في الآونة الأخيرة ، بدأ الزملاء في "المتجر" يسألونني بشكل مستقل: كيف أحصل على جميع قنوات Bluetooth من جهاز استقبال SDR واحد في وقت واحد؟ يسمح عرض النطاق الترددي بوجود SDR بعرض نطاق خرج يبلغ 80 ميجاهرتز أو أكثر. يمكنك بالطبع القيام بذلك على FPGA ، لكن وقت التطوير سيكون طويلًا جدًا. لقد عرفت منذ فترة طويلة أنه من السهل جدًا القيام بذلك على وحدة معالجة الرسومات ، ولكن هذا كل شيء!
يحدد معيار Bluetooth الطبقة المادية في نسختين: Classic و Low Energy. المواصفات هنا . الوثيقة كبيرة بشكل رهيب ؛ قراءتها بأكملها تشكل خطورة على الدماغ. لحسن الحظ ، تمتلك شركات الأجهزة الكبيرة الوسائل لإنشاء مستندات مرئية حول موضوع ما. Tektronix و National Instruments ، على سبيل المثال. ليس لدي أي فرصة على الإطلاق للتنافس معهم من حيث جودة عرض المواد. إذا كنت مهتمًا ، يرجى اتباع الروابط.
كل ما أحتاج لمعرفته حول الطبقة المادية لإنشاء مرشح متعدد القنوات هو خطوة شبكة التردد ومعدل التشكيل. تم جدولتها في إحدى الوثائق المحددة:
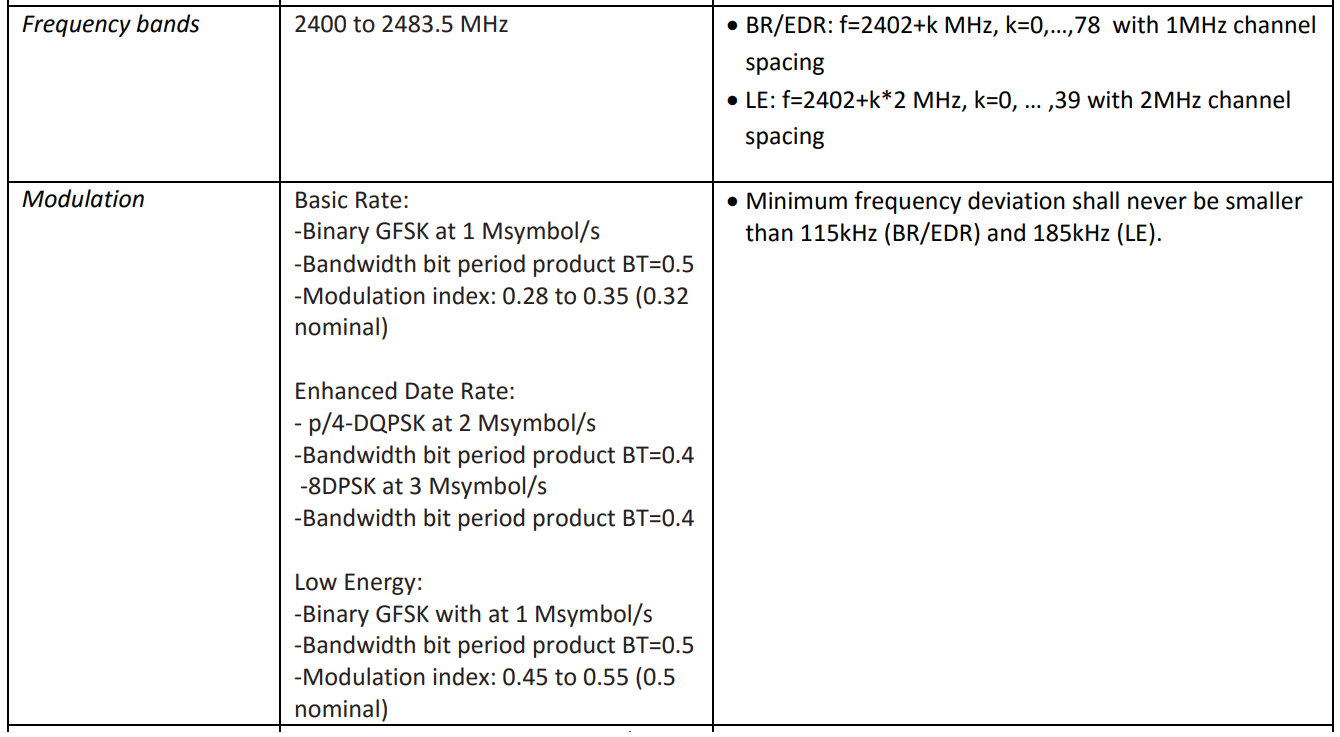
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
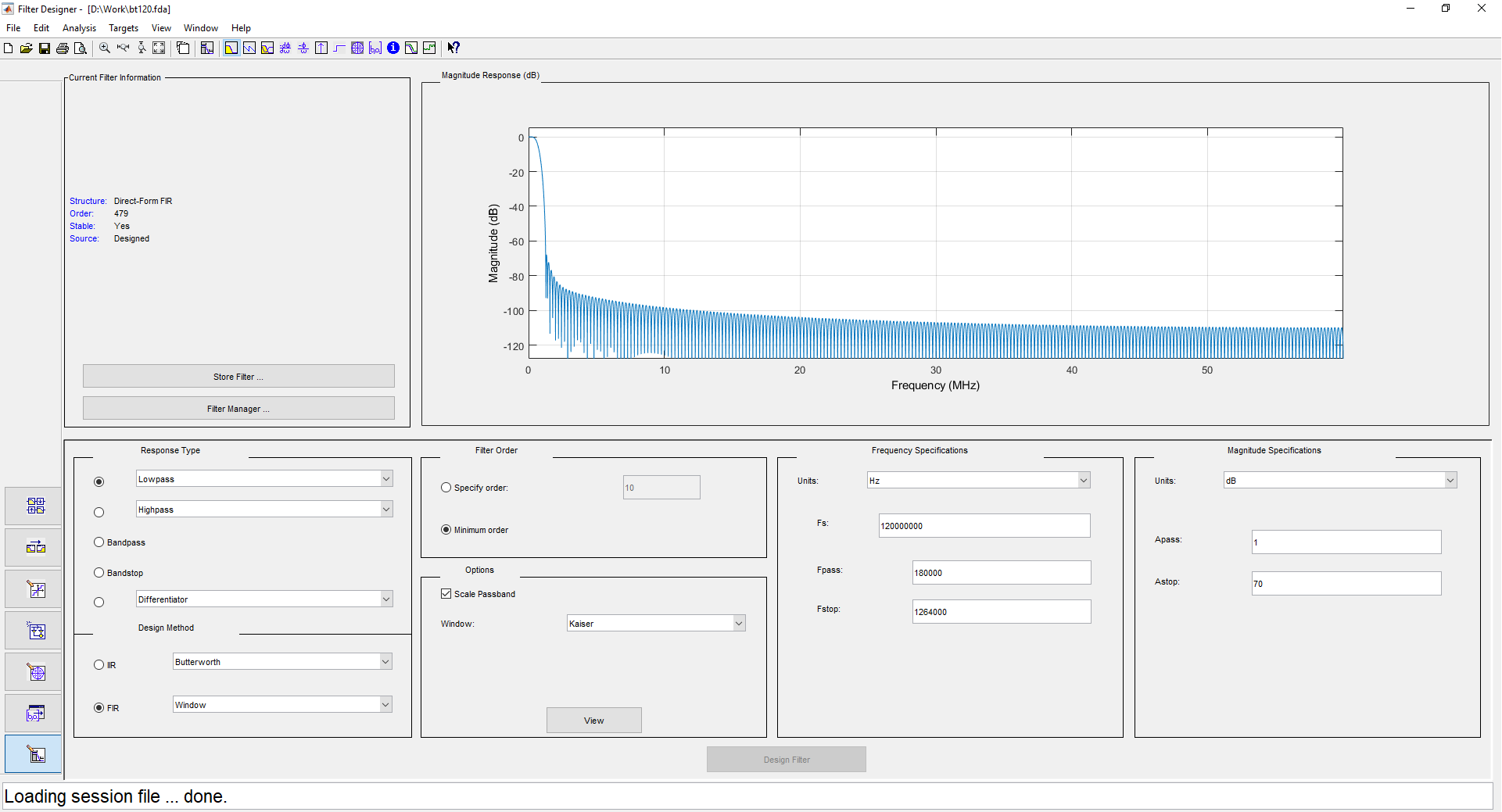
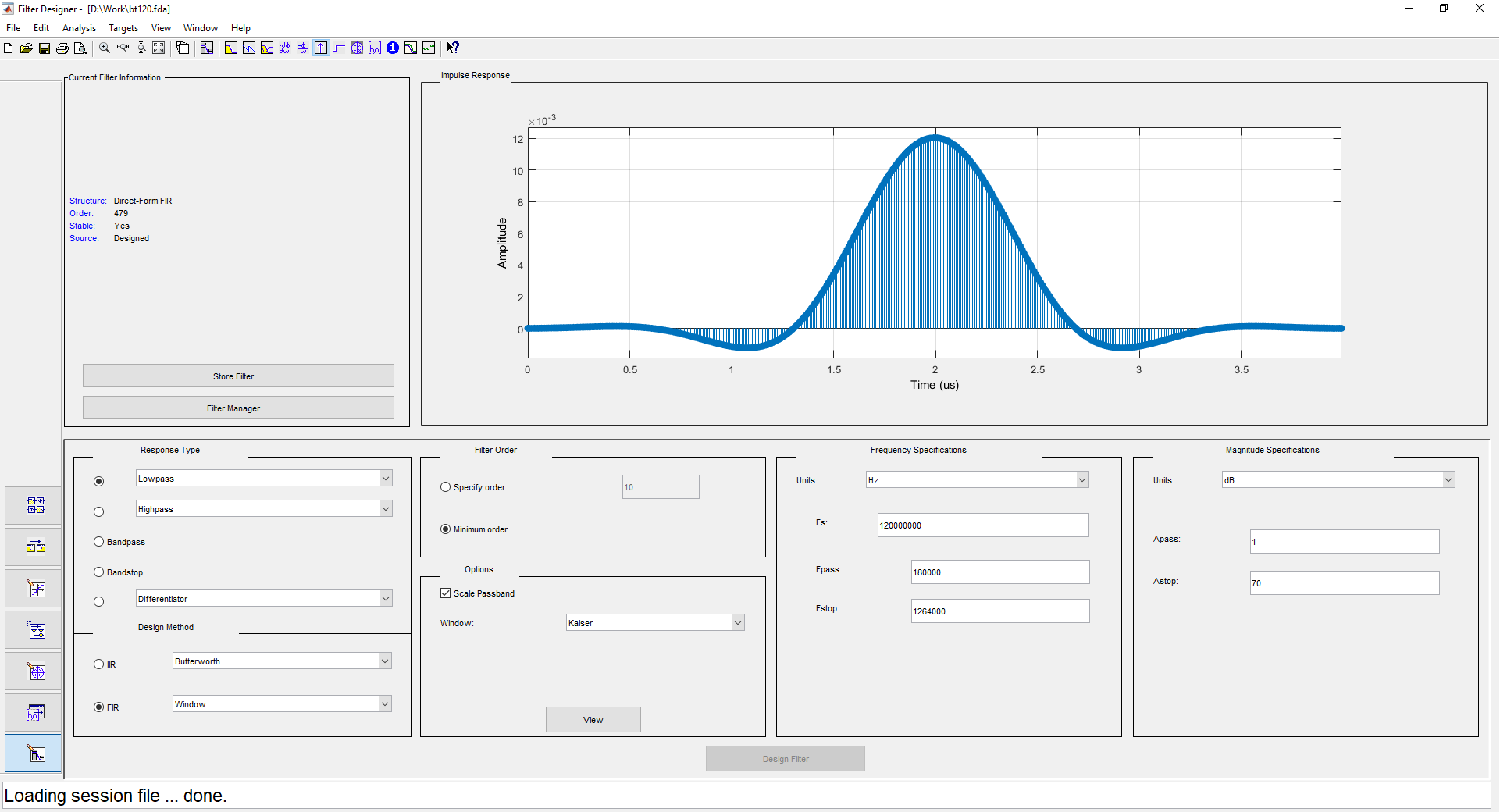
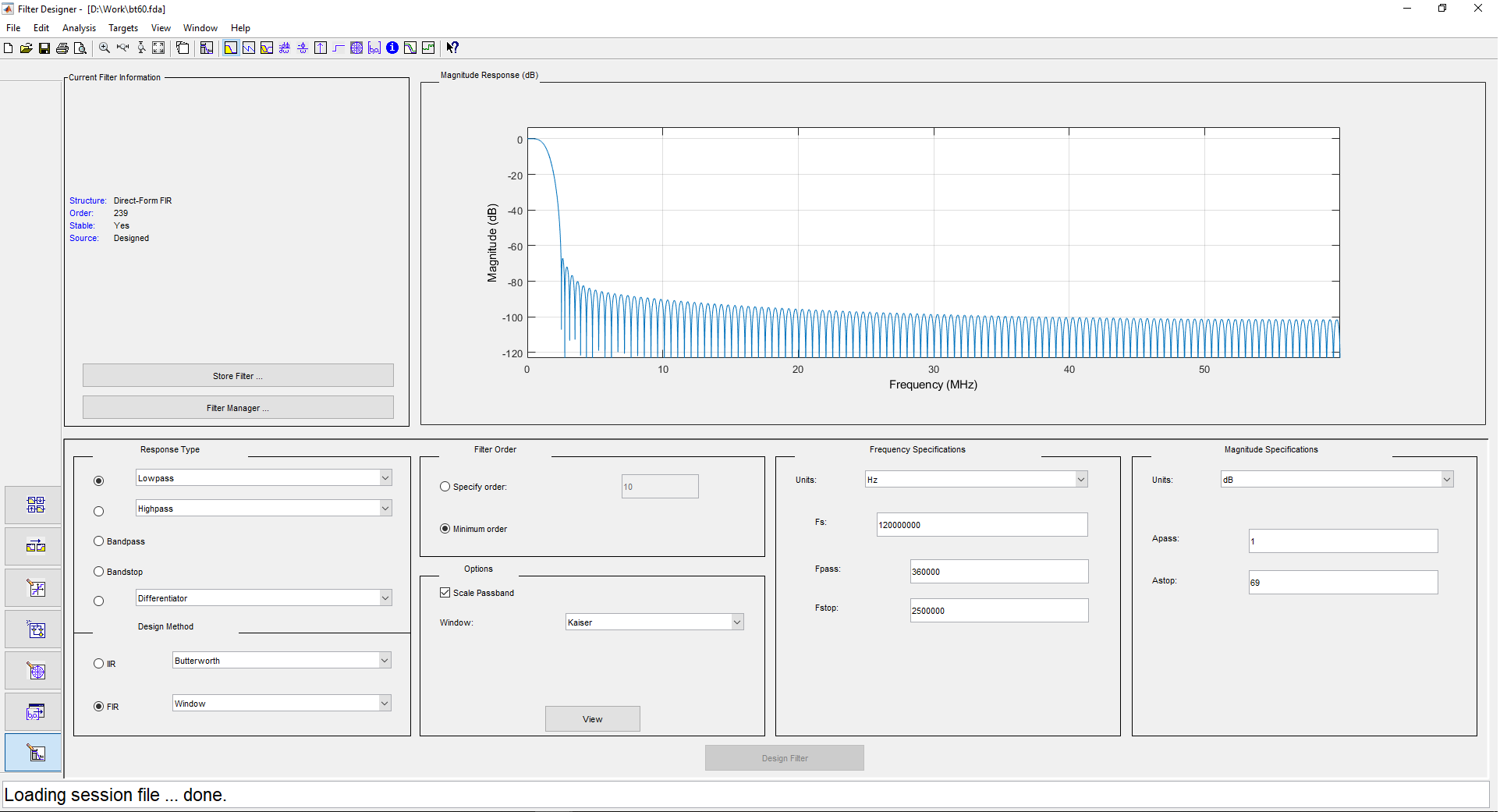
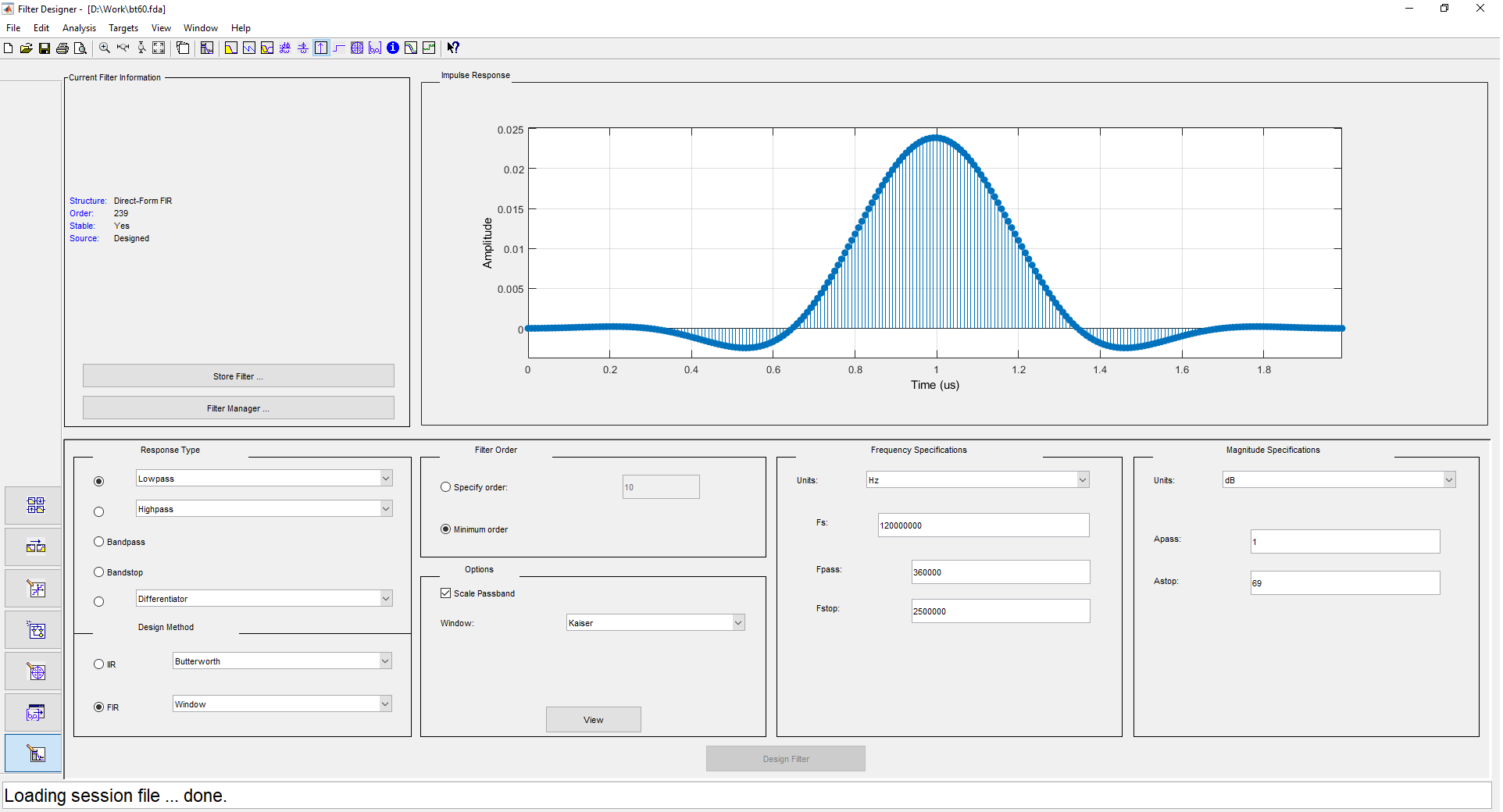
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
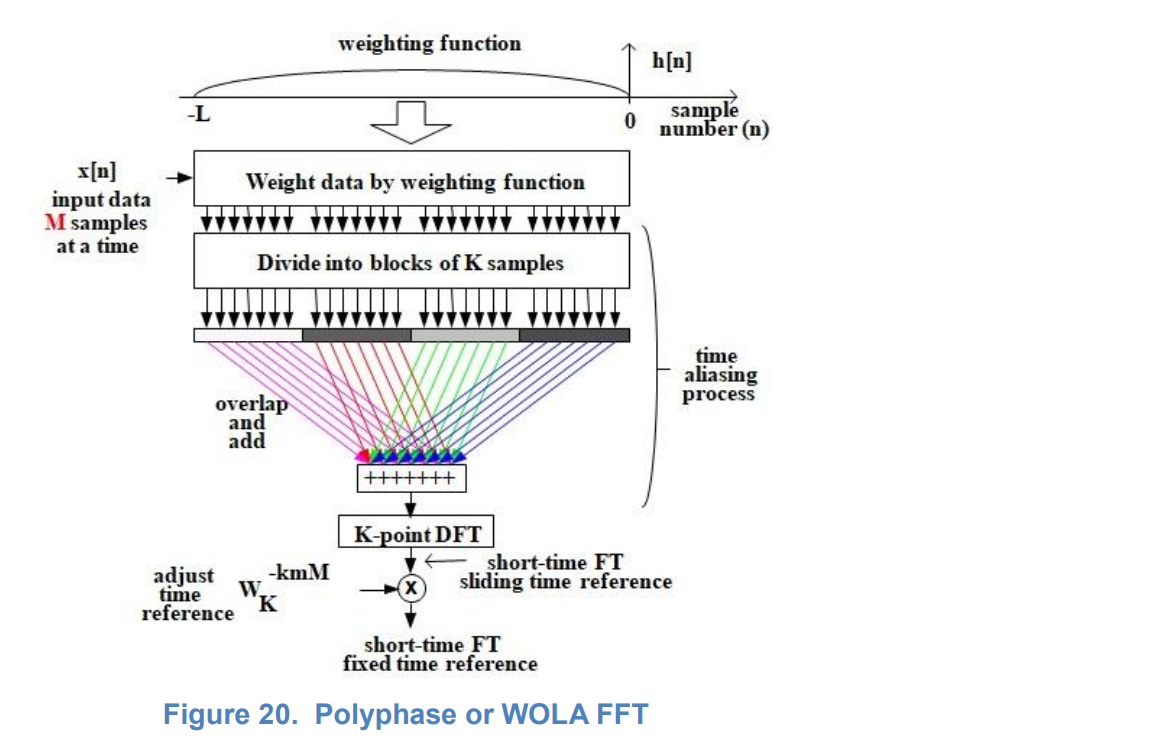
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
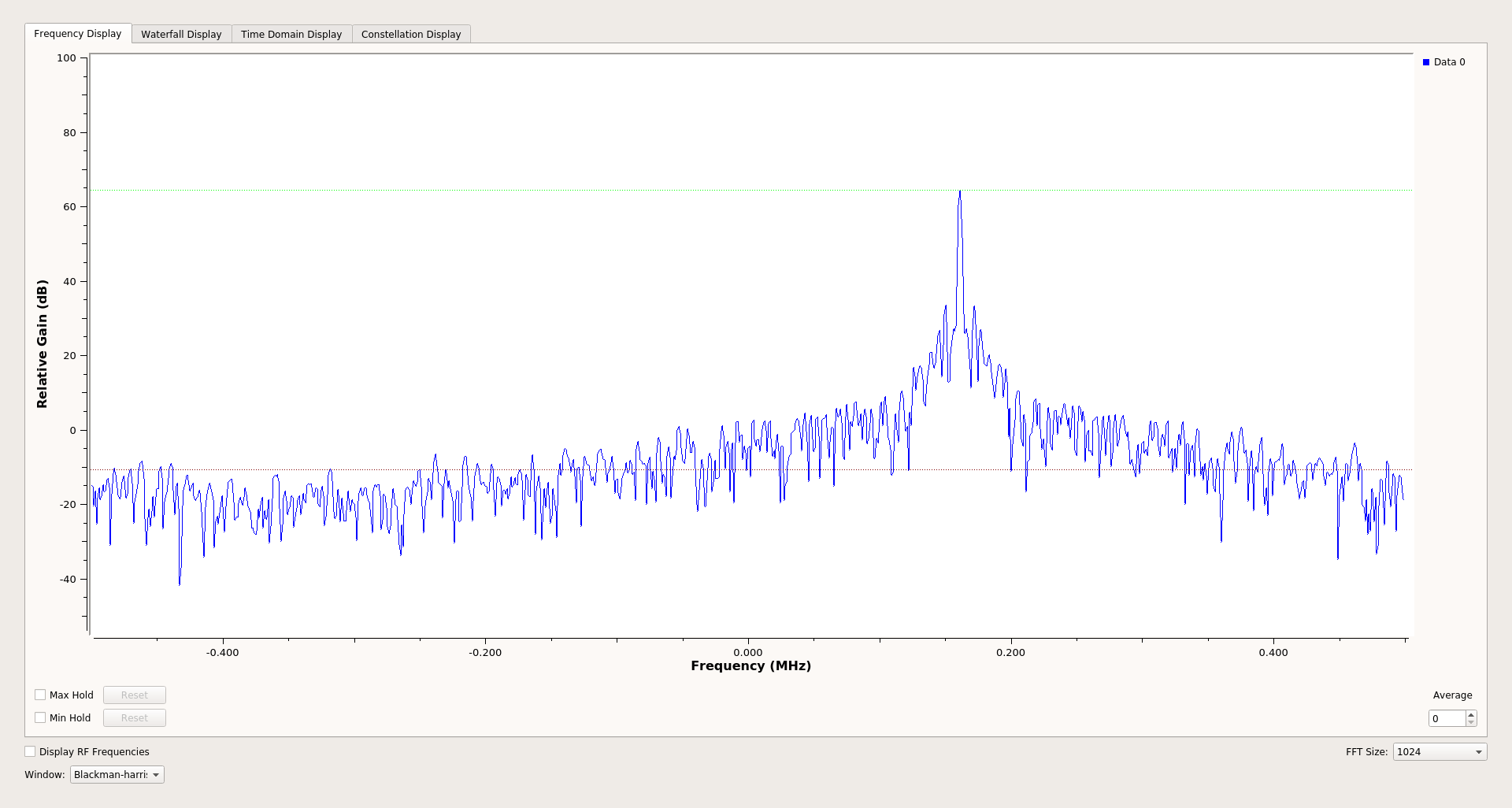
: XRTX , - .
gaudima, !