0.33)2 = 1.32. , , , . :
, !
, , , , , ( , ).
DeepSORT - أخيرًا!
لذلك ، نحن نعرف الآن ما هو مرشح كالمان ومسافة ماهالونوبيس. تقوم تقنية DeepSORT ببساطة بربط الاثنين معًا من أجل نقل المعلومات من إطار إلى آخر ، وتضيف مقياسًا جديدًا يسمى المظهر. أولاً ، باستخدام اكتشاف الكائن ، يتم تحديد موضع وحجم وفئة مربع محيط واحد. ثم يمكنك ، من حيث المبدأ ، تطبيق الخوارزمية المجرية لربط كائنات معينة بمعرفات الكائنات التي كانت موجودة سابقًا في الإطار وتم تتبعها باستخدام مرشحات كالمان - وسيكون كل شيء رائعًا ، كما هو الحال في SORT الأصلي... لكن تقنية DeepSORT تسمح بتحسين دقة الكشف وتقليل عدد التبديل بين الكائنات ، على سبيل المثال ، عندما يقوم شخص ما في الإطار بإعاقة شخص آخر لفترة وجيزة ، والآن يعتبر الشخص الذي تم إعاقته كائنًا جديدًا. كيف فعلت ذلك؟
تضيف عنصرًا رائعًا إلى عملها - ما يسمى بـ "مظهر" الأشخاص الذين يظهرون في الإطار (المظهر). تم تدريب هذا المظهر من خلال شبكة عصبية منفصلة تم إنشاؤها بواسطة مؤلفي DeepSORT. استخدموا حوالي 1100000 صورة من أكثر من 1000 شخص مختلف لجعل الشبكة العصبية تتنبأ بشكل صحيحتوجد مشكلة في SORT الأصلي - نظرًا لعدم استخدام مظهر الكائن هناك ، في الواقع ، عندما يغطي الكائن شيئًا لعدة إطارات (على سبيل المثال ، شخص آخر أو عمود داخل مبنى) ، تقوم الخوارزمية بعد ذلك بتعيين معرف آخر لهذا الشخص - نتيجة لذلك حيث أن ما يسمى ب "ذاكرة" الكائنات في SORT الأصلي هي إلى حد ما قصيرة العمر.
حتى الآن للأجسام خاصيتان - ديناميكيات حركتها ومظهرها. بالنسبة للديناميكيات ، لدينا مؤشرات تمت تصفيتها والتنبؤ بها باستخدام مرشح كالمان - (u ، v ، a ، h ، u '، v' ، a '، h') ، حيث u ، v هو موضع X للمستطيل المتوقع و Y ، a هي نسبة العرض إلى الارتفاع للمستطيل المتوقع ، h هي ارتفاع المستطيل ، والمشتقات بالنسبة لكل قيمة. من أجل المظهر ، تم تدريب شبكة عصبية ، لها الهيكل:
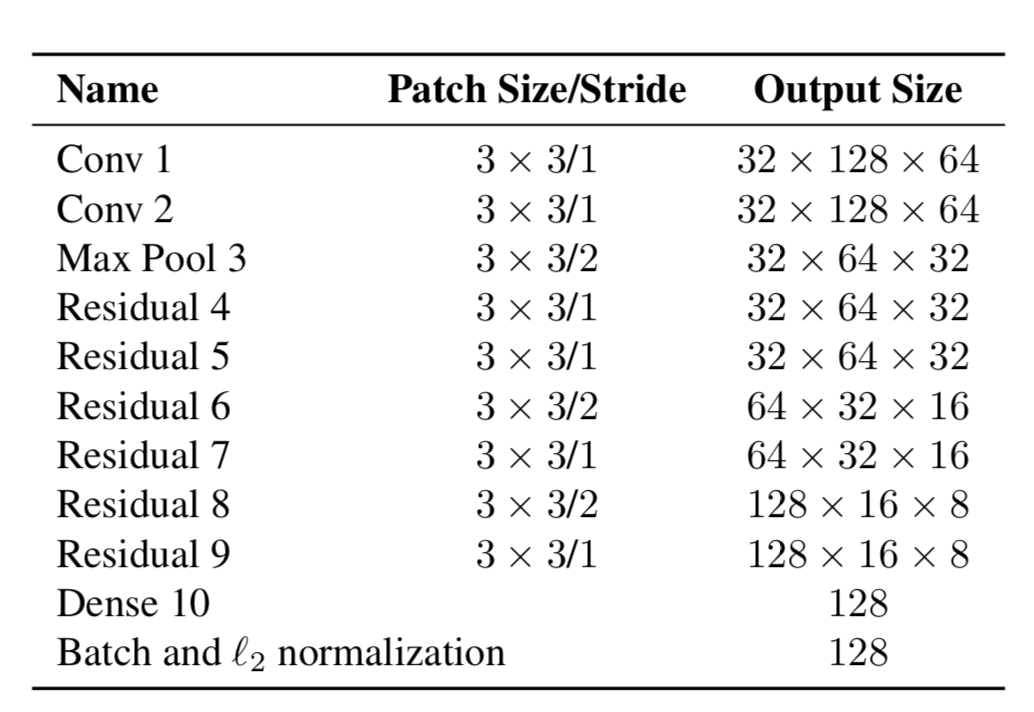
وفي النهاية ، أنتجت متجهًا مميزًا ، بحجم 128 × 1. وبعد ذلك ، بدلاً من حساب المسافة بين كائنات معينة باستخدام YOLO ، والأشياء التي اتبعناها بالفعل في الإطار ، ثم تعيين معرف معين باستخدام مسافة Mahalonobis ، أنشأ المؤلفون مقياسًا جديدًا لحساب المسافة ، والذي يتضمن كلا التنبؤين باستخدام مرشحات كالمان ، و "مسافة جيب التمام" ، كما يطلق عليه بخلاف ذلك ، معامل أوتياي.
نتيجة لذلك ، فإن المسافة من كائن YOLO معين إلى الكائن الذي تنبأ به مرشح Kalman (أو كائن موجود بالفعل بين تلك التي لوحظت في الإطارات السابقة) هي:

حيث Da هي مسافة التشابه الخارجية و Dk هي مسافة Mahalonobis. علاوة على ذلك ، يتم استخدام هذه المسافة الهجينة في الخوارزمية المجرية من أجل فرز كائنات معينة بشكل صحيح باستخدام المعرفات الموجودة.
وبالتالي ، ساعد مقياس إضافي بسيط Da في إنشاء خوارزمية DeepSORT جديدة وأنيقة تُستخدم في العديد من المشكلات وتحظى بشعبية كبيرة في مشكلة تتبع الكائنات.
تبين أن المقال ثقيل للغاية ، وذلك بفضل أولئك الذين قرأوا حتى النهاية! آمل أن أكون قادرًا على إخبارك بشيء جديد ومساعدتك على فهم كيفية عمل تتبع الكائن على YOLO و DeepSORT.