
تجمع هذه المقالة بعض الأنماط الشائعة لمساعدة المهندسين على العمل مع الخدمات واسعة النطاق التي يطلبها ملايين المستخدمين.
في تجربة المؤلف ، هذه ليست قائمة شاملة ، ولكنهانصائح فعالة حقًا. لذا ، لنبدأ.
ترجمت بدعم من Mail.ru Cloud Solutions .
مستوى اول
التدابير المدرجة أدناه سهلة التنفيذ نسبيًا ، ولكنها تحقق عوائد عالية. إذا لم تكن قد جربتها من قبل ، فسوف تفاجأ بالتحسينات المهمة.
البنية التحتية كرمز
النصيحة الأولى هي تنفيذ البنية التحتية كرمز. هذا يعني أنه يجب أن يكون لديك طريقة برمجية لنشر البنية الأساسية بالكامل. يبدو الأمر صعبًا ، لكننا في الواقع نتحدث عن الكود التالي:
انشر 100 جهاز افتراضي
- مع أوبونتو
- 2 جيجا رام لكل منهما
- سيكون لديهم الكود التالي
- مع هذه المعلمات
يمكنك تتبع تغييرات البنية الأساسية والعودة إليها بسرعة باستخدام التحكم في المصدر.
يقول الحداثي بداخلي أنه يمكنك استخدام Kubernetes / Docker للقيام بكل ما سبق ، وهو على حق.
يمكنك أيضًا توفير الأتمتة باستخدام Chef أو Puppet أو Terraform.
التكامل والتسليم المستمر
لإنشاء خدمة قابلة للتطوير ، من المهم أن يكون لديك خط أنابيب بناء واختبار لكل طلب سحب. حتى لو كان الاختبار هو الأبسط ، فإنه سيضمن على الأقل أن الكود الذي تنشره يجمع.
في كل مرة في هذه المرحلة ، تجيب على السؤال: هل سيقوم التجميع الخاص بي بترجمة الاختبارات واجتيازها ، هل هذا صحيح؟ قد يبدو هذا وكأنه شريط منخفض ، لكنه يحل الكثير من المشاكل.
لا يوجد شيء أجمل من رؤية مربعات الاختيار هذه.
بالنسبة لهذه التقنية ، يمكنك التحقق من Github أو CircleCI أو Jenkins.
موازين التحميل
لذلك ، نريد أن نبدأ موازن التحميل لإعادة توجيه حركة المرور ، والتأكد من تساوي الحمل على جميع العقد أو أن الخدمة تعمل في حالة حدوث فشل:
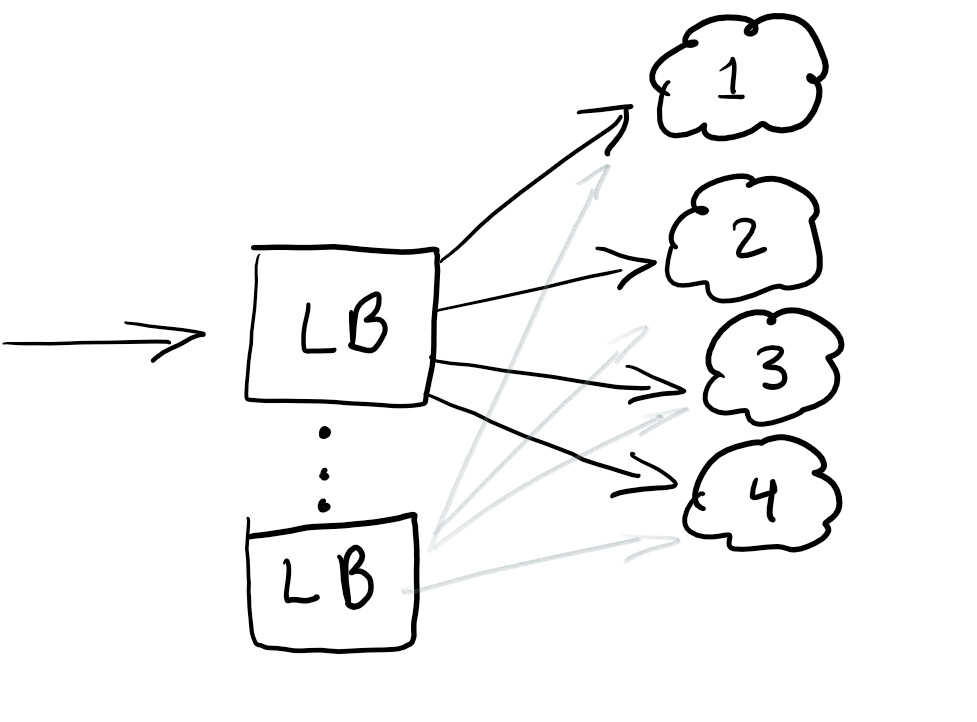
موازن التحميل جيد بشكل عام في المساعدة على توزيع حركة المرور. أفضل ممارسة هي زيادة التوازن بحيث لا يكون لديك نقطة واحدة للفشل.
عادةً ما يتم تكوين أرصدة التحميل في السحابة التي تستخدمها.
RayID أو معرف الارتباط أو UUID للطلبات
هل سبق لك أن واجهت خطأً في تطبيق برسالة مثل هذه: "حدث خطأ ما. احفظ هذا المعرف وأرسله إلى فريق الدعم لدينا " ؟
المعرف الفريد أو معرف الارتباط أو RayID أو أي من المتغيرات ، هو معرف فريد يسمح لك بتتبع الطلب طوال دورة حياته. يتيح لك هذا تتبع مسار الطلب بالكامل في السجلات.
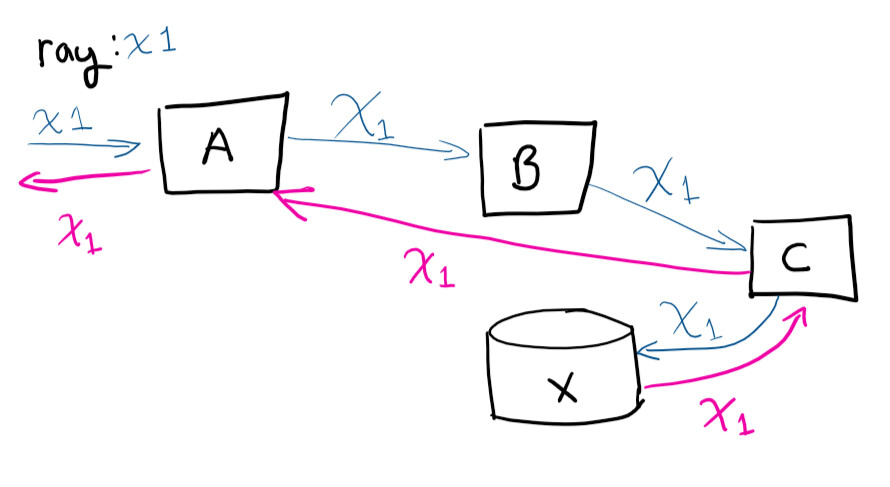
يقوم المستخدم بتقديم طلب إلى النظام A ، ثم A جهات الاتصال B ، تلك جهات الاتصال C ، تحفظ في X ثم يعود الطلب إلى A
إذا كنت تريد الاتصال عن بعد بالأجهزة الافتراضية ومحاولة تتبع مسار الطلب (وربط يدويًا المكالمات التي تحدث) ، سوف تصاب بالجنون. وجود معرف فريد يجعل الحياة أسهل بكثير. يعد هذا أحد أسهل الأشياء التي يمكنك القيام بها لتوفير الوقت مع نمو خدمتك.
مستوى متوسط
النصيحة هنا أكثر تعقيدًا من سابقتها ، لكن الأدوات المناسبة تجعل المهمة أسهل ، وتوفر عائدًا على الاستثمار حتى للشركات الصغيرة والمتوسطة الحجم.
التسجيل المركزي
تهانينا! لقد قمت بنشر 100 جهاز افتراضي. في اليوم التالي ، يأتي الرئيس التنفيذي ويشكو من خطأ تلقاه أثناء اختبار الخدمة. يُبلغ عن المعرف المقابل الذي تحدثنا عنه أعلاه ، ولكن سيتعين عليك البحث في سجلات 100 جهاز للعثور على المعرف الذي تسبب في التعطل. ويجب أن يتم العثور عليها قبل عرض الغد.
بينما تبدو هذه مغامرة ممتعة ، فمن الأفضل التأكد من أن لديك القدرة على البحث في جميع المجلات من مكان واحد. لقد قمت بحل مشكلة مركزية السجلات من خلال الوظائف المضمنة في ELK stack: يتم دعم مجموعة السجلات القابلة للبحث هنا. سيساعد هذا حقًا في حل مشكلة العثور على سجل معين. على سبيل المكافأة ، يمكنك إنشاء مخططات وأشياء ممتعة أخرى من هذا القبيل.
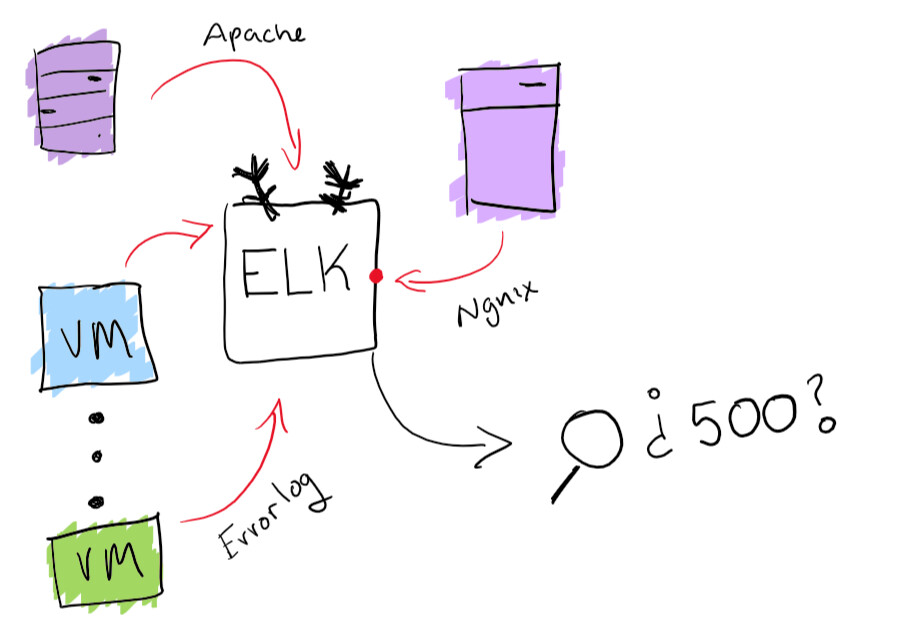
وظيفة ELK المكدس
وكلاء المراقبة
الآن بعد أن أصبحت خدمتك قيد التشغيل ، تحتاج إلى التأكد من أنها تعمل بسلاسة. أفضل طريقة للقيام بذلك هي تشغيل عوامل متعددة تعمل بالتوازي والتحقق من أنها تعمل ويتم تنفيذ العمليات الأساسية.
في هذه المرحلة ، تتحقق من أن التجميع قيد التشغيل يعمل بشكل جيد ويعمل بشكل جيد .
بالنسبة للمشاريع الصغيرة والمتوسطة ، أوصي باستخدام Postman لرصد وتوثيق واجهات برمجة التطبيقات. ولكن بشكل عام ، ما عليك سوى التأكد من أن لديك طريقة لمعرفة وقت حدوث الفشل وتلقي التنبيهات في الوقت المناسب.
قياس تلقائي على أساس الحمل
انها بسيطة جدا. إذا كان لديك جهاز افتراضي يقدم الطلبات ويقترب من 80٪ من استخدام الذاكرة ، فيمكنك إما زيادة موارده أو إضافة المزيد من الأجهزة الظاهرية إلى المجموعة. يعد التنفيذ التلقائي لهذه العمليات ممتازًا لتغييرات الطاقة المرنة تحت الحمل. ولكن يجب أن تكون حريصًا دائمًا بشأن مقدار الأموال التي تنفقها وتضع حدودًا معقولة.
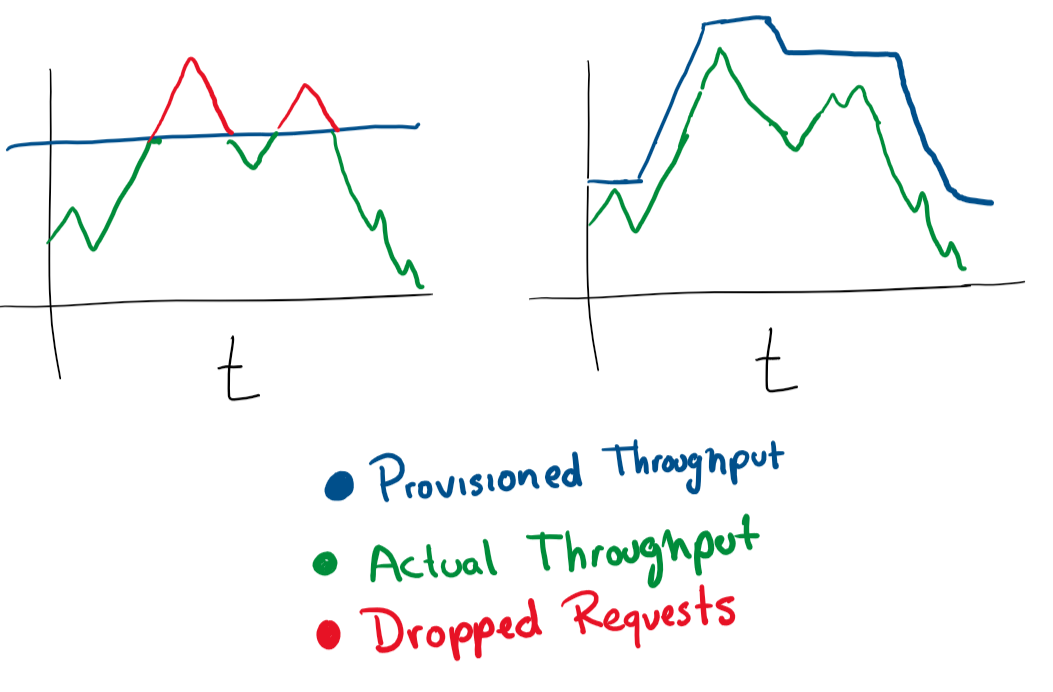
في معظم الخدمات السحابية ، يمكنك تكوين التحجيم التلقائي باستخدام المزيد من الخوادم أو الخوادم الأكثر قوة.
نظام التجربة
من الطرق الجيدة لنشر التحديثات بأمان أن تكون قادرًا على اختبار شيء ما لـ 1٪ من المستخدمين في غضون ساعة. لقد رأيت بالتأكيد مثل هذه الآليات قيد التنفيذ. على سبيل المثال ، يعرض Facebook أجزاء من الجمهور بلون مختلف أو يغير حجم الخط لمعرفة كيف يدرك المستخدمون التغيير. وهذا ما يسمى باختبار أ / ب.
حتى إصدار ميزة جديدة يمكن تشغيلها كتجربة ثم معرفة كيفية إصدارها. يمكنك أيضًا الحصول على القدرة على "تذكر" أو تغيير التكوين أثناء التنقل ، مع مراعاة الوظيفة التي تسبب تدهور الخدمة الخاصة بك.
مستوى متقدم
فيما يلي بعض النصائح التي يصعب تنفيذها. ربما ستحتاج إلى المزيد من الموارد ، لذلك سيكون من الصعب على شركة صغيرة إلى متوسطة الحجم التعامل مع هذا الأمر.
عمليات النشر الأزرق والأخضر
هذا ما أسميه طريقة نشر "إرلانج". تم استخدام Erlang على نطاق واسع عندما ظهرت شركات الهاتف. تم استخدام مفاتيح لينة لتوجيه المكالمات الهاتفية. كان التركيز الرئيسي للبرنامج على هذه المفاتيح هو عدم إسقاط المكالمات أثناء ترقيات النظام. لدى Erlang طريقة رائعة لتحميل وحدة جديدة دون تعطل الوحدة السابقة.
تعتمد هذه الخطوة على وجود موازن تحميل. لنفترض أن لديك الإصدار N من برنامجك ثم تريد نشر الإصدار N + 1.
هل يمكن أن مجرد إيقاف خدمة ونشر النسخة المقبلة في الوقت الذي هو مناسب للمستخدمين والحصول على بعض الوقت الضائع. لكن افترض أن لديكحقا حيث SLA صارمة. لذلك ، تعني اتفاقية مستوى الخدمة (SLA) بنسبة 99،99٪ أنه يمكنك عدم الاتصال بالإنترنت لمدة 52 دقيقة فقط في السنة.
إذا كنت تريد حقًا تحقيق ذلك ، فأنت بحاجة إلى عمليتي نشر في نفس الوقت:
- الشخص الموجود الآن (N) ؛
- الإصدار التالي (N + 1).
أنت تطلب من موازن التحميل إعادة توجيه نسبة مئوية من حركة المرور الخاصة بك إلى الإصدار الجديد (N + 1) أثناء تتبع الانحدارات بنفسك بنشاط.
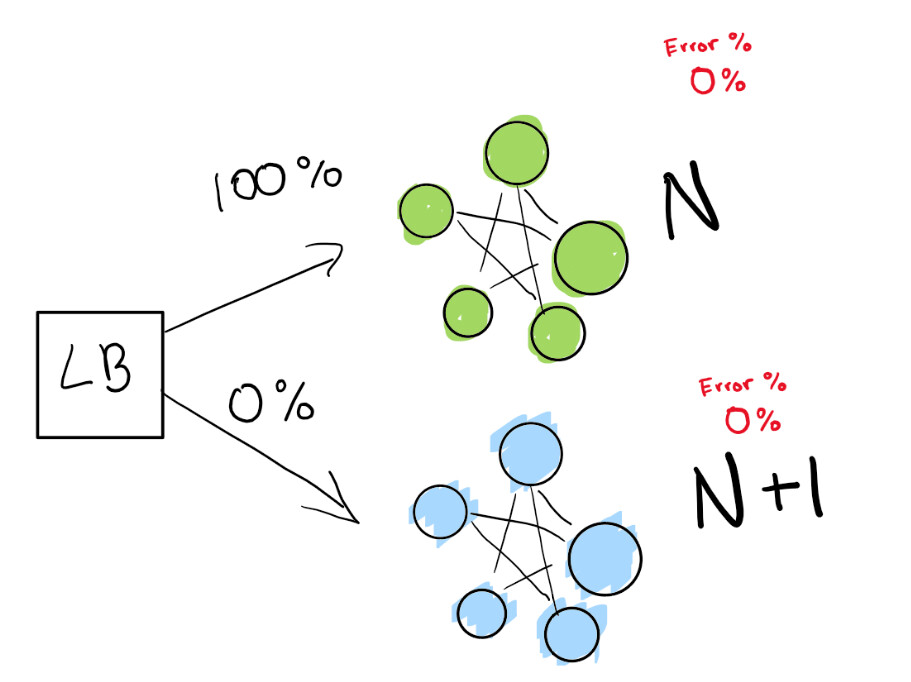
هنا لدينا نشر أخضر N يعمل بشكل جيد. نحاول الانتقال إلى الإصدار التالي من هذا النشر
أولاً ، نرسل اختبارًا صغيرًا حقًا لمعرفة ما إذا كان نشر N + 1 يعمل مع حركة مرور قليلة:
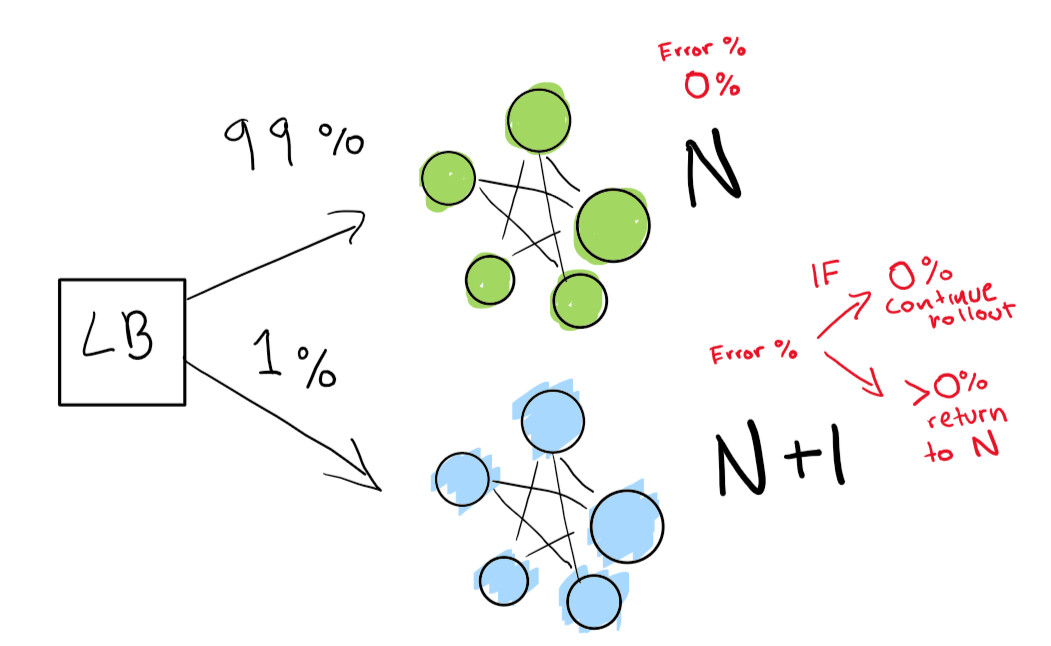
أخيرًا ، لدينا مجموعة من الفحوصات الآلية التي ينتهي بنا الأمر بالعمل حتى اكتمال النشر. إذا كنت شديد الحذر ، يمكنك أيضًا الاحتفاظ بنشر N الخاص بك إلى الأبد من أجل التراجع السريع في حالة الانحدار السيئ:
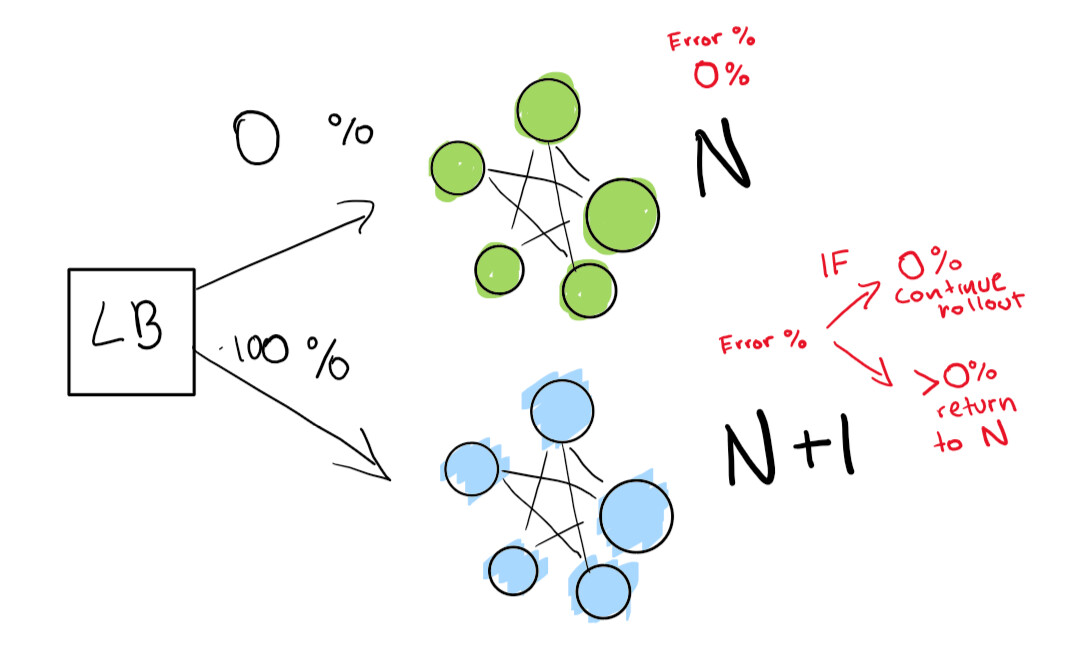
إذا كنت ترغب في الانتقال إلى مستوى أكثر تقدمًا ، فدع كل شيء في النشر الأزرق والأخضر يتم تلقائيًا.
كشف الشذوذ والتخفيف التلقائي
نظرًا لأن لديك تسجيلًا مركزيًا وتجميعًا جيدًا للسجلات ، يمكنك بالفعل تحديد أهداف أعلى. على سبيل المثال ، توقع الفشل بشكل استباقي. على الشاشات والسجلات ، يتم تتبع الوظائف وإنشاء مخططات مختلفة - ويمكنك التنبؤ مسبقًا بما سيحدث:
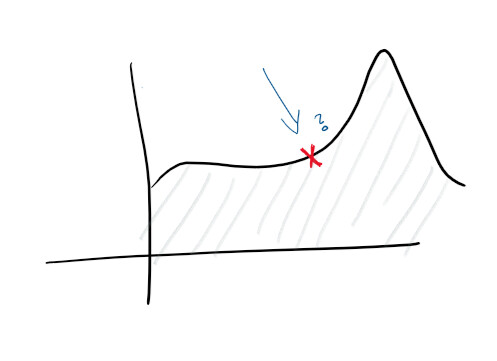
مع اكتشاف الحالات الشاذة ، تبدأ في دراسة بعض القرائن التي تشير إلى مشكلات الخدمة. على سبيل المثال ، قد يشير الارتفاع الكبير في استخدام وحدة المعالجة المركزية إلى فشل محرك الأقراص الثابتة ، في حين أن ارتفاع الطلبات يعني أنك بحاجة إلى التوسع. يتيح لنا هذا النوع من الإحصائيات جعل الخدمة استباقية.
باستخدام هذه الرؤية ، يمكنك التوسع في أي بُعد ، وتغيير خصائص الأجهزة وقواعد البيانات والوصلات والموارد الأخرى بشكل استباقي وتفاعلي.
هذا كل شئ!
ستوفر لك قائمة الأولويات هذه الكثير من المتاعب إذا كنت تطرح خدمة سحابية.
يدعو مؤلف المقال الأصلي القراء إلى ترك تعليقاتهم وإجراء التغييرات. يتم توزيع المقال كمصدر مفتوح ، ويقبل المؤلف طلبات السحب على Github .
ماذا تقرأ عن الموضوع: