الجزء 2
الجزء 3
في هذه المقالة سوف تتعلم:
- ما هو نقل التعلم وكيف يعمل
- ما هو التقسيم الدلالي / المثيل وكيف يعمل
- حول ما هو اكتشاف الكائن وكيف يعمل
المقدمة
توجد طريقتان لمهام اكتشاف الكائنات (انظر المصدر ومزيد من التفاصيل هنا ):
- اثنين من الأساليب -stage، بل هي أيضا "الأساليب على أساس المناطق" (المهندس الأساليب على أساس المنطقة.) - نهج ينقسم إلى مرحلتين. في المرحلة الأولى ، يتم تحديد مناطق الاهتمام (RoI) عن طريق البحث الانتقائي أو باستخدام طبقة خاصة من الشبكة العصبية - المناطق التي تحتوي على كائنات ذات احتمالية عالية. في المرحلة الثانية ، يتم النظر في المناطق المحددة من قبل المصنف لتحديد الانتماء إلى الفئات الأصلية ومن خلال المسجل ، الذي يحدد موقع المربعات المحيطة.
- طريقة المرحلة الواحدة ( طرق Engl ذات المرحلة الواحدة.) - النهج ، عدم استخدام خوارزمية منفصلة لإنشاء مناطق بدلاً من ذلك توقع إحداثيات قدر معين من المربعات المحيطة بخصائص مختلفة ، مثل نتائج التصنيف ودرجة الثقة ، وتعديل إطار عمل الموقع.
تتناول هذه المقالة طرق الخطوة الواحدة.
نقل التعلم
التعلم الانتقالي هو طريقة لتدريب الشبكات العصبية ، حيث نأخذ نموذجًا تم تدريبه بالفعل على بعض البيانات لمزيد من التدريب الإضافي لحل مشكلة أخرى. على سبيل المثال ، لدينا نموذج EfficientNet-B5 مدرب على مجموعة بيانات ImageNet (1000 فئة). الآن ، في أبسط الحالات ، نقوم بتغيير آخر طبقة مصنف (لنقل ، لتصنيف كائنات من 10 فئات).
ألق نظرة على الصورة أدناه:
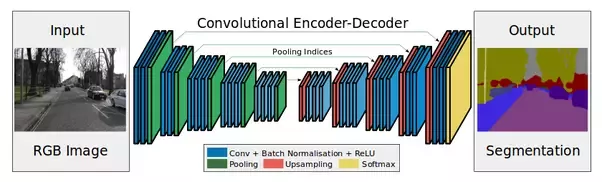
التشفير - هذه عبارة عن طبقات تجميع فرعية (تلافيفات وتجمعات).
يبدو استبدال الطبقة الأخيرة في الكود كما يلي (framework - pytorch ، البيئة - google colab):
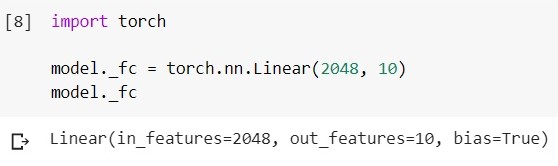
قم بتحميل نموذج EfficientNet-b5 المدرب وانظر إلى طبقة المصنف الخاصة به: قم

بتغيير هذه الطبقة إلى أخرى:
هناك حاجة إلى وحدة فك التشفير ، على وجه الخصوص ، في مهمة التجزئة (حول هذا بالإضافة إلى ذلك).
نقل استراتيجيات التعلم
يجب أن نضيف أنه افتراضيًا ، يمكن تدريب جميع طبقات النموذج التي نريد تدريبها بشكل أكبر. يمكننا "تجميد" أوزان بعض الطبقات.
لتجميد كل الطبقات:

كلما قل عدد الطبقات التي نقوم بتدريبها ، كلما قلت الموارد الحسابية التي نحتاجها لتدريب النموذج. هل هذه التقنية مبررة دائما؟
اعتمادًا على كمية البيانات التي نريد تدريب الشبكة عليها ، وعلى البيانات التي تم تدريب الشبكة عليها ، هناك 4 خيارات لتطوير الأحداث لنقل التعلم (تحت "قليل" و "كثير" يمكنك أن تأخذ القيمة الشرطية 10 كيلو):
- كنت لديهم القليل من البيانات ، وهذا هو مماثل للبيانات التي تم تدريب الشبكة قبل. يمكنك محاولة تدريب الطبقات القليلة الماضية فقط.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
التقسيم الدلالي هو عندما نقوم بتغذية صورة كمدخلات ، وعند الإخراج نريد أن نحصل على شيء مثل: بشكل

أكثر رسمية ، نريد تصنيف كل بكسل من الصورة المدخلة - لفهم الفئة التي تنتمي إليها.
هناك الكثير من الأساليب والفروق الدقيقة هنا. ما هي بنية شبكة ResNeSt-269 فقط :)
الحدس - عند إدخال الصورة (h ، w ، c) ، عند الإخراج نريد الحصول على قناع (h ، w) أو (h ، w ، c) ، حيث c هو عدد الفئات (يعتمد على البيانات والنموذج). دعونا الآن نضيف وحدة فك ترميز بعد برنامج التشفير لدينا ونقوم بتدريبهم.
سيتألف مفكك الشفرة ، على وجه الخصوص ، من طبقات الاختزال. يمكنك زيادة البعد ببساطة عن طريق "تمديد" خريطة المعالم الخاصة بنا في الطول والعرض في خطوة أو أخرى. عند السحب ، يمكنك استخدامالاستيفاء الثنائي الخطي (في الكود سيكون واحدًا فقط من معلمات الطريقة).
Deeplabv3 + بنية الشبكة:
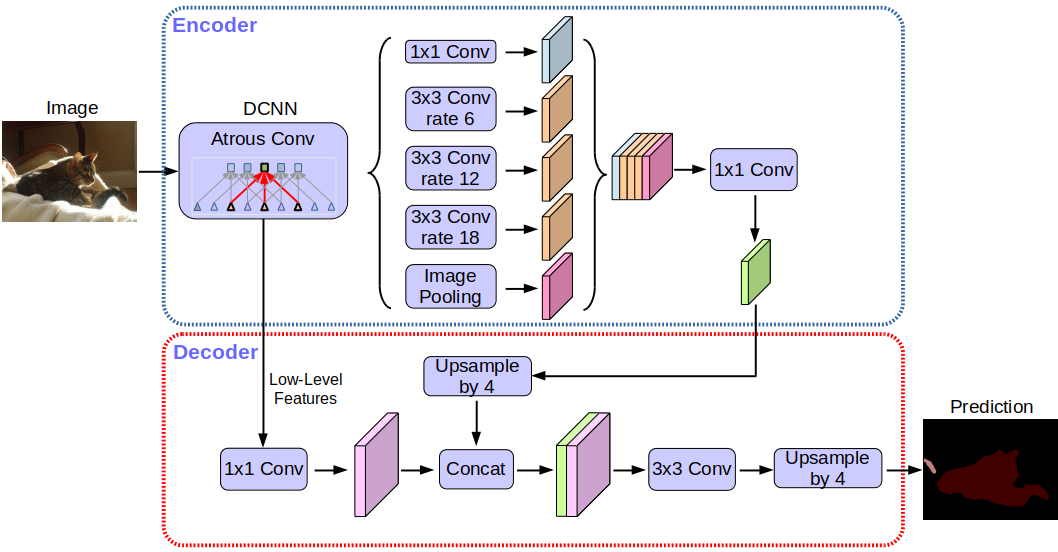
دون الخوض في التفاصيل ، ستلاحظ أن الشبكة تستخدم بنية وحدة فك التشفير.
نسخة أكثر كلاسيكية ، بنية شبكة U-net:
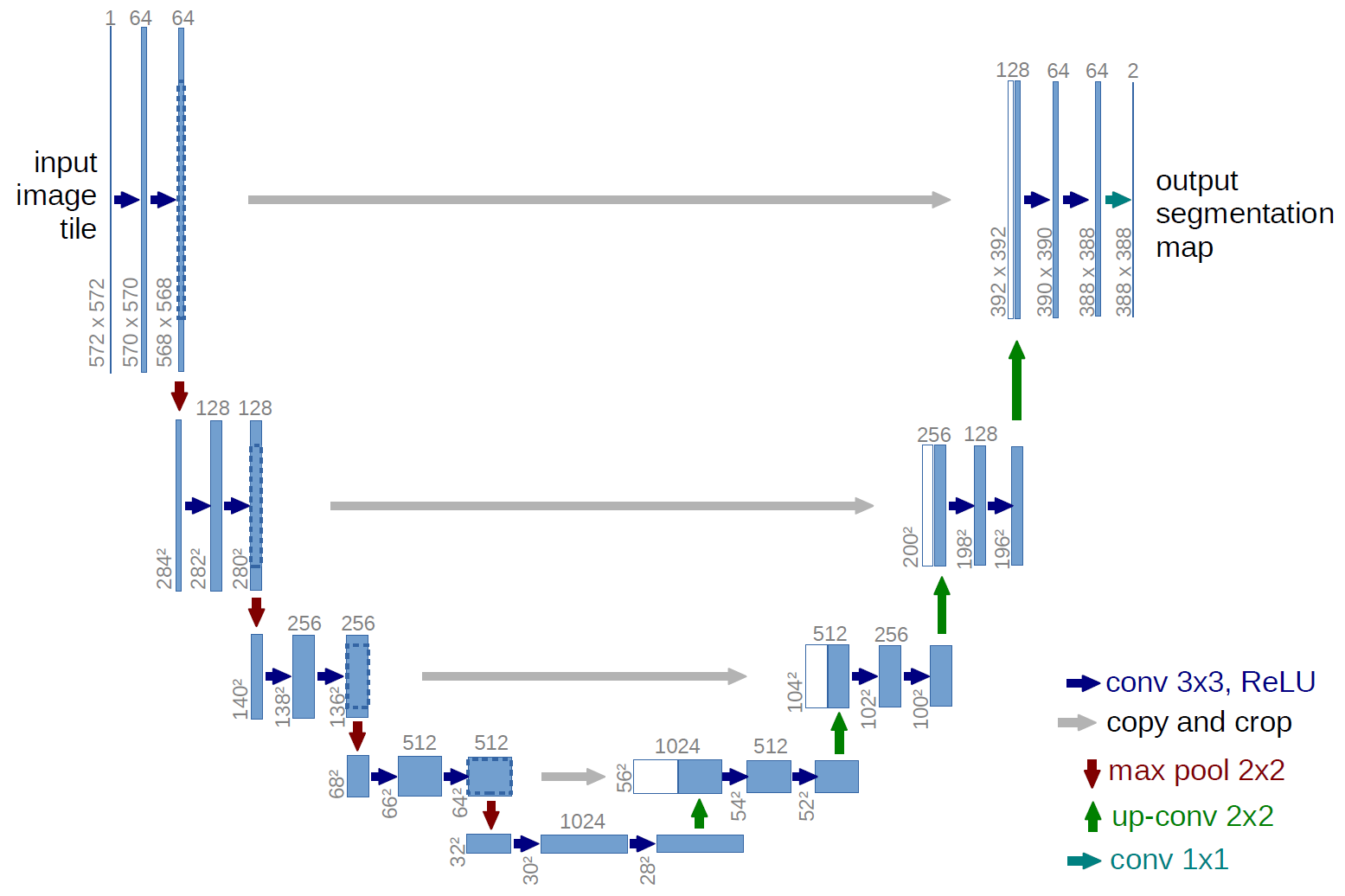
ما هي هذه الأسهم الرمادية؟ هذه هي ما يسمى وصلات التخطي. النقطة المهمة هي أن المشفر "يشفر" صورة الإدخال مع فقدان البيانات. لتقليل هذه الخسائر ، يستخدمون وصلات التخطي.
في هذه المهمة ، يمكننا استخدام نقل التعلم - على سبيل المثال ، يمكننا استخدام شبكة مع مشفر مدرب بالفعل وإضافة وحدة فك ترميز وتدريبها.
ما هي البيانات والنماذج ذات الأداء الأفضل في هذه المهمة في الوقت الحالي - يمكنك أن ترى هنا...
تجزئة المثيل
نسخة أكثر تعقيدًا من مشكلة التجزئة. جوهرها هو أننا لا نريد فقط تصنيف كل بكسل من صورة الإدخال ، ولكن أيضًا تحديد كائنات مختلفة من نفس الفئة بطريقة ما:
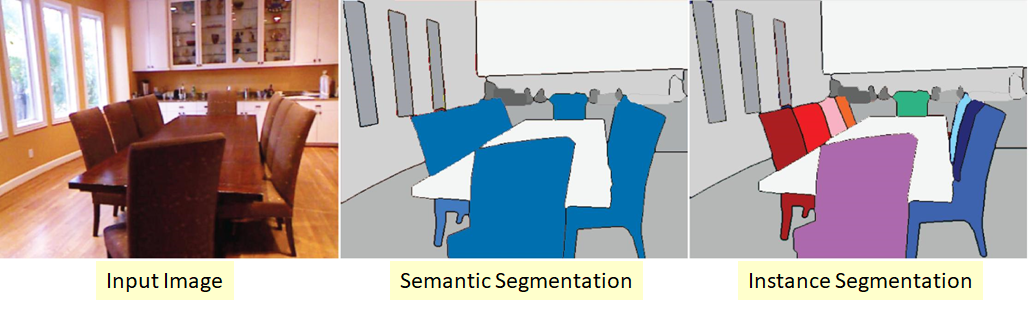
يحدث أن تكون الفئات "مثبتة" أو لا يوجد حد مرئي بينها ، لكننا نريد تحديد كائنات من نفس الفئة بعيدا، بمعزل، على حد.
هناك أيضا عدة طرق هنا. الأبسط والأكثر بديهية هو أننا نقوم بتدريب شبكتين مختلفتين. نقوم بتعليم أول واحد لتصنيف وحدات البكسل لبعض الفئات (التجزئة الدلالية) ، والثاني لتصنيف البكسل بين كائنات الفئة. نحصل على قناعين. يمكننا الآن طرح الثانية من الأولى والحصول على ما أردناه :)
حول البيانات والنماذج التي تحقق أفضل أداء في هذه المهمة في الوقت الحالي - يمكنك أن ترى هنا...
Object detection
نرسل صورة إلى المدخلات ، وعند الإخراج نريد أن نرى شيئًا كهذا:

الشيء الأكثر بديهية الذي يمكن القيام به هو "الجري" فوق الصورة باستخدام مستطيلات مختلفة ، وباستخدام مصنف مدرب بالفعل ، حدد ما إذا كان هناك شيء يثير اهتمامنا في هذه المنطقة. يوجد مثل هذا المخطط ، لكن من الواضح أنه ليس الأفضل. بعد كل شيء ، لدينا طبقات تلافيفية تفسر بطريقة ما خريطة المعالم "قبل" (أ) في خريطة المعالم "بعد" (ب). في هذه الحالة ، نعرف أبعاد مرشحات الالتفاف => نحن نعرف وحدات البكسل من A إلى وحدات البكسل B التي تم تحويلها.
لنلقِ نظرة على YOLO v3:
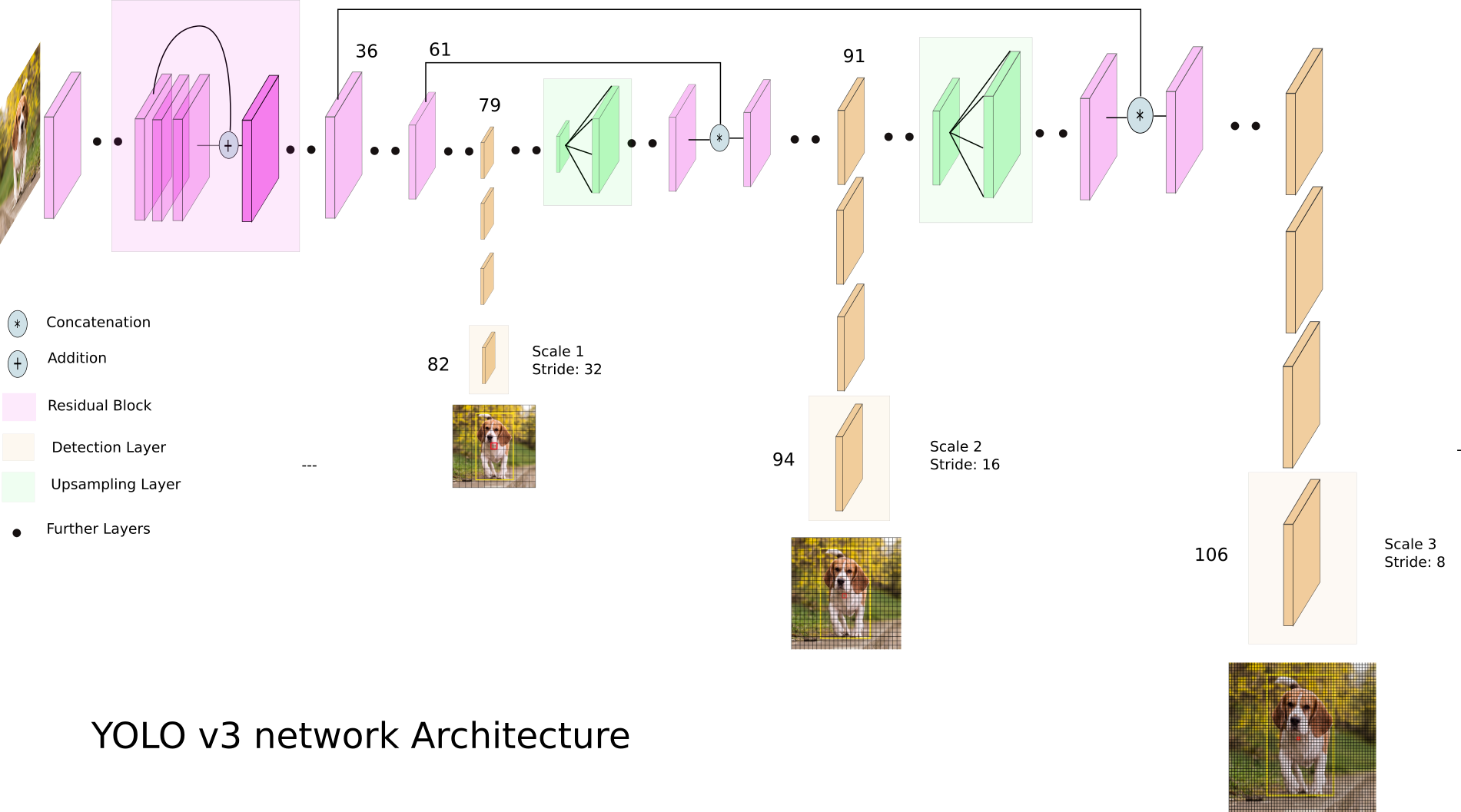
يستخدم YOLO v3 خرائط ميزات أبعاد مختلفة. يتم ذلك ، على وجه الخصوص ، من أجل اكتشاف الأشياء ذات الأحجام المختلفة بشكل صحيح.
بعد ذلك ، يتم تسلسل جميع المقاييس الثلاثة:
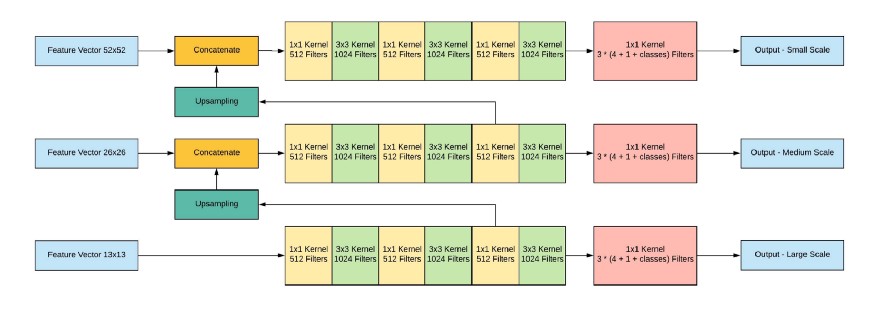
إخراج الشبكة ، مع صورة إدخال 416x416 ، 13x13x (B * (5 + C)) ، حيث C هو عدد الفئات ، B هو عدد الصناديق لكل منطقة (YOLO v3 بها 3 منها). 5 - هذه معلمات مثل: Px ، Py - إحداثيات مركز الكائن ، Ph ، Pw - ارتفاع وعرض الكائن ، Pobj - احتمالية وجود الكائن في هذه المنطقة.
لنلقِ نظرة على الصورة ، لذلك ستكون أكثر وضوحًا: تقوم

YOLO بتصفية بيانات التنبؤ مبدئيًا حسب درجة الكائن حسب بعض القيمة (عادةً 0.5-0.6) ، ثم من خلال عدم الحد الأقصى للقمع .
ما هي البيانات والنماذج الأفضل أداءً في هذه المهمة في الوقت الحالي - يمكنك أن ترى هنا .
خاتمة
هناك الكثير من النماذج والأساليب المختلفة لمهام تجزئة الكائنات وتوطينها هذه الأيام. هناك بعض الأفكار التي بمجرد فهمها ، ستجعل من السهل تفكيك تلك الحديقة من النماذج والأساليب. حاولت التعبير عن هذه الأفكار في هذا المقال.
في المقالات التالية ، سنتحدث عن عمليات نقل النمط وشبكات GAN.