
عندما بدأت حياتي المهنية كمطور ، كانت وظيفتي الأولى هي DBA (مسؤول قاعدة البيانات ، DBA). في تلك السنوات ، حتى قبل AWS RDS و Azure و Google Cloud والخدمات السحابية الأخرى ، كان هناك نوعان من DBAs:
- , . « », , .
- : , , SQL. ETL- . , .
عادة ما يكون مسؤولو قواعد البيانات في التطبيق جزءًا من فرق التطوير. لديهم معرفة عميقة بموضوع معين ، لذلك عادة ما يعملون فقط في مشروع واحد أو مشروعين. كان مسؤولو قواعد البيانات في البنية التحتية عادة جزءًا من فريق تكنولوجيا المعلومات ويمكنهم العمل في مشاريع متعددة في نفس الوقت.
أنا مسؤول قاعدة بيانات التطبيق
لم يكن لدي أبدًا الرغبة في العبث بالنسخ الاحتياطية أو تخزين القرص (أنا متأكد من أنه ممتع!). حتى يومنا هذا ، أود أن أقول إنني مسؤول قاعدة بيانات أعرف كيفية تطوير التطبيقات ، ولست مطورًا يفهم قواعد البيانات.
في هذه المقالة ، سأشارك بعض حيل تطوير قاعدة البيانات التي تعلمتها خلال مسيرتي المهنية.
المحتوى:
- قم بتحديث فقط ما يحتاج إلى التحديث
- تعطيل القيود والفهارس للأحمال الثقيلة
- استخدم جداول UNLOGGED للبيانات الوسيطة
- تنفيذ عمليات كاملة مع مع والعودة
- تجنب المؤشرات في الأعمدة ذات الانتقائية المنخفضة
- استخدم الفهارس الجزئية
- دائما تحميل البيانات المصنفة
- فهرس الأعمدة شديد الارتباط بـ BRIN
- جعل الفهارس "غير مرئية"
- لا تقم بجدولة عمليات طويلة لتبدأ في بداية أي ساعة
- خاتمة
قم بتحديث فقط ما يحتاج إلى التحديث
العملية
UPDATEتستهلك الكثير من الموارد. أفضل طريقة لتسريعها هي تحديث ما يحتاج إلى تحديث فقط.
فيما يلي مثال لطلب تسوية عمود بريد إلكتروني:
db=# UPDATE users SET email = lower(email);
UPDATE 1010000
Time: 1583.935 ms (00:01.584)
تبدو بريئة ، أليس كذلك؟ يقوم الطلب بتحديث عناوين البريد لـ 1010.000 مستخدم. لكن هل كل الصفوف بحاجة للتحديث؟
db=# UPDATE users SET email = lower(email)
db-# WHERE email != lower(email);
UPDATE 10000
Time: 299.470 ms
يلزم تحديث 10000 صف فقط. بتقليل كمية البيانات التي تمت معالجتها ، قللنا وقت التنفيذ من 1.5 ثانية إلى أقل من 300 مللي ثانية. سيوفر لنا هذا أيضًا المزيد من الجهد في الحفاظ على قاعدة البيانات.
فقط قم بتحديث ما يحتاج إلى تحديث.
هذا النوع من التحديث الكبير شائع جدًا في البرامج النصية لترحيل البيانات. في المرة التالية التي تكتب فيها نصًا كهذا ، تأكد من تحديث ما هو مطلوب فقط.
تعطيل القيود والفهارس للأحمال الثقيلة
تعتبر القيود جزءًا مهمًا من قواعد البيانات العلائقية: فهي تحافظ على اتساق البيانات وموثوقيتها. لكن كل شيء له سعره الخاص ، وفي أغلب الأحيان ، يتعين عليك الدفع عند تحميل أو تحديث عدد كبير من الصفوف.
دعنا نحدد مخطط تخزين صغير:
DROP TABLE IF EXISTS product CASCADE;
CREATE TABLE product (
id serial PRIMARY KEY,
name TEXT NOT NULL,
price INT NOT NULL
);
INSERT INTO product (name, price)
SELECT random()::text, (random() * 1000)::int
FROM generate_series(0, 10000);
DROP TABLE IF EXISTS customer CASCADE;
CREATE TABLE customer (
id serial PRIMARY KEY,
name TEXT NOT NULL
);
INSERT INTO customer (name)
SELECT random()::text
FROM generate_series(0, 100000);
DROP TABLE IF EXISTS sale;
CREATE TABLE sale (
id serial PRIMARY KEY,
created timestamptz NOT NULL,
product_id int NOT NULL,
customer_id int NOT NULL
);
يحدد هذا أنواعًا مختلفة من القيود مثل "غير فارغة" بالإضافة إلى القيود الفريدة ...
لتعيين نقطة البداية ، فلنبدأ في إضافة
saleمفاتيح خارجية إلى الجدول
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 18.413 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 5.464 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 12.605 ms
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 15410.234 ms (00:15.410)
بعد تحديد القيود والفهارس ، استغرق تحميل مليون صف في الجدول حوالي 15.4 ثانية.
الآن ، أولاً ، دعنا نحمل البيانات في الجدول ، وبعد ذلك فقط نضيف القيود والفهارس:
db=# INSERT INTO SALE (created, product_id, customer_id)
db-# SELECT
db-# now() - interval '1 hour' * random() * 1000,
db-# (random() * 10000)::int + 1,
db-# (random() * 100000)::int + 1
db-# FROM generate_series(1, 1000000);
INSERT 0 1000000
Time: 2277.824 ms (00:02.278)
db=# ALTER TABLE sale ADD CONSTRAINT sale_product_fk
db-# FOREIGN KEY (product_id) REFERENCES product(id);
ALTER TABLE
Time: 169.193 ms
db=# ALTER TABLE sale ADD CONSTRAINT sale_customer_fk
db-# FOREIGN KEY (customer_id) REFERENCES customer(id);
ALTER TABLE
Time: 185.633 ms
db=# CREATE INDEX sale_created_ix ON sale(created);
CREATE INDEX
Time: 484.244 ms
كان التحميل أسرع بكثير ، 2.27 ثانية. بدلاً من 15.4. تم إنشاء الفهارس والحدود لفترة أطول بعد تحميل البيانات ، لكن العملية برمتها كانت أسرع بكثير: 3.1 ثانية. بدلاً من 15.4.
لسوء الحظ ، في PostgreSQL ، لا يمكنك فعل الشيء نفسه مع الفهارس ، يمكنك فقط رميها وإعادة إنشائها. في قواعد البيانات الأخرى ، مثل Oracle ، يمكنك تعطيل الفهارس وتمكينها دون إعادة البناء.
UNLOGGED-
عند تغيير البيانات في PostgreSQL ، تتم كتابة التغييرات في سجل الكتابة المسبقة (WAL ). يتم استخدامه للحفاظ على الاتساق ، وإعادة الفهرسة بسرعة أثناء الاسترداد ، والحفاظ على النسخ المتماثل.
غالبًا ما تكون الكتابة إلى WAL مطلوبة ، ولكن هناك بعض الظروف التي يمكنك فيها إلغاء الاشتراك في WAL لتسريع الأمور. على سبيل المثال ، في حالة الجداول المرحلية.
تسمى الجداول الوسيطة جداول المرة الواحدة ، والتي تخزن البيانات المؤقتة المستخدمة لتنفيذ بعض العمليات. على سبيل المثال ، في عمليات ETL ، من الشائع جدًا تحميل البيانات من ملفات CSV إلى جداول مرحلية ، ومسح المعلومات ، ثم تحميلها في الجدول الهدف. في هذا السيناريو ، يتم استخدام الجدول المرحلي مرة واحدة ولا يتم استخدامه في النسخ الاحتياطية أو النسخ المتماثلة.
جدول UNLOGGED.
يمكن تعيين الجداول المرحلية التي لا تحتاج إلى استرداد في حالة حدوث فشل وليست ضرورية في النسخ المتماثلة على أنها "غير مُقيدة" :
CREATE UNLOGGED TABLE staging_table ( /* table definition */ );
تحذير : قبل الاستخدام
UNLOGGED، تأكد من فهمك الكامل لجميع الآثار المترتبة.
تنفيذ عمليات كاملة مع مع والعودة
لنفترض أن لديك جدول مستخدمين ووجدت أنه يحتوي على بيانات مكررة:
Table setup
db=# SELECT u.id, u.email, o.id as order_id
FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
3 | ME@hakibenita.com | 4
3 | ME@hakibenita.com | 5
قام المستخدم haki benita بالتسجيل مرتين مع البريد
ME@hakibenita.comو me@hakibenita.com. نظرًا لأننا لا نقوم بتطبيع عناوين البريد الإلكتروني عند إدخالها في الجدول ، فعلينا الآن التعامل مع التكرارات.
نحن نحتاج:
- حدد العناوين المكررة بأحرف صغيرة وربط المستخدمين المكررة ببعضهم البعض.
- تحديث الطلبات بحيث تشير فقط إلى واحد من التكرارات.
- إزالة التكرارات من الجدول.
يمكنك ربط المستخدمين المكررون باستخدام جدول مرحلي:
db=# CREATE UNLOGGED TABLE duplicate_users AS
db-# SELECT
db-# lower(email) AS normalized_email,
db-# min(id) AS convert_to_user,
db-# array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
db-# FROM
db-# users
db-# GROUP BY
db-# normalized_email
db-# HAVING
db-# count(*) > 1;
CREATE TABLE
db=# SELECT * FROM duplicate_users;
normalized_email | convert_to_user | convert_from_users
-------------------+-----------------+--------------------
me@hakibenita.com | 2 | {3}
يحتوي الجدول الوسيط على روابط بين يأخذ. إذا ظهر مستخدم لديه عنوان بريد إلكتروني عادي أكثر من مرة ، فإننا نخصص له حدًا أدنى من معرف المستخدم ، حيث نقوم بطي جميع التكرارات. يتم تخزين باقي المستخدمين في عمود المصفوفة وسيتم تحديث كافة المراجع الخاصة بهم.
باستخدام الجدول الوسيط ، نقوم بتحديث الروابط إلى التكرارات في الجدول
orders:
db=# UPDATE
db-# orders o
db-# SET
db-# user_id = du.convert_to_user
db-# FROM
db-# duplicate_users du
db-# WHERE
db-# o.user_id = ANY(du.convert_from_users);
UPDATE 2
يمكنك الآن إزالة التكرارات بأمان من
users:
db=# DELETE FROM
db-# users
db-# WHERE
db-# id IN (
db(# SELECT unnest(convert_from_users)
db(# FROM duplicate_users
db(# );
DELETE 1
لاحظ أننا استخدمنا الدالة unnest "لتحويل" المصفوفة ، والتي تحول كل عنصر إلى سلسلة نصية .
نتيجة:
db=# SELECT u.id, u.email, o.id as order_id
db-# FROM orders o JOIN users u ON o.user_id = u.id;
id | email | order_id
----+-------------------+----------
1 | foo@bar.baz | 1
1 | foo@bar.baz | 2
2 | me@hakibenita.com | 3
2 | me@hakibenita.com | 4
2 | me@hakibenita.com | 5
عظيم، كل مستخدم
3( ME@hakibenita.com) وحالات تحويلها إلى المستخدم 2( me@hakibenita.com).
يمكننا أيضًا التحقق من إزالة التكرارات من الجدول
users:
db=# SELECT * FROM users;
id | email
----+-------------------
1 | foo@bar.baz
2 | me@hakibenita.com
الآن يمكننا التخلص من جدول التدريج:
db=# DROP TABLE duplicate_users;
DROP TABLE
لا بأس ، لكن الأمر يستغرق وقتًا طويلاً ويحتاج إلى التنظيف! هل هناك طريقة أفضل؟
تعبيرات الجدول المعممة (CTE)
باستخدام تعبيرات الجدول العامة ، والمعروفة أيضًا باسم التعبيرات
WITH، يمكننا تنفيذ الإجراء بأكمله باستخدام تعبير SQL واحد:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
)
DELETE FROM
users
WHERE
id IN (
SELECT
unnest(convert_from_users)
FROM
duplicate_users
);
بدلاً من الجدول المرحلي ، أنشأنا تعبير جدول عام وأعدنا استخدامه.
عودة النتائج من CTE
تتمثل إحدى مزايا تنفيذ DML داخل تعبير في
WITHأنه يمكنك إرجاع البيانات منه باستخدام الكلمة الأساسية RETURNING . لنفترض أننا بحاجة إلى تقرير عن عدد الصفوف المحدثة والمحذوفة:
WITH duplicate_users AS (
SELECT
min(id) AS convert_to_user,
array_remove(ARRAY_AGG(id), min(id)) as convert_from_users
FROM
users
GROUP BY
lower(email)
HAVING
count(*) > 1
),
update_orders_of_duplicate_users AS (
UPDATE
orders o
SET
user_id = du.convert_to_user
FROM
duplicate_users du
WHERE
o.user_id = ANY(du.convert_from_users)
RETURNING o.id
),
delete_duplicate_user AS (
DELETE FROM
users
WHERE
id IN (
SELECT unnest(convert_from_users)
FROM duplicate_users
)
RETURNING id
)
SELECT
(SELECT count(*) FROM update_orders_of_duplicate_users) AS orders_updated,
(SELECT count(*) FROM delete_duplicate_user) AS users_deleted
;
نتيجة:
orders_updated | users_deleted
----------------+---------------
2 | 1
يكمن جمال هذا الأسلوب في أن العملية بأكملها يتم تنفيذها بأمر واحد ، لذلك ليست هناك حاجة لإدارة المعاملات أو القلق بشأن مسح الجدول المرحلي في حالة فشل العملية.
تحذير : أشار لي أحد قراء Reddit إلى السلوك المحتمل غير المتوقع لتنفيذ DML في تعبيرات الجدول العامة :
WITHيتم تنفيذ التعبيرات الفرعية في نفس الوقت مع بعضها البعض ومع الاستعلام الرئيسي. لذلك ، عند استخدامها فيWITHتعبيرات تعديل البيانات ، سيكون الترتيب الفعلي للتحديثات غير متوقع.
هذا يعني أنه لا يمكنك الاعتماد على الترتيب الذي يتم به تنفيذ التعبيرات الفرعية المستقلة. اتضح أنه في حالة وجود تبعية بينهما ، كما في المثال أعلاه ، يمكنك الاعتماد على تنفيذ التعبير الفرعي التابع قبل استخدامها.
تجنب المؤشرات في الأعمدة ذات الانتقائية المنخفضة
لنفترض أن لديك عملية تسجيل حيث يقوم المستخدم بتسجيل الدخول على عنوان بريد إلكتروني. لتنشيط حسابك ، تحتاج إلى التحقق من بريدك. قد يبدو الجدول كما يلي:
db=# CREATE TABLE users (
db-# id serial,
db-# username text,
db-# activated boolean
db-#);
CREATE TABLE
معظم المستخدمين لديك هم مواطنون واعون ، فهم يسجلون باستخدام العنوان البريدي الصحيح ويفعلون الحساب على الفور. دعنا نملأ الجدول ببيانات المستخدم ونفترض أنه تم تنشيط 90٪ من المستخدمين:
db=# INSERT INTO users (username, activated)
db-# SELECT
db-# md5(random()::text) AS username,
db-# random() < 0.9 AS activated
db-# FROM
db-# generate_series(1, 1000000);
INSERT 0 1000000
db=# SELECT activated, count(*) FROM users GROUP BY activated;
activated | count
-----------+--------
f | 102567
t | 897433
db=# VACUUM ANALYZE users;
VACUUM
للاستعلام عن عدد المستخدمين النشطين وغير النشطين ، يمكنك إنشاء فهرس حسب العمود
activated:
db=# CREATE INDEX users_activated_ix ON users(activated);
CREATE INDEX
وإذا طلبت عدد المستخدمين غير النشطين ، فستستخدم قاعدة البيانات الفهرس:
db=# EXPLAIN SELECT * FROM users WHERE NOT activated;
QUERY PLAN
--------------------------------------------------------------------------------------
Bitmap Heap Scan on users (cost=1923.32..11282.99 rows=102567 width=38)
Filter: (NOT activated)
-> Bitmap Index Scan on users_activated_ix (cost=0.00..1897.68 rows=102567 width=0)
Index Cond: (activated = false)
قررت القاعدة أن المرشح سيعيد 102.567 عنصرًا ، أي ما يقرب من 10٪ من الجدول. يتوافق هذا مع البيانات التي قمنا بتحميلها ، لذا قام الجدول بعمل جيد.
ومع ذلك ، إذا استفسرنا عن عدد المستخدمين النشطين ، فسنجد أن قاعدة البيانات قررت عدم استخدام الفهرس :
db=# EXPLAIN SELECT * FROM users WHERE activated;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on users (cost=0.00..18334.00 rows=897433 width=38)
Filter: activated
يتم الخلط بين العديد من المطورين عندما لا تستخدم قاعدة البيانات الفهرس. لشرح سبب قيامه بذلك ، يمكنك القيام بذلك: إذا كان عليك قراءة الجدول بأكمله ، فهل ستستخدم فهرسًا ؟
ربما لا ، لماذا هذا ضروري؟ القراءة من القرص باهظة الثمن ، لذا سترغب في القراءة بأقل قدر ممكن. على سبيل المثال ، إذا كان الجدول 10 ميغا بايت والفهرس 1 ميغا بايت ، ثم لقراءة الجدول بأكمله ، يجب عليك قراءة 10 ميغا بايت من القرص. وإذا أضفت فهرسًا ، فستحصل على 11 ميغابايت. إنه مسرف.
دعنا الآن نلقي نظرة على الإحصائيات التي جمعتها PostgreSQL على طاولتنا:
db=# SELECT attname, n_distinct, most_common_vals, most_common_freqs
db-# FROM pg_stats
db-# WHERE tablename = 'users' AND attname='activated';
------------------+------------------------
attname | activated
n_distinct | 2
most_common_vals | {t,f}
most_common_freqs | {0.89743334,0.10256667}
عندما قامت PostgreSQL بتحليل الجدول ، وجدت أن
activatedهناك قيمتين مختلفتين في العمود . تتوافق القيمة tالموجودة في العمود most_common_valsمع التردد 0.89743334في العمود most_common_freqs، fوتتوافق القيمة مع التردد 0.10256667. بعد تحليل الجدول ، حددت قاعدة البيانات أن 89.74٪ من السجلات كانت مستخدمين نشطين وأن الـ 10.26٪ المتبقية لم يتم تفعيلها.
بناءً على هذه الإحصائيات ، قررت PostgreSQL أنه من الأفضل فحص الجدول بأكمله بدلاً من افتراض أن 90٪ من الصفوف تفي بالشرط. تعتمد العتبة التي يمكن لقاعدة البيانات بعدها أن تقرر ما إذا كانت ستستخدم فهرسًا على العديد من العوامل ، ولا توجد قاعدة عامة.
فهرس للأعمدة ذات الانتقائية المنخفضة والعالية.
استخدم الفهارس الجزئية
في الفصل السابق ، قمنا بإنشاء فهرس على عمود منطقي حيث كان حوالي 90٪ من السجلات
true(مستخدمون نشطون).
عندما سألنا عن عدد المستخدمين النشطين ، لم تستخدم قاعدة البيانات الفهرس. وعندما سئل عن عدد غير المفعلة ، استخدمت قاعدة البيانات الفهرس.
السؤال الذي يطرح نفسه: إذا كانت قاعدة البيانات لن تستخدم الفهرس لتصفية المستخدمين النشطين ، فلماذا نقوم بفهرستها في المقام الأول؟
قبل الإجابة على هذا السؤال ، دعونا نلقي نظرة على وزن الفهرس الكامل حسب العمود
activated:
db=# \di+ users_activated_ix
Schema | Name | Type | Owner | Table | Size
--------+--------------------+-------+-------+-------+------
public | users_activated_ix | index | haki | users | 21 MB
يزن المؤشر 21 ميغا بايت. للإشارة فقط: الجدول مع المستخدمين 65 ميغا بايت. أي أن وزن المؤشر ~ 32٪ من الوزن الأساسي. ومع ذلك ، نعلم أنه من غير المحتمل استخدام 90٪ من محتوى الفهرس.
في PostgreSQL ، يمكنك إنشاء فهرس على جزء فقط من الجدول - ما يسمى بالفهرس الجزئي :
db=# CREATE INDEX users_unactivated_partial_ix ON users(id)
db-# WHERE not activated;
CREATE INDEX
نستخدم تعبيرًا
WHEREلتقييد السلاسل التي يغطيها الفهرس. دعنا نتحقق مما إذا كان يعمل:
db=# EXPLAIN SELECT * FROM users WHERE not activated;
QUERY PLAN
------------------------------------------------------------------------------------------------
Index Scan using users_unactivated_partial_ix on users (cost=0.29..3493.60 rows=102567 width=38)
رائع ، تبين أن قاعدة البيانات ذكية بما يكفي لإدراك أن التعبير المنطقي الذي استخدمناه في استعلامنا قد يعمل لفهرس جزئي.
هذا النهج له ميزة أخرى:
db=# \di+ users_unactivated_partial_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+------------------------------+-------+-------+-------+---------
public | users_unactivated_partial_ix | index | haki | users | 2216 kB
يزن فهرس العمود الكامل 21 ميغا بايت ، والفهرس الجزئي 2.2 ميغا بايت فقط. هذا هو 10٪ ، وهو ما يتوافق مع نسبة المستخدمين غير النشطين في الجدول.
دائما تحميل البيانات المصنفة
هذا أحد تعليقاتي الأكثر شيوعًا عند تحليل الكود. النصيحة ليست بديهية مثل الآخرين ويمكن أن يكون لها تأثير كبير على الإنتاجية.
لنفترض أن لديك طاولة ضخمة بمبيعات محددة:
db=# CREATE TABLE sale_fact (id serial, username text, sold_at date);
CREATE TABLE
كل ليلة أثناء عملية ETL ، تقوم بتحميل البيانات في جدول:
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000);
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
لمحاكاة التنزيل ، نستخدم بيانات عشوائية. أدخلنا 100 ألف سطر بأسماء عشوائية ، وتواريخ البيع للفترة من 1 يناير 2020 والسنتين التاليتين.
بالنسبة للجزء الأكبر ، يتم استخدام الجدول لتقارير المبيعات الموجزة. في أغلب الأحيان ، يقومون بالتصفية حسب التاريخ لمعرفة المبيعات لفترة محددة. لتسريع فحص النطاق ، دعنا ننشئ فهرسًا عن طريق
sold_at:
db=# CREATE INDEX sale_fact_sold_at_ix ON sale_fact(sold_at);
CREATE INDEX
دعنا نلقي نظرة على خطة التنفيذ لطلب جلب جميع المبيعات في يونيو 2020:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
-----------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=108.30..1107.69 rows=4293 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Heap Blocks: exact=927
-> Bitmap Index Scan on sale_fact_sold_at_ix (cost=0.00..107.22 rows=4293 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.191 ms
Execution Time: 5.906 ms
بعد تشغيل الطلب عدة مرات لتسخين ذاكرة التخزين المؤقت ، استقر وقت التنفيذ عند مستوى 6 مللي ثانية.
مسح نقطي
من حيث التنفيذ ، نرى أن الأساس يستخدم مسح الصور النقطية. يتم على مرحلتين:
(Bitmap Index Scan): تمر القاعدة عبر الفهرس بالكاملsale_fact_sold_at_ixوتبحث عن جميع الصفحات الموجودة في الجدول التي تحتوي على الصفوف ذات الصلة.(Bitmap Heap Scan): تقرأ القاعدة الصفحات التي تحتوي على السلاسل ذات الصلة وتجد تلك التي تفي بالشرط.
يمكن أن تحتوي الصفحات على العديد من الأسطر. في الخطوة الأولى ، يتم استخدام الفهرس للعثور على الصفحات . تبحث المرحلة الثانية عن الأسطر في الصفحات ، ومن ثم تتبع العملية
Recheck Condفي خطة التنفيذ.
في هذه المرحلة ، سيقوم العديد من مسؤولي قواعد البيانات والمطورين بالتقريب والانتقال إلى الاستعلام التالي. ولكن هناك طريقة لتحسين هذا الاستعلام.
مسح الفهرس
لنقم بتغيير بسيط في تحميل البيانات.
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
db-# ORDER BY sold_at;
INSERT 0 100000
db=# VACUUM ANALYZE sale_fact;
VACUUM
هذه المرة قمنا بتحميل البيانات مرتبة حسب
sold_at.
الآن تبدو خطة التنفيذ لنفس الاستعلام كما يلي:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.29..184.73 rows=4272 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Planning Time: 0.145 ms
Execution Time: 2.294 ms
بعد عدة دورات ، استقر وقت التنفيذ عند 2.3 مللي ثانية. لقد حققنا وفورات مستدامة بلغت حوالي 60٪.
نرى أيضًا أن قاعدة البيانات هذه المرة لم تستخدم مسح الصور النقطية ، ولكنها طبقت فحص فهرس "عادي". لماذا ا؟
علاقه مترابطه
عندما تحلل قاعدة البيانات الجدول ، فإنها تجمع كل الإحصائيات التي يمكنها الحصول عليها. أحد المعلمات هو الارتباط :
الارتباط الإحصائي بين الترتيب المادي للصفوف والترتيب المنطقي للقيم في الأعمدة. إذا كانت القيمة حول -1 أو +1 ، فإن فحص الفهرس على العمود يعتبر أكثر فائدة مما لو كانت قيمة الارتباط حوالي 0 ، حيث يتم تقليل عدد مرات الوصول العشوائي إلى القرص.
كما هو موضح في الوثائق الرسمية ، الارتباط هو مقياس لكيفية "فرز" القيم الموجودة في عمود معين على القرص.
الارتباط = 1.
إذا كان الارتباط 1 أو نحو ذلك ، فهذا يعني أن الصفحات مخزنة على القرص بنفس ترتيب الصفوف الموجودة في الجدول تقريبًا. هذا شائع جدا. على سبيل المثال ، تميل المعرفات المتزايدة تلقائيًا إلى أن يكون لها ارتباط قريب من 1. أعمدة التاريخ والطوابع الزمنية التي تظهر وقت إنشاء الصفوف لها أيضًا ارتباط قريب من 1.
إذا كان الارتباط هو -1 ، يتم فرز الصفحات بترتيب عكسي للأعمدة.
الارتباط ~ 0.
إذا كان الارتباط قريبًا من 0 ، فهذا يعني أن القيم الموجودة في العمود لا ترتبط أو لا ترتبط بترتيب الصفحات في الجدول.
دعنا نعود إلى
sale_fact. عندما قمنا بتحميل البيانات في الجدول دون فرز مسبق ، كانت الارتباطات كما يلي:
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db=# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale | id | 1
sale | username | -0.005344716
sale | sold_at | -0.011389783
معرّف العمود الذي تم إنشاؤه تلقائيًا له ارتباط بـ 1. يحتوي العمود على
sold_atارتباط منخفض جدًا: القيم المتتالية مبعثرة في جميع أنحاء الجدول.
عندما قمنا بتحميل البيانات التي تم فرزها في الجدول ، قامت بحساب الارتباطات:
tablename | attname | correlation
-----------+----------+----------------
sale_fact | id | 1
sale_fact | username | -0.00041992788
sale_fact | sold_at | 1
العلاقة الآن
sold_atمتساوية 1.
فلماذا استخدم الأساس لمسح الصور النقطية عندما كان الارتباط منخفضًا ، ولكن تم مسح الفهرس عندما كان الارتباط مرتفعًا؟
- عندما كان الارتباط 1 ، حددت القاعدة أن صفوف النطاق المطلوب من المحتمل أن تكون في صفحات متتالية. ثم من الأفضل استخدام مسح فهرس لقراءة صفحات متعددة.
- عندما كان الارتباط قريبًا من 0 ، حددت القاعدة أن صفوف النطاق المطلوب من المحتمل أن تكون مبعثرة في جميع أنحاء الجدول. ومن ثم يُنصح باستخدام المسح الضوئي للصور النقطية لتلك الصفحات التي تحتوي على الأسطر المطلوبة ، وبعد ذلك فقط يتم استخراجها باستخدام الشرط.
في المرة التالية التي تقوم فيها بتحميل البيانات إلى جدول ، فكر في مقدار المعلومات التي سيتم طلبها وفرزها بحيث يمكن للفهارس مسح النطاقات بسرعة.
أمر CLUSTER
هناك طريقة أخرى "لفرز جدول على القرص" بواسطة فهرس معين وهي استخدام الأمر CLUSTER .
على سبيل المثال:
db=# TRUNCATE sale_fact;
TRUNCATE TABLE
-- Insert rows without sorting
db=# INSERT INTO sale_fact (username, sold_at)
db-# SELECT
db-# md5(random()::text) AS username,
db-# '2020-01-01'::date + (interval '1 day') * round(random() * 365 * 2) AS sold_at
db-# FROM
db-# generate_series(1, 100000)
INSERT 0 100000
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+-----------+----------------
sale_fact | sold_at | -5.9702674e-05
sale_fact | id | 1
sale_fact | username | 0.010033822
قمنا بتحميل البيانات في الجدول بترتيب عشوائي ، لذا فإن الارتباط
sold_atقريب من الصفر.
لإعادة تكوين الجدول
sold_at، نستخدم الأمر CLUSTERلفرز الجدول على القرص وفقًا للفهرس sale_fact_sold_at_ix:
db=# CLUSTER sale_fact USING sale_fact_sold_at_ix;
CLUSTER
db=# ANALYZE sale_fact;
ANALYZE
db=# SELECT tablename, attname, correlation
db-# FROM pg_stats
db-# WHERE tablename = 'sale_fact';
tablename | attname | correlation
-----------+----------+--------------
sale_fact | sold_at | 1
sale_fact | id | -0.002239401
sale_fact | username | 0.013389298
بعد تجميع الجدول ،
sold_atأصبح الارتباط 1.
أمر CLUSTER.
النقاط التي يجب ملاحظتها:
- يمكن أن يؤثر تجميع جدول في عمود معين على ارتباط عمود آخر. على سبيل المثال ، ألق نظرة على ارتباط المعرف بعد التجميع حسب
sold_at. CLUSTERهي عملية ثقيلة ومعيقة ، لذلك لا تطبقها على طاولة حية.
لهذه الأسباب ، من الأفضل إدخال البيانات التي تم فرزها بالفعل وعدم الاعتماد عليها
CLUSTER.
فهرس الأعمدة شديد الارتباط بـ BRIN
عندما يتعلق الأمر بالفهارس ، يفكر العديد من المطورين في أشجار B. لكن PostgreSQL تقدم أنواعًا أخرى من الفهارس ، مثل BRIN :
تم تصميم BRIN للعمل مع جداول كبيرة جدًا حيث ترتبط بعض الأعمدة بشكل طبيعي بموقعها الفعلي داخل الجدول
BRIN هي اختصار لـ Block Range Index. وفقًا للوثائق ، تعمل BRIN بشكل أفضل مع الأعمدة شديدة الارتباط. كما رأينا في الفصول السابقة ، فإن المعرفات المتزايدة تلقائيًا والطوابع الزمنية ترتبط بشكل طبيعي بالبنية المادية للجدول ، لذا فإن BRIN أكثر فائدة لهم.
في ظل ظروف معينة ، يمكن أن توفر BRIN "قيمة أفضل مقابل المال" من حيث الحجم والأداء مقارنة بمؤشر B-Tree القابل للمقارنة.
برين.
BRIN هو نطاق من القيم في عدة صفحات متجاورة في جدول. لنفترض أن لدينا القيم التالية في عمود ، كل منها في صفحة منفصلة:
1, 2, 3, 4, 5, 6, 7, 8, 9
تعمل BRIN مع نطاقات من الصفحات المجاورة. إذا قمت بتحديد ثلاث صفحات متجاورة ، فإن الفهرس يقسم الجدول إلى نطاقات:
[1,2,3], [4,5,6], [7,8,9]
لكل نطاق ، تقوم BRIN بتخزين الحد الأدنى والحد الأقصى للقيمة :
[1–3], [4–6], [7–9]
دعنا نستخدم هذا الفهرس للبحث عن القيمة 5:
- [1-3] - بالتأكيد ليس هنا.
- [4-6] - ربما هنا.
- [7-9] - بالتأكيد ليس هنا.
مع BRIN ، قمنا بتحديد منطقة البحث لتقتصر على 4-6.
لنأخذ مثالاً آخر. السماح القيم في عمود لها علاقة وثيقة إلى الصفر، وهذا هو، هم لا فرز:
[2,9,5], [1,4,7], [3,8,6]
ستوفر لنا فهرسة ثلاث كتل متجاورة النطاقات التالية:
[2–9], [1–7], [3–8]
لنبحث عن القيمة 5:
- [2-9] - قد يكون هنا.
- [1-7] - قد يكون هنا.
- [3-8] - قد يكون هنا.
في هذه الحالة ، لا يضيق الفهرس البحث على الإطلاق ، لذا فهو عديم الفائدة.
فهم pages_per_range
يتم تحديد عدد الصفحات المجاورة بواسطة المعلمة
pages_per_range. يؤثر عدد الصفحات في النطاق على حجم ودقة BRIN:
pages_per_rangeيعطي المؤشر الأصغر والأقل دقة قيمة كبيرة .pages_per_rangeستعطي القيمة الصغيرة فهرسًا أكبر وأكثر دقة.
الافتراضي
pages_per_rangeهو 128.
BRIN مع عدد صفحات_كل_نطاق أقل.
للتوضيح ، دعنا ننشئ BRIN بنطاقات من صفحتين ونبحث عن القيمة 5:
- [1-2] - بالتأكيد ليس هنا.
- [3-4] - بالتأكيد ليس هنا.
- [5-6] - قد يكون هنا.
- [7-8] - بالتأكيد ليس هنا.
- [9] - هنا بالتأكيد ليس كذلك.
باستخدام نطاق من صفحتين ، يمكننا قصر البحث على المربعين 5 و 6. إذا كان النطاق مكونًا من ثلاث صفحات ، فسيحصر الفهرس البحث في المربعات 4 و 5 و 6.
وهناك اختلاف آخر بين المؤشرين وهو أنه عندما يكون النطاق ثلاث صفحات ، نحتاج إلى تخزين ثلاثة نطاقات ، ومع وجود صفحتين في النطاق ، نحصل بالفعل على خمسة نطاقات ويزداد الفهرس.
قم بإنشاء BRIN
لنأخذ جدولًا
sales_factوننشئ BRIN حسب العمود sold_at:
db=# CREATE INDEX sale_fact_sold_at_bix ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 128);
CREATE INDEX
الافتراضي هو
pages_per_range = 128.
الآن دعنا نستعلم عن فترة تاريخ المبيعات:
db=# EXPLAIN (ANALYZE)
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.11..1135.61 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 23130
Heap Blocks: lossy=256
-> Bitmap Index Scan on sale_fact_sold_at_bix (cost=0.00..12.03 rows=12500 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 8.877 ms
حصلت القاعدة على فترة التاريخ باستخدام BRIN ، لكن هذا ليس شيئًا مثيرًا للاهتمام ...
تحسين عدد الصفحات في النطاق
وفقًا لخطة التنفيذ ، أزالت قاعدة البيانات 23130 صفًا من الصفحات ، ووجدتها باستخدام الفهرس. قد يشير هذا إلى أن النطاق الذي حددناه للفهرس كبير جدًا لهذا الاستعلام. لنقم بإنشاء فهرس بنصف عدد الصفحات في النطاق:
db=# CREATE INDEX sale_fact_sold_at_bix64 ON sale_fact
db-# USING BRIN(sold_at) WITH (pages_per_range = 64);
CREATE INDEX
db=# EXPLAIN (ANALYZE)
db- SELECT *
db- FROM sale_fact
db- WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------------------
Bitmap Heap Scan on sale_fact (cost=13.10..1048.10 rows=4319 width=41)
Recheck Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Rows Removed by Index Recheck: 9434
Heap Blocks: lossy=128
-> Bitmap Index Scan on sale_fact_sold_at_bix64 (cost=0.00..12.02 rows=6667 width=0)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
Execution Time: 5.491 ms
مع وجود 64 صفحة في النطاق ، حذفت القاعدة عددًا أقل من الصفوف التي تم العثور عليها باستخدام الفهرس - 9 434. هذا يعني أنه كان عليها القيام بعمليات إدخال / إخراج أقل ، وتم تنفيذ الاستعلام بشكل أسرع قليلاً ، في حوالي 5.5 مللي ثانية بدلاً من ~ 8.9.
دعنا نختبر الفهرس بقيم مختلفة
pages_per_range:
| عدد الصفحات في النطاق | تمت إزالة الصفوف عند إعادة فحص الفهرس |
| 128 | 23130 |
| 64 | 9434 |
| 8 | 874 |
| 4 | 446 |
| 2 | 446 |
pages_per_rangeيصبح
إنقاص الفهرس أكثر دقة ، ويزيل عددًا أقل من الصفوف من الصفحات التي يعثر عليها.
يرجى ملاحظة أننا قمنا بتحسين استعلام محدد للغاية. هذا جيد للتوضيح ، ولكن في الحياة الواقعية من الأفضل استخدام القيم التي تلبي احتياجات معظم الاستفسارات.
تقدير حجم المؤشر
الميزة الرئيسية الأخرى لـ BRIN هي حجمها. في الفصول السابقة ، قمنا
sold_atبإنشاء فهرس B-tree للحقل . كان حجمه 2224 كيلو بايت. وحجم BRIN مع المعلمة هو pages_per_range=12848 كيلو بايت فقط: 46 مرة أصغر.
Schema | Name | Type | Owner | Table | Size
--------+-----------------------+-------+-------+-----------+-------
public | sale_fact_sold_at_bix | index | haki | sale_fact | 48 kB
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
يتأثر حجم BRIN أيضًا
pages_per_range. على سبيل المثال ، pages_per_range=2تزن BRINs 56 كيلو بايت ، أي أكثر بقليل من 48 كيلو بايت.
جعل الفهارس "غير مرئية"
تتمتع PostgreSQL بميزة DDL الرائعة للمعاملات . على مر السنين مع Oracle ، اعتدت على استخدام أوامر DDL مثل
CREATE، DROPوفي نهاية المعاملات ALTER. ولكن في PostgreSQL ، يمكنك تنفيذ أوامر DDL داخل المعاملة ، ولن يتم تطبيق التغييرات إلا بعد تنفيذ المعاملة. اكتشفت
مؤخرًا أن استخدام DDL للمعاملات يمكن أن يجعل الفهارس غير مرئية! هذا مفيد عندما تريد رؤية خطة تنفيذ بدون فهارس. على سبيل المثال ، في الجدول أنشأنا فهرسًا في عمود . تبدو خطة تنفيذ طلب جلب المبيعات لشهر يوليو كما يلي:
sale_factsold_at
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using sale_fact_sold_at_ix on sale_fact (cost=0.42..182.80 rows=4319 width=41)
Index Cond: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))P
لمعرفة الشكل الذي ستبدو عليه الخطة في حالة عدم وجود مؤشر
sale_fact_sold_at_ix، يمكنك وضع المؤشر داخل معاملة والتراجع فورًا:
db=# BEGIN;
BEGIN
db=# DROP INDEX sale_fact_sold_at_ix;
DROP INDEX
db=# EXPLAIN
db-# SELECT *
db-# FROM sale_fact
db-# WHERE sold_at BETWEEN '2020-07-01' AND '2020-07-31';
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on sale_fact (cost=0.00..2435.00 rows=4319 width=41)
Filter: ((sold_at >= '2020-07-01'::date) AND (sold_at <= '2020-07-31'::date))
db=# ROLLBACK;
ROLLBACK
أولاً ، لنبدأ معاملة مع
BEGIN. ثم نقوم بإسقاط الفهرس وإنشاء خطة التنفيذ. لاحظ أن الخطة تستخدم الآن فحص جدول كامل كما لو أن الفهرس غير موجود. في هذه المرحلة ، لا تزال الصفقة جارية ، لذلك لم يتم إسقاط المؤشر بعد. لإكمال المعاملة دون إسقاط الفهرس ، قم باسترجاعها باستخدام الأمر ROLLBACK.
دعنا نتحقق من أن الفهرس لا يزال موجودًا:
db=# \di+ sale_fact_sold_at_ix
List of relations
Schema | Name | Type | Owner | Table | Size
--------+----------------------+-------+-------+-----------+---------
public | sale_fact_sold_at_ix | index | haki | sale_fact | 2224 kB
قواعد البيانات الأخرى التي لا تدعم DDL للمعاملات قد تحقق الهدف بشكل مختلف. على سبيل المثال ، تسمح لك Oracle بوضع علامة على فهرس على أنه غير مرئي وسيقوم المحسن بعد ذلك بتجاهله.
تحذير : إذا كنت لإسقاط الفهرس داخل معاملة، فإنه سيؤدي إلى عرقلة عمليات تنافسية
SELECT، INSERT، UPDATEو DELETEفي الجدول حتى المعاملة نشطة. استخدم بحذر في بيئات الاختبار وتجنب استخدامها في منشآت الإنتاج.
لا تقم بجدولة عمليات طويلة لتبدأ في بداية أي ساعة
يعرف المستثمرون أن أشياء غريبة يمكن أن تحدث عندما يصل سعر السهم إلى قيم دائرية جميلة ، على سبيل المثال ، 10 دولارات ، 100 دولار ، 1000 دولار. هذا ما كتبوه عنها :
[...] يمكن أن يتغير سعر الأصل بشكل غير متوقع ، متجاوزًا القيم المستديرة مثل 50 دولارًا أو 100 دولار للسهم. يحب العديد من المتداولين عديمي الخبرة شراء الأصول أو بيعها عندما يصل السعر إلى الأرقام التقريبية لأنهم يعتقدون أنها أسعار عادلة.
من وجهة النظر هذه ، لا يختلف المطورون كثيرًا عن المستثمرين. عندما يحتاجون إلى جدولة عملية طويلة ، فإنهم عادةً ما يختارون ساعة.
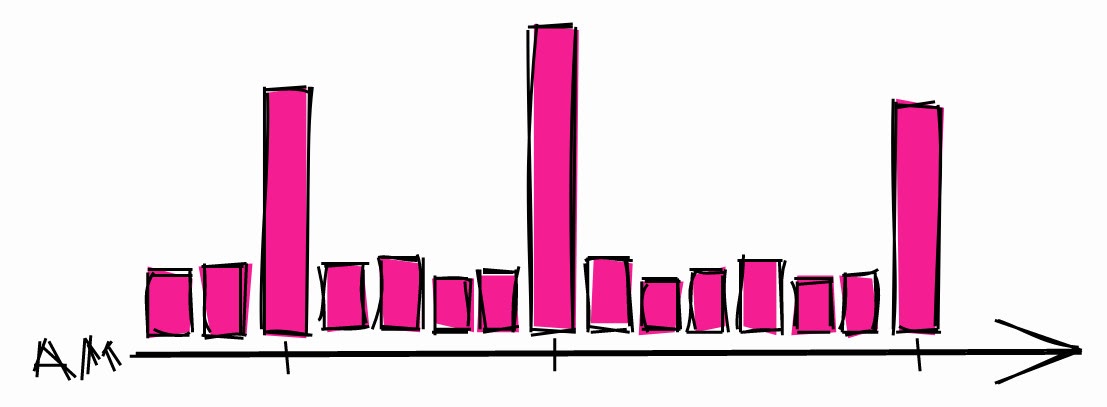
الحمل النموذجي للنظام الليلي.
يمكن أن يؤدي هذا إلى زيادة التحميل خلال هذه الساعات. لذلك إذا كنت بحاجة إلى جدولة عملية طويلة ، فهناك فرصة أكبر لأن يصبح النظام خاملاً في أوقات أخرى.
يوصى أيضًا باستخدام التأخيرات العشوائية في الجداول حتى لا تبدأ في نفس الوقت كل مرة. ثم حتى إذا تمت جدولة مهمة أخرى لهذه الساعة ، فلن تكون مشكلة كبيرة. إذا كنت تستخدم مؤقت systemd ، فيمكنك استخدام خيار RandomizedDelaySec .
خاتمة
تقدم هذه المقالة نصائح بدرجات متفاوتة من الأدلة بناءً على تجربتي. بعضها سهل التنفيذ ، والبعض الآخر يتطلب فهمًا عميقًا لكيفية عمل قواعد البيانات. قواعد البيانات هي العمود الفقري لمعظم الأنظمة الحديثة ، لذا فإن الوقت المستغرق في تعلم كيفية العمل يعد استثمارًا جيدًا لأي مطور!