فوائد استخدام TensorFlow.js في المتصفح
- التفاعلية - يحتوي المتصفح على العديد من الأدوات لتصور العمليات الجارية (رسومات ، رسوم متحركة ، إلخ) ؛
- أجهزة الاستشعار - يتمتع المتصفح بإمكانية الوصول المباشر إلى مستشعرات الجهاز (الكاميرا ونظام تحديد المواقع العالمي ومقياس التسارع وما إلى ذلك) ؛
- أمان بيانات المستخدم - ليست هناك حاجة لإرسال البيانات المعالجة إلى الخادم ؛
- التوافق مع النماذج التي تم إنشاؤها في Python .
أداء
أحد القضايا الرئيسية هو الأداء.
نظرًا لحقيقة أن التعلم الآلي ، في الواقع ، يؤدي أنواعًا مختلفة من العمليات الرياضية باستخدام بيانات تشبه المصفوفة (الموترات) ، تستخدم مكتبة هذا النوع من الحسابات في المتصفح WebGL. هذا يحسن الأداء بشكل كبير إذا تم إجراء نفس العمليات في JS خالص. بطبيعة الحال ، تحتوي المكتبة على احتياطي في حالة عدم دعم WebGL في المتصفح لسبب ما (في وقت كتابة هذا التقرير ، يوضح caniuse أن 97.94 ٪ من المستخدمين لديهم دعم WebGL).
لتحسين الأداء ، يستخدم Node.js الربط الأصلي مع TensorFlow. هنا، وحدة المعالجة المركزية، GPU وTPU ( وحدة المعالجة التنسور ) يمكن أن تكون بمثابة المعجلات
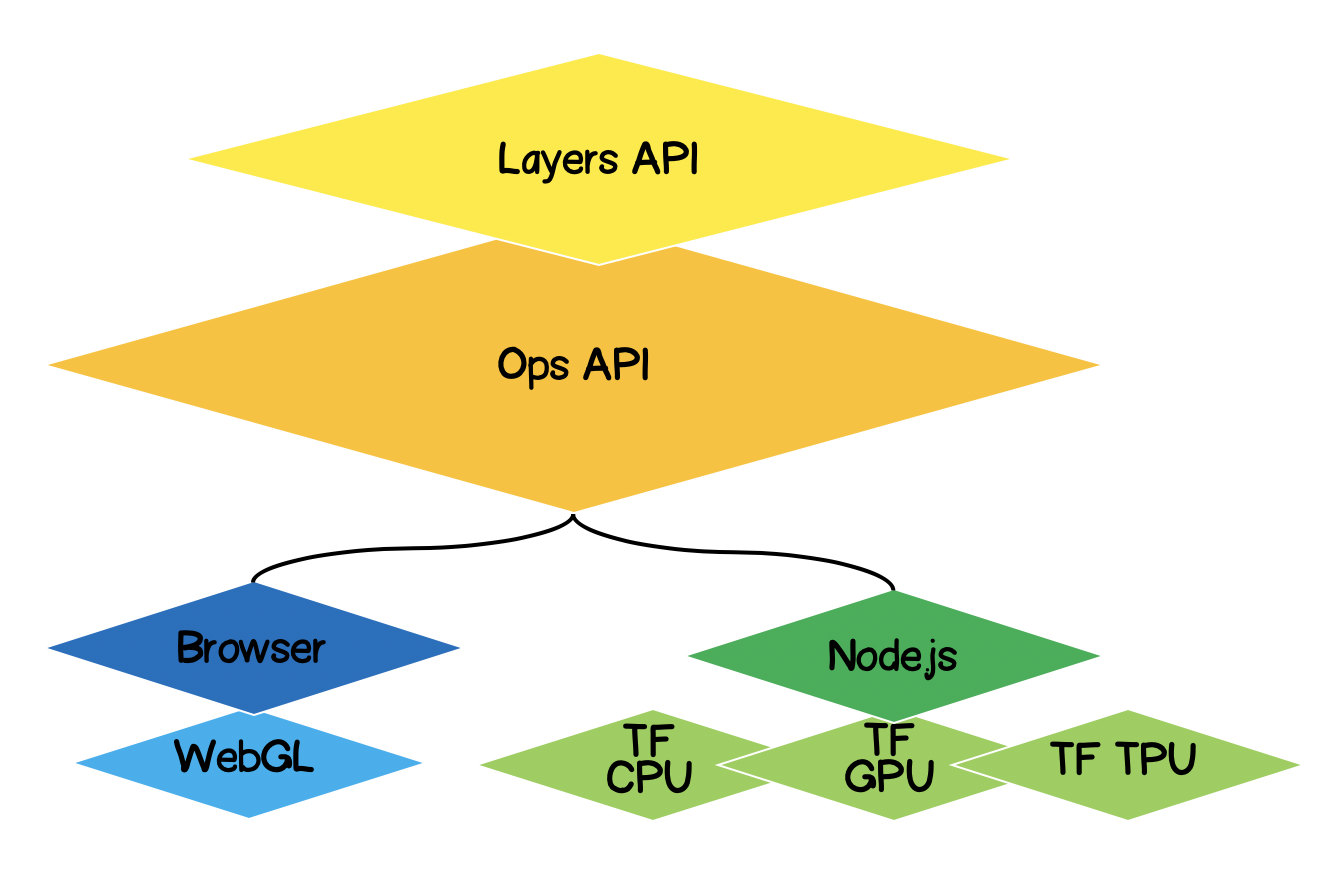
هندسة TensorFlow.js
- الطبقة الدنيا - هذه الطبقة مسؤولة عن موازنة العمليات الحسابية عند إجراء عمليات حسابية على الموترات.
- Ops API - يوفر واجهة برمجة التطبيقات (API) لأداء العمليات الحسابية على التنسورات.
- Layers API - يسمح لك بإنشاء نماذج معقدة من الشبكات العصبية باستخدام أنواع مختلفة من الطبقات (كثيفة ، تلافيفية). تشبه هذه الطبقة واجهة برمجة تطبيقات Keras Python ولديها القدرة على تحميل شبكات Keras Python سابقة التدريب.
صياغة المشكلة
من الضروري إيجاد معادلة الدالة الخطية التقريبية لمجموعة معينة من النقاط التجريبية. بعبارة أخرى ، نحتاج إلى إيجاد مثل هذا المنحنى الخطي الذي سيكون أقرب إلى النقاط التجريبية.

إضفاء الطابع الرسمي على الحل
سيكون جوهر أي تعلم آلي نموذجًا ، وفي حالتنا هذه هي معادلة الدالة الخطية:
بناءً على الحالة ، لدينا أيضًا مجموعة من النقاط التجريبية:
افترض أن الخطوة الثالثة من التدريب تم حساب المعاملات التالية للمعادلة الخطية ... نحتاج الآن إلى التعبير رياضيًا عن مدى دقة المعاملات المختارة. للقيام بذلك ، نحتاج إلى حساب الخطأ (الخسارة) ، والذي يمكن تحديده ، على سبيل المثال ، من خلال الانحراف المعياري. يقدم Tensorflow.js مجموعة من وظائف الخسارة شائعة الاستخدام: tf.metrics.meanAbsoluteError ، tf.metrics.meanSquaredError ، إلخ.
الغرض من التقريب هو تقليل وظيفة الخطأ ... دعونا نستخدم طريقة الانحدار لهذا. انه ضروري:
- - أوجد التدرج المتجهي بحساب المشتقات الجزئية بالنسبة للمعاملات ؛
- - صحح معاملات المعادلة في الاتجاه المعاكس لاتجاه متجه التدرج. وبالتالي ، سنقلل من وظيفة الخطأ:
أين هو معدل التعلم وهو أحد المعلمات القابلة للتعديل للنموذج. بالنسبة للنسب المتدرج ، فإنه لا يتغير طوال عملية التعلم. يمكن أن تؤدي القيمة الصغيرة لمعدل التعلم إلى تقارب طويل في عملية التعلم الخاصة بالنموذج وضربة محتملة في الحد الأدنى المحلي (الشكل 2) ، ويمكن أن تؤدي القيمة الكبيرة جدًا إلى زيادة لا نهائية في قيمة الخطأ في كل خطوة من خطوات التدريب ، الشكل 1.
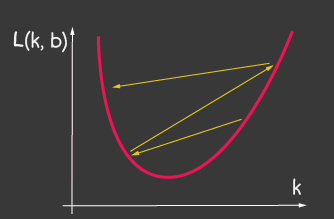
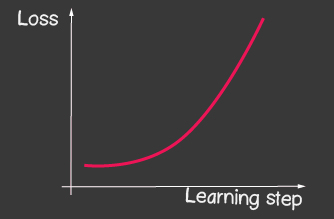
|


|
|---|---|
| الشكل 1: القيمة العالية لمعدل التعلم | الشكل 2: معدل التعلم الصغير |
كيفية تنفيذه بدون Tensorflow.js
على سبيل المثال ، سيبدو حساب قيمة دالة الخسارة (الانحراف المعياري) كما يلي:
function loss(ysPredicted, ysReal) {
const squaredSum = ysPredicted.reduce(
(sum, yPredicted, i) => sum + (yPredicted - ysReal[i]) ** 2,
0);
return squaredSum / ysPredicted.length;
}
ومع ذلك ، يمكن أن تكون كمية بيانات الإدخال كبيرة. أثناء تدريب النموذج ، نحتاج إلى حساب ليس فقط قيمة دالة الخسارة في كل تكرار ، ولكن أيضًا إجراء عمليات أكثر جدية - حساب التدرج اللوني. لذلك ، من المنطقي استخدام Tensorflow ، الذي يحسن العمليات الحسابية باستخدام WebGL. علاوة على ذلك ، يصبح الرمز أكثر تعبيرًا ، قارن:
function loss(ysPredicted, ysReal) => {
const ysPredictedTensor = tf.tensor(ysPredicted);
const ysRealTensor = tf.tensor(ysReal);
const loss = ysPredictedTensor.sub(ysRealTensor).square().mean();
return loss.dataSync()[0];
};
الحل باستخدام TensorFlow.js
الخبر السار هو أننا لن نضطر إلى كتابة مُحسِّن لوظيفة خطأ معينة (خسارة) ، ولن نطور طرقًا رقمية لحساب المشتقات الجزئية ، لقد قمنا بالفعل بتنفيذ خوارزمية backpropogation لنا. نحتاج فقط إلى اتباع الخطوات التالية:
- وضع نموذج (دالة خطية ، في حالتنا) ؛
- وصف دالة الخطأ (في حالتنا ، هذا هو الانحراف المعياري)
- اختر أحد المحسّنين المنفذين (من الممكن توسيع المكتبة بالتنفيذ الخاص بك)
ما هو الموتر
لقد صادف الجميع بالتأكيد موترات في الرياضيات - هذه هي عددية ، ناقلات ، ثنائية الأبعاد - مصفوفة ، ثلاثية الأبعاد - مصفوفة. الموتر هو مفهوم معمم لكل ما سبق. هذه حاوية بيانات تحتوي على بيانات من نوع متجانس (يدعم Tensorflow int32 و float32 و bool و complex64 و string) وله شكل محدد (عدد المحاور (الترتيب) وعدد العناصر في كل محور). أدناه سننظر في الموترات حتى المصفوفات ثلاثية الأبعاد ، ولكن نظرًا لأن هذا تعميم ، يمكن أن يحتوي الموتر على العديد من المحاور كما نحب: 5D ، 6D ، ... ND.
يحتوي TensorFlow على واجهة برمجة التطبيقات التالية لتوليد الموتر:
tf.tensor (values, shape?, dtype?)حيث الشكل هو شكل الموتر ويتم إعطاؤه بواسطة مصفوفة ، حيث يكون عدد العناصر هو عدد المحاور ، وتحدد كل قيمة من الصفيف عدد العناصر على طول كل محور. على سبيل المثال ، لتعريف مصفوفة 4 × 2 (4 صفوف ، عمودان) ، يتخذ النموذج الشكل [4 ، 2].
| التصور | وصف |
|---|---|

|
الترتيب القياسي : 0 الشكل: [] هيكل JS: واجهة برمجة تطبيقات TensorFlow: |

|
رتبة المتجه : 1 الشكل: [4] هيكل JS: واجهة برمجة تطبيقات TensorFlow: |
 |
رتبة المصفوفة : 2 الشكل: [4،2] هيكل JS: واجهة برمجة تطبيقات TensorFlow: |
 |
رتبة المصفوفة : 3 الشكل: [4،2،3] هيكل JS: واجهة برمجة تطبيقات TensorFlow: |
التقريب الخطي باستخدام TensorFlow.js
في البداية ، سنتحدث عن جعل الشفرة قابلة للتوسيع. يمكننا تحويل التقريب الخطي إلى تقريب النقاط التجريبية بواسطة دالة من أي نوع. سيبدو التسلسل الهرمي للفئة على

النحو التالي : لنبدأ في تنفيذ طرق الفئة abstract ، باستثناء الطرق المجردة التي سيتم تحديدها في الفئات الفرعية ، وهنا سنترك فقط أبودًا بها أخطاء إذا لم يتم تعريف الطريقة في الفئة الفرعية لسبب ما.
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
}لذلك ، في منشئ النموذج ، حددنا العرض والارتفاع - هذان هما العرض والارتفاع الحقيقيان للمستوى الذي سنضع عليه النقاط التجريبية. هذا ضروري لتطبيع بيانات الإدخال. أولئك. اذا كان لديناثم بعد التطبيع سيكون لدينا:
OptizerFunction - سنجعل مهمة المحسن مرنة ، حتى نتمكن من تجربة أدوات تحسين أخرى متوفرة في المكتبة ، بشكل افتراضي قمنا بتعيين طريقة Stochastic Gradient Descent tf.train.sgd . أوصي أيضًا باللعب مع المحسّنين الآخرين المتاحين الذين يمكنهم تعديل معدل التعلم أثناء التدريب وتحسين عملية التعلم بشكل كبير ، على سبيل المثال ، جرب المحسّنين التاليين: tf.train.momentum ، tf.train.adam .
من أجل عملية التعلم لا نهاية، حددنا معلمتين maxEpochPerTrainSesion و expectedLoss- بهذه الطريقة سنوقف عملية التدريب إما عند الوصول إلى الحد الأقصى لعدد التكرارات التدريبية ، أو عندما تصبح قيمة دالة الخطأ أقل من الخطأ المتوقع (سنأخذ كل شيء في الاعتبار في طريقة القطار أدناه).
في المُنشئ ، نسمي طريقة initModelVariables - ولكن كما هو متفق عليه ، فإننا نضعها ونعرّفها في الفصل الفرعي لاحقًا.
initModelVariables() {
throw Error('Model variables should be defined')
}
الآن دعنا ننفذ الطريقة الرئيسية لنموذج القطار:
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert array into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
يعد trainSession أساسًا معرفًا فريدًا لجلسة التدريب في حالة استدعاء واجهة برمجة التطبيقات الخارجية لطريقة القطار ، في حين أن جلسة التدريب السابقة لم تنته بعد.
من الكود يمكنك أن ترى أننا قمنا بإنشاء tensor1d من مصفوفات أحادية البعد ، بينما يجب تسوية البيانات مسبقًا ، فإن وظائف التسوية هنا:
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
في حلقة ، لكل خطوة تدريب ، نسمي مُحسِّن النموذج ، الذي نحتاج إلى تمرير وظيفة الخسارة إليه. كما هو متفق عليه ، سيتم تعيين دالة الخسارة من خلال الانحراف المعياري. ثم باستخدام API tensorflow.js لدينا:
/**
* Calculate loss function as mean-square deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
// L = sum ((x_pred_i - x_real_i)^2) / N
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
تستمر عملية التعلم أثناء
- لن يتم الوصول إلى الحد الأقصى لعدد التكرارات
- لن تتحقق دقة الخطأ المطلوبة
- لم تبدأ عملية تدريب جديدة
لاحظ أيضًا كيف يتم استدعاء وظيفة الخسارة. للحصول على قيمة متوقعة - نسمي الوظيفة f - والتي ، في الواقع ، ستحدد الشكل الذي سيتم تنفيذ الانحدار وفقًا له ، وفي الفئة المجردة ، كما هو متفق عليه ، نضع كعبًا:
f(x) {
throw Error('Model should be defined')
}
في كل خطوة من خطوات التدريب ، في خاصية كائن نموذج التاريخ ، نحفظ ديناميات تغيير الخطأ في كل فترة تدريب.
بعد عملية تدريب النموذج ، نحتاج إلى طريقة تقبل المدخلات والمخرجات المحسوبة باستخدام النموذج المدرب. للقيام بذلك ، في واجهة برمجة التطبيقات ، حددنا طريقة التنبؤ وهي تبدو كالتالي:
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
انتبه إلى arraySync ، عن طريق القياس مع node.js ، إذا كانت هناك طريقة arraySync ، فهناك بالتأكيد طريقة مصفوفة غير متزامنة تُرجع Promise. الوعد مطلوب هنا ، لأنه كما قلنا سابقًا ، يتم ترحيل جميع الموترات إلى WebGL لتسريع العمليات الحسابية وتصبح العملية غير متزامنة ، لأن نقل البيانات من WebGL إلى متغير JS يستغرق وقتًا.
انتهينا من الفصل التجريدي ، يمكنك مشاهدة النسخة الكاملة من الكود هنا:
AbstractRegressionModel.js
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
initModelVariables() {
throw Error('Model variables should be defined')
}
f() {
throw Error('Model should be defined')
}
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
/**
* Calculate loss function as mean-squared deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert data into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
stop() {
this.trainSession++;
}
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
}
للانحدار الخطي ، دعنا نحدد صنفًا جديدًا يرث من الصنف المجرد ، حيث نحتاج فقط إلى تعريف طريقتين initModelVariables و f .
نظرًا لأننا نعمل على تقريب خطي ، يجب أن نحدد متغيرين ك ، ب - وسيكونان موترات قياسية. بالنسبة للمحسن ، يجب أن نشير إلى أنها قابلة للتخصيص (المتغيرات) ، وتعيين أرقام عشوائية كقيم أولية.
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}ضع في اعتبارك واجهة برمجة التطبيقات للمتغير هنا :
tf.variable (initialValue, trainable?, name?, dtype?)انتبه إلى الوسيطة الثانية إلى trainable - وهو متغير منطقي ويكون صحيحًا افتراضيًا . يتم استخدامه من قبل المحسّنين ، والذي يخبرهم ما إذا كان من الضروري تكوين هذا المتغير عند تقليل وظيفة الخسارة. يمكن أن يكون هذا مفيدًا عندما نقوم ببناء نموذج جديد يعتمد على نموذج تم تنزيله مسبقًا من Keras Python ، ونحن على ثقة من أنه ليست هناك حاجة لإعادة تدريب بعض الطبقات في هذا النموذج.
بعد ذلك ، نحتاج إلى تحديد معادلة الدالة التقريبية باستخدام tensorflow API ، وإلقاء نظرة على الكود وستفهم بشكل بديهي كيفية استخدامه:
f(x) {
// y = kx + b
return x.mul(this.k).add(this.b);
}على سبيل المثال ، بهذه الطريقة يمكنك تحديد تقريب تربيعي:
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f(x) {
// y = ax^2 + bx + c
return this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}يمكنك التحقق من نماذج الانحدار الخطي والتربيعي هنا:
LinearRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class LinearRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}
f = x => x.mul(this.k).add(this.b);
}
QuadraticRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class QuadraticRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f = x => this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}
يوجد أدناه بعض التعليمات البرمجية المكتوبة في React والتي تستخدم نموذج الانحدار الخطي المكتوب وتقوم بإنشاء UX للمستخدم:
الانحدار. js
import React, { useState, useEffect } from 'react';
import Canvas from './components/Canvas';
import LossPlot from './components/LossPlot_v3';
import LinearRegressionModel from './model/LinearRegressionModel';
import './RegressionModel.scss';
const WIDTH = 400;
const HEIGHT = 400;
const LINE_POINT_STEP = 5;
const predictedInput = Array.from({ length: WIDTH / LINE_POINT_STEP + 1 })
.map((v, i) => i * LINE_POINT_STEP);
const model = new LinearRegressionModel(WIDTH, HEIGHT);
export default () => {
const [points, changePoints] = useState([]);
const [curvePoints, changeCurvePoints] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
if (points.length > 0) {
const input = points.map(({ x }) => x);
const output = points.map(({ y }) => y);
model.train(input, output, () => {
changeCurvePoints(() => model.predict(predictedInput));
changeLossHistory(() => model.history);
});
}
}, [points]);
return (
<div className="regression-low-level">
<div className="regression-low-level__top">
<div className="regression-low-level__workarea">
<div className="regression-low-level__canvas">
<Canvas
width={WIDTH}
height={HEIGHT}
points={points}
curvePoints={curvePoints}
changePoints={changePoints}
/>
</div>
<div className="regression-low-level__toolbar">
<button
className="btn btn-red"
onClick={() => model.stop()}>Stop
</button>
<button
className="btn btn-yellow"
onClick={() => {
model.stop();
changePoints(() => []);
changeCurvePoints(() => []);
}}>Clear
</button>
</div>
</div>
<div className="regression-low-level__loss">
<LossPlot
loss={lossHistory}/>
</div>
</div>
</div>
)
}نتيجة:
أوصي بشدة بالقيام بالمهام التالية:
- لتنفيذ تقريب الوظيفة بواسطة الدالة اللوغاريتمية
- بالنسبة إلى مُحسِّن tf.train.sgd ، حاول اللعب باستخدام LearningRate ولاحظ كيف تتغير عملية التعلم. حاول ضبط معدل التعلم على درجة عالية جدًا للحصول على الصورة الموضحة في الشكل 2.
- اضبط المُحسِّن على tf.train.adam. هل تحسنت عملية التعلم؟ ما إذا كانت عملية التعلم تعتمد على تغيير قيمة LearningRate في منشئ النموذج.