إذا كنت تصمم تطبيقات أو قواعد بيانات خلفية لفترة من الوقت ، فمن المحتمل أنك كتبت تعليمات برمجية لتنفيذ الاستعلامات المرقمة. على سبيل المثال - مثل هذا:
SELECT * FROM table_name LIMIT 10 OFFSET 40
على ما هو عليه؟
ولكن إذا كانت هذه هي الطريقة التي قمت بها بترقيم الصفحات ، يؤسفني أن أقول إنك لم تفعل ذلك بأكثر الطرق فعالية.
هل تريد المجادلة معي؟ لك لا لديك لإضاعة الوقت . يستخدم Slack و Shopify و Mixmax بالفعل الحيل التي أريد التحدث عنها اليوم.
اسم الخلفية مطور واحد على الأقل، والتي لم تستخدم قط
OFFSETو LIMITلتنفيذ استعلامات مع ترقيم الصفحات. في MVP (الحد الأدنى من المنتج القابل للتطبيق ، الحد الأدنى من المنتج القابل للتطبيق) وفي المشاريع التي تستخدم كميات صغيرة من البيانات ، يكون هذا النهج قابلاً للتطبيق تمامًا. إنه يعمل فقط ، إذا جاز التعبير.
ولكن إذا كنت بحاجة إلى إنشاء أنظمة موثوقة وفعالة من البداية ، فيجب أن تهتم مسبقًا بكفاءة الاستعلامات في قواعد البيانات المستخدمة في مثل هذه الأنظمة.
سنتحدث اليوم عن المشكلات المرتبطة بالتطبيقات المستخدمة على نطاق واسع (مع الأسف) لمحركات تنفيذ الاستعلام المرقمة ، وكيفية تحقيق أداء عالٍ عند تنفيذ مثل هذه الاستعلامات.
ما هو الخطأ في OFFSET و LIMIT؟
وقال كما كانت عليه،
OFFSETو LIMITتظهر تماما نفسه في المشاريع التي لا تحتاج إلى العمل مع كميات كبيرة من البيانات.
تنشأ المشكلة عندما تنمو قاعدة البيانات إلى هذا الحجم بحيث تتوقف عن ملاءمتها لذاكرة الخادم. ومع ذلك ، أثناء العمل مع قاعدة البيانات هذه ، يجب عليك استخدام الاستعلامات المرقمة.
لكي تتجلى هذه المشكلة ، من الضروري أن تنشأ حالة يلجأ فيها نظام إدارة قواعد البيانات إلى عملية فحص الجدول الكامل غير الفعالة عند تنفيذ كل استعلام باستخدام ترقيم الصفحات (في نفس الوقت ، يمكن أن تحدث عمليات إدخال البيانات وحذفها ، ولا نحتاج إلى بيانات قديمة!).
ما هو "فحص الجدول الكامل" (أو "مسح الجدول التسلسلي" ، المسح المتسلسل)؟ هذه عملية يقرأ خلالها نظام إدارة قواعد البيانات (DBMS) بشكل تسلسلي كل صف من الجدول ، أي البيانات الموجودة فيه ، ويتحقق منها مقابل شرط معين. من المعروف أن هذا النوع من فحص الجدول هو الأبطأ. الحقيقة هي أنه عند تنفيذه ، يتم تنفيذ العديد من عمليات الإدخال / الإخراج التي تستخدم نظام قرص الخادم الفرعي. يتفاقم الموقف بسبب التأخيرات المرتبطة بالعمل مع البيانات المخزنة على الأقراص ، وحقيقة أن نقل البيانات من القرص إلى الذاكرة عملية كثيفة الموارد.
على سبيل المثال ، لديك سجلات لـ 100،000،000 مستخدم وتقوم بتشغيل استعلام بالبناء
OFFSET 50000000... هذا يعني أن نظام إدارة قواعد البيانات (DBMS) سيتعين عليه تحميل كل هذه السجلات (ونحن لا نحتاجها حتى!) ، ووضعها في الذاكرة ، وبعد ذلك فقط ، تم الإبلاغ عن 20 نتيجة LIMIT.
لنفترض أنه قد يبدو مثل "حدد الصفوف من 50000 إلى 50020 من أصل 100000". أي أن النظام سيحتاج أولاً إلى تحميل 50000 صف لتنفيذ الاستعلام. انظر كم العمل غير الضروري الذي يتعين عليها القيام به؟
إذا كنت لا تصدقني ، ألق نظرة على المثال الذي أنشأته باستخدام db-fiddle.com .

مثال على db-fiddle.com
هناك ، على اليسار ، في الحقل
Schema SQL، هناك رمز لإدراج 100،000 صف في قاعدة البيانات ، وعلى اليمين ، في الحقلQuery SQL، يتم عرض استعلامين. الأول ، بطيء ، يبدو كالتالي:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
والثاني وهو حل فعال لنفس المشكلة كالتالي:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
من أجل تلبية هذه الطلبات ، ما عليك سوى النقر فوق الزر الموجود
Runأعلى الصفحة. بعد القيام بذلك ، دعنا نقارن المعلومات حول وقت تنفيذ الاستعلام. اتضح أن تنفيذ استعلام غير فعال يستغرق ما لا يقل عن 30 مرة أطول من تنفيذ الثانية (هذه المرة تختلف من إطلاق إلى إطلاق ، على سبيل المثال ، قد يبلغ النظام أن الطلب الأول استغرق 37 مللي ثانية لإكماله ، و تنفيذ الثانية - 1 مللي ثانية).
وإذا كان هناك المزيد من البيانات ، فسيبدو كل شيء أسوأ (من أجل التحقق من ذلك ، ألق نظرة على المثال الذي قدمته بـ 10 ملايين صف).
يجب أن يمنحك ما ناقشناه للتو نظرة ثاقبة حول كيفية معالجة استعلامات قاعدة البيانات بالفعل.
ضع في اعتبارك أنه كلما زادت القيمة
OFFSET - كلما طالت مدة الطلب.
ما الذي يجب استخدامه بدلاً من الجمع بين OFFSET و LIMIT؟
بدلاً من الجمع
OFFSET، LIMITيجدر استخدام هيكل مبني وفقًا للمخطط التالي:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
هذا هو تنفيذ استعلام ترقيم صفحات يستند إلى المؤشر.
بدلا من تخزينها محليا الحالية
OFFSETو LIMITوإرسالها إلى كل طلب، فمن الضروري لتخزين المفتاح الأساسي تلقى الماضي (عادة - و ID) و LIMIT، ونتيجة لذلك، وستطالب تشبه ذكر أعلاه.
لماذا ا؟ الحقيقة هي أنه من خلال التحديد الصريح لمعرّف آخر سطر قراءة ، فإنك تخبر نظام إدارة قواعد البيانات (DBMS) الخاص بك بالمكان الذي يحتاج إليه لبدء البحث عن البيانات التي يحتاجها. علاوة على ذلك ، سيتم إجراء البحث بكفاءة ، وذلك بفضل استخدام المفتاح ، ولن يضطر النظام إلى تشتيت انتباهه بخطوط خارج النطاق المحدد.
دعنا نلقي نظرة على مقارنة الأداء التالية لطلبات البحث المختلفة. هنا استعلام غير فعال.
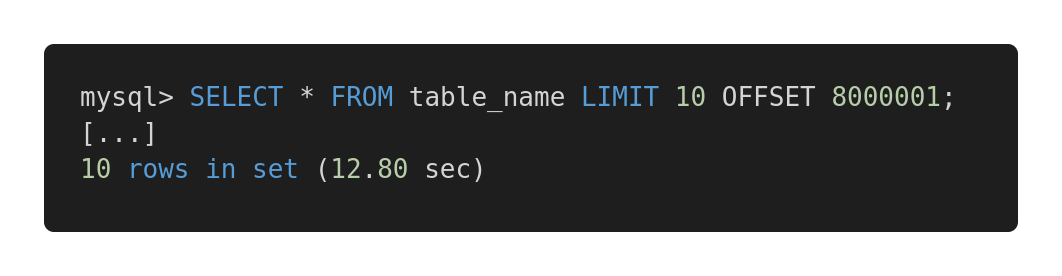
استعلام بطيء
وهنا نسخة محسنة من هذا الاستعلام.

استعلام سريع يُرجع
كلا الاستعلامات نفس كمية البيانات بالضبط. لكن الأول يستغرق 12.80 ثانية ، والثاني يستغرق 0.01 ثانية. هل تشعر بالفرق؟
مشاكل محتملة
لكي تعمل طريقة تنفيذ الاستعلام المقترحة بشكل فعال ، يجب أن يحتوي الجدول على عمود (أو أعمدة) يحتوي على فهارس فريدة ومتسلسلة ، مثل معرف عدد صحيح. في بعض الحالات المحددة ، يمكن أن يحدد هذا مدى نجاح استخدام مثل هذه الاستعلامات من أجل زيادة سرعة العمل مع قاعدة البيانات.
بطبيعة الحال ، عند تصميم الاستعلامات ، يجب أن تأخذ في الاعتبار خصوصيات بنية الجداول ، واختيار الآليات التي ستظهر نفسها بشكل أفضل على الجداول الموجودة. على سبيل المثال ، إذا كنت بحاجة إلى العمل في استعلامات بكميات كبيرة من البيانات ذات الصلة ، فقد تجد هذه المقالة ممتعة .
إذا نحن نواجه مشكلة عدم وجود مفتاح أساسي، على سبيل المثال، إذا كان لدينا جدول مع العديد من لكثير العلاقة، ثم النهج التقليدي باستخدام
OFFSETو LIMITمكفول للعمل بالنسبة لنا. لكن يمكن أن يؤدي تطبيقه إلى تنفيذ استعلامات يحتمل أن تكون بطيئة. في مثل هذه الحالات ، أوصي باستخدام مفتاح أساسي تلقائي التزايد ، حتى إذا كنت بحاجة إليه فقط لتنظيم الاستعلامات المرقمة.
إذا كنت مهتما في هذا الموضوع - هنا ، هنا و هنا - بعض المواد المفيدة.
النتيجة
الاستنتاج الرئيسي الذي يمكننا استخلاصه هو أنه من الضروري دائمًا تحليل سرعة تنفيذ الاستعلام ، مهما كان حجم قواعد البيانات. في عصرنا ، تعد قابلية تطوير الحلول مهمة للغاية ، وإذا قمت بتصميم كل شيء بشكل صحيح منذ بداية العمل على نظام معين ، فإن هذا ، في المستقبل ، يمكن أن ينقذ المطور من العديد من المشاكل.
كيف تقوم بتحليل وتحسين استعلامات قاعدة البيانات؟
