
مرحبا! تتعامل شركتنا مع مشكلة الحماية من هجمات DDoS لفترة طويلة ، وخلال هذا العمل تمكنت من التعرف على المجالات ذات الصلة بتفاصيل كافية - لدراسة مبادئ إنشاء الروبوتات وكيفية استخدامها. على وجه الخصوص ، تجريف الويب ، أي الجمع الجماعي للبيانات العامة من موارد الويب باستخدام برامج الروبوت.
في مرحلة ما ، أذهلني هذا الموضوع بمجموعة متنوعة من المشكلات التطبيقية التي يتم فيها استخدام الكشط بنجاح. وتجدر الإشارة هنا إلى أن "الجانب المظلم" من تجريف الويب هو الأكثر أهمية بالنسبة لي ، وهو السيناريوهات الضارة والسيئة لاستخدامه والآثار السلبية التي يمكن أن تحدثه على موارد الويب والأعمال المرتبطة بها.
في الوقت نفسه ، نظرًا لتفاصيل عملنا ، غالبًا ما كان في مثل هذه الحالات (السيئة) أن ننغمس في التفاصيل ، ودراسة التفاصيل المثيرة للاهتمام. وكانت نتيجة هذه الغوصات أن حماسي قد انتقل إلى زملائي - طبقنا حلنا للقبض على الروبوتات غير المرغوب فيها ، لكنني جمعت ما يكفي من القصص والملاحظات التي آمل أن تكون مادة ممتعة بالنسبة لك

سأتحدث عما يلي:
- لماذا يخدش الناس بعضهم البعض على الإطلاق؟
- ما هي أنواع وعلامات هذا الكشط؟
- ما هو تأثيرها على المواقع المستهدفة ؛
- ما هي الأدوات والقدرات التقنية التي يستخدمها منشئو الروبوتات للقيام بعملية الكشط ؛
- كيف يمكن اكتشاف فئات مختلفة من الروبوتات والتعرف عليها ؛
- ماذا تفعل وماذا تفعل إذا جاءت أداة الكشط لزيارة موقعك (وما إذا كنت بحاجة إلى فعل أي شيء على الإطلاق).
لنبدأ بسيناريو افتراضي غير ضار - دعنا نتخيل أنك طالب ، صباح الغد لديك دفاع عن ورقة المصطلح الخاص بك ، وليس لديك "حصان يرقد" بناءً على المواد ، ولا توجد أرقام ، ولا مقتطفات ، ولا اقتباسات - وأنت تدرك ذلك لبقية الليل ليس لديك الوقت ولا الطاقة ولا الرغبة في تجريف كل قاعدة المعرفة هذه يدويًا.
لذلك ، بناءً على نصيحة الرفاق الأكبر سنًا ، يمكنك اكتشاف سطر أوامر Python وكتابة نص برمجي بسيط يقبل عناوين URL كمدخلات ، أو الانتقال إلى هناك ، أو تحميل الصفحة ، أو تحليل المحتوى ، أو العثور على الكلمات الأساسية ، أو الكتل ، أو أرقام الاهتمام بها ، أو إضافتها إلى ملف ، أو في اللوحة ويستمر.
قم بتحميل العدد المطلوب من عناوين المنشورات العلمية والمنشورات عبر الإنترنت وموارد الأخبار في هذا البرنامج النصي - فهو يتخطى كل شيء بسرعة ، مع إضافة النتائج. كل ما عليك فعله هو رسم الرسوم البيانية والمخططات والجداول عليها - وفي صباح اليوم التالي ، مع ظهور الفائز ، تحصل على النقطة التي تستحقها.
دعنا نفكر في الأمر - هل فعلت شخصًا سيئًا في هذه العملية؟ حسنًا ، ما لم تحلل HTML بتعبير عادي ، فعلى الأرجح أنك لم تؤذي أي شخص ، بل وأكثر من ذلك للمواقع التي زرتها بهذه الطريقة. هذا نشاط لمرة واحدة ، ويمكن تسميته متواضعًا وغير واضح ، ولا يكاد أي شخص يعاني من حقيقة أنك أتيت ، فقد استحوذت بسرعة وبهدوء على قطعة البيانات التي تحتاجها.
من ناحية أخرى ، هل ستفعل ذلك مرة أخرى إذا نجح كل شيء في المرة الأولى؟ دعنا نواجه الأمر - على الأرجح ستفعل ، لأنك وفرت الكثير من الوقت والموارد ، بعد أن تلقيت ، على الأرجح ، بيانات أكثر مما كنت تعتقد في الأصل. ولا يقتصر هذا على البحث العلمي أو الأكاديمي أو التعليم العام.

لأن المعلومات تكلف مالاً ، والمعلومات التي يتم جمعها في الوقت المناسب تكلف أموالاً أكثر. هذا هو السبب في أن القشط هو مصدر دخل خطير لعدد كبير من الناس. هذا موضوع شائع للعمل المستقل: ادخل وشاهد مجموعة من الطلبات تطلب منك جمع بعض البيانات أو كتابة برنامج تجريف. هناك أيضًا منظمات تجارية تقوم بعمليات الكشط لطلب أو توفير منصات لهذا النشاط ، ما يسمى بالخدمية كخدمة. مثل هذا التنوع والانتشار ممكن ، أيضًا لأن التجريف في حد ذاته شيء غير قانوني ومستهجن وليس كذلك. من وجهة نظر قانونية ، من الصعب جدًا العثور على خطأ معه - خاصة في الوقت الحالي ، سنكتشف قريبًا السبب.

بالنسبة لي ، من الأمور ذات الأهمية الخاصة أيضًا حقيقة أنه من الناحية الفنية ، لا يمكن لأحد أن يمنعك من محاربة التجريف - وهذا يخلق موقفًا مثيرًا للاهتمام حيث تتاح للمشاركين في العملية على جانبي المتاريس الفرصة في مساحة عامة لمناقشة الجوانب الفنية والتنظيمية لهذه المسألة. للمضي قدمًا ، إلى حد ما ، في التفكير الهندسي وإشراك المزيد والمزيد من الأشخاص في هذه العملية.

من وجهة نظر الجوانب القانونية ، فإن الوضع الذي نفكر فيه الآن - مع جواز القشط ، لم يكن دائمًا كما كان من قبل. إذا نظرنا قليلاً إلى التسلسل الزمني للدعاوى القضائية المعروفة إلى حدٍ ما والمتعلقة بالكشط ، فسنرى أنه حتى فجر فجرها ، كان أول ادعاء لـ eBay ضد أداة جمع البيانات من المزادات ، ومنعته المحكمة من الانخراط في هذا النشاط. على مدار الخمسة عشر عامًا التالية ، تم الحفاظ على الوضع الراهن إلى حد ما - فازت الشركات الكبيرة بدعاوى قضائية ضد الكاشطات عندما اكتشفوا تأثيرهم. أبلغ كل من Facebook و Craigslist ، بالإضافة إلى العديد من الشركات الأخرى ، عن مزاعم انتهت لصالحهم.
ومع ذلك ، قبل عام ، تغير كل شيء فجأة. وجدت المحكمة أن دعوى LinkedIn ضد الشركة التي جمعت الملفات الشخصية العامة للمستخدمين والسيرة الذاتية لا أساس لها من الصحة وتجاهلت الرسائل والتهديدات التي تطالب بوقف النشاط. قضت المحكمة بأن جمع البيانات العامة ، بغض النظر عما إذا كان روبوتًا أو بشريًا ، لا يمكن أن يكون أساسًا لمطالبة من الشركة التي تعرض هذه البيانات العامة. لقد غيرت هذه السابقة القانونية القوية التوازن لصالح الكاشطات وسمحت لمزيد من الناس بإظهار وتوضيح ومحاولة مصلحتهم في هذا المجال.
ومع ذلك ، بالنظر إلى كل هذه الأشياء غير الضارة بشكل عام ، لا تنس أن الكشط له العديد من الاستخدامات السلبية - عندما يتم جمع البيانات ليس فقط للاستخدام الإضافي ، ولكن في العملية يتم تحقيق فكرة التسبب في أي ضرر للموقع أو العمل الذي يقف وراءها. أو محاولات إثراء أنفسهم بطريقة ما على حساب مستخدمي المورد المستهدف.
دعونا نلقي نظرة على بعض الأمثلة الشهيرة.

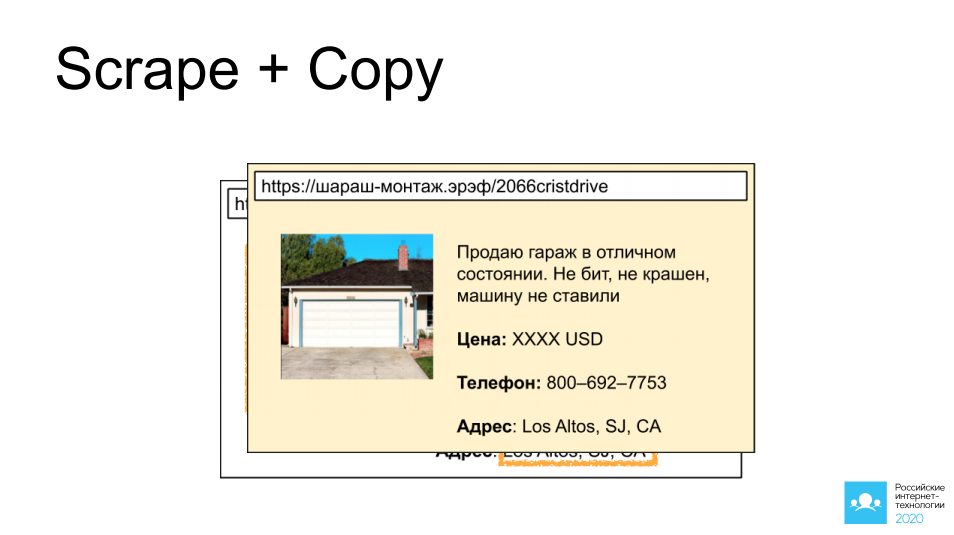
أولها كشط ونسخ إعلانات الآخرين من المواقع التي تتيح الوصول إلى مثل هذه الإعلانات: سيارات ، عقارات ، أغراض شخصية. اخترت مرآبًا رائعًا في كاليفورنيا كمثال. تخيل أننا وضعنا روبوتًا هناك ، وجمعنا صورة ، وجمعنا وصفًا ، وأخذنا جميع معلومات الاتصال ، وبعد 5 دقائق ، يُعلق الإعلان نفسه على موقع آخر له نفس التركيز ، ومن المحتمل جدًا أن تتم صفقة مربحة من خلاله.
إذا قمنا بتشغيل خيالنا قليلاً هنا وفكرنا في الجانب التالي - ماذا لو لم يكن منافسنا هو من يفعل ذلك ، بل مهاجم؟ يمكن أن تكون هذه النسخة من الموقع مفيدة جدًا ، على سبيل المثال ، لطلب دفعة مقدمة من الزائر ، أو ببساطة عرض إدخال تفاصيل بطاقة الدفع. يمكنك تخيل مزيد من التطوير للأحداث بنفسك.
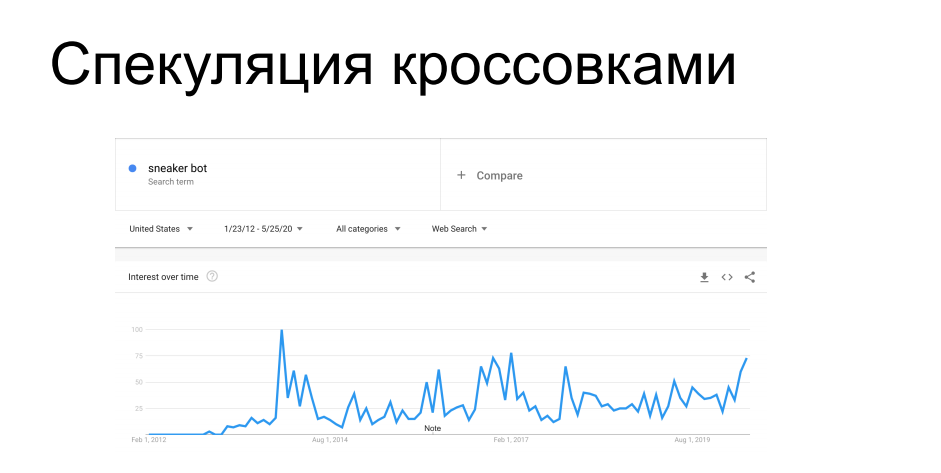
حالة أخرى مثيرة للاهتمام من التجريف هي شراء العناصر محدودة التوفر. يطلق مصنعو الأحذية الرياضية مثل Nike و Puma و Reebok دوريًا أحذية رياضية محدودة الإصدار ، إلخ. سلسلة التوقيع - يتم اصطيادهم من قبل هواة الجمع ، وهم معروضون للبيع لفترة محدودة. قبل المتسوقين ، تأتي الروبوتات تعمل على مواقع متاجر الأحذية وتنتشر في التداول بالكامل ، وبعد ذلك تظهر هذه الأحذية الرياضية في السوق الرمادية بسعر مختلف تمامًا. في وقت من الأوقات أغضبت البائعين وتجار التجزئة الذين يوزعونها. لمدة 7 سنوات كانوا يقاتلون ضد الكاشطات ، إلخ. بوتات أحذية رياضية متفاوتة النجاح ، سواء من الناحية الفنية أو الإدارية.

ربما تكون قد سمعت قصصًا عندما كان التسوق عبر الإنترنت مطلوبًا أن تأتي إلى متجر للأحذية الرياضية شخصيًا ، أو عن مواضع الجذب التي تحتوي على أحذية رياضية مقابل 100 ألف دولار ، والتي اشتراها الروبوت دون أن ينظر إليها ، وبعد ذلك أمسك صاحبها برأسه - كل هذه القصص في هذا الاتجاه.
وحالة أخرى مماثلة هي استنفاد المخزون في المتاجر عبر الإنترنت. إنه مشابه للسابق ، لكن لم يتم إجراء عمليات شراء فيه. يوجد متجر على الإنترنت ، وعناصر معينة من البضائع تدخلها الروبوتات الواردة في السلة بالكمية المعروضة على أنها متوفرة في المستودع. نتيجة لذلك ، يتلقى المستخدم الشرعي الذي يحاول شراء منتج رسالة مفادها أن هذه المقالة غير متوفرة ، ويخدش الجزء الخلفي من رأسه في الإحباط ويغادر إلى متجر آخر. ثم تقوم الروبوتات نفسها بإسقاط السلال المجمعة ، ويتم إرجاع البضائع إلى المجموعة - ويأتي الشخص الذي يحتاج إليها ويطلبها. أو لا يأتي ولا يأمر ، إذا كان هذا سيناريو لأذى تافه وشغب. من هذا يتضح أنه حتى لو لم تتسبب مثل هذه الأنشطة في ضرر مالي مباشر للأعمال التجارية عبر الإنترنت ، فعلى الأقل يمكن أن تعطل مقاييس العمل بشكل خطير ،الذي سيركز عليه المحللون. معلمات مثل التحويل ، والحضور ، والطلب على المنتج ، ومتوسط فحص عربة التسوق - ستكون جميعها ملطخة بشدة بإجراءات الروبوتات فيما يتعلق بهذه العناصر. وقبل أن يتم استخدام هذه المقاييس ، يجب تنظيفها بعناية وبعناء من آثار الكاشطات.
بالإضافة إلى هذا التركيز على الأعمال التجارية ، هناك تأثيرات تقنية ملحوظة جدًا تنشأ من عمل الكاشطات - في أغلب الأحيان عند إجراء الكشط بشكل نشط ومكثف.
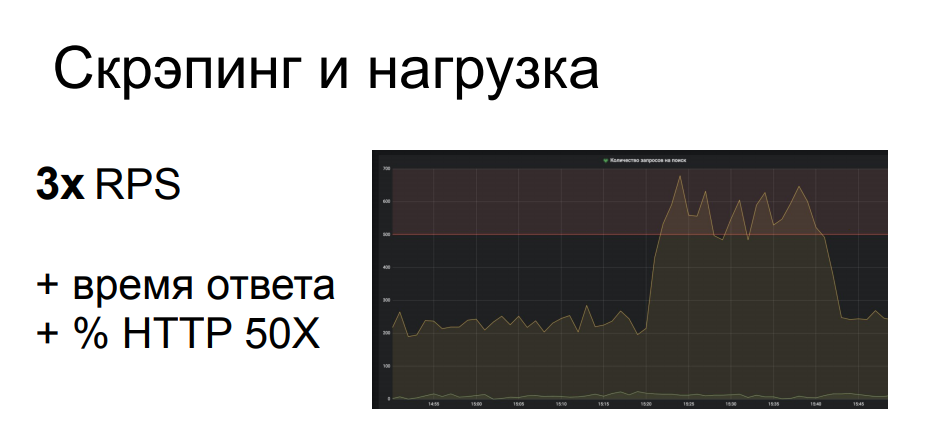
أحد الأمثلة لدينا من أحد عملائنا. وصلت أداة الكشط إلى موقع ببحث ذي معلمات ، وهي واحدة من أصعب العمليات في الواجهة الخلفية للهيكل المعني. كان على الكاشطة أن تفرز عددًا كبيرًا جدًا من استعلامات البحث ، ومن أصل 200 RPS لهذا الموقع ، قام بما يقرب من 700. هذا الجزء المحمّل بشكل خطير من البنية التحتية ، مما أدى إلى تدهور جودة الخدمة لبقية المستخدمين الشرعيين ، وانطلق وقت الاستجابة ، وانخفض 502 و 503. والأخطاء. بشكل عام ، لم يهتم الكاشطة على الإطلاق وجلس وقام بعمله بينما قام الجميع بتحديث صفحة المتصفح بشكل محموم.
من هذا يتضح أن مثل هذا النشاط قد يصنف على أنه هجوم DDoS مطبق - وغالبًا ما يحدث. خاصة إذا لم يكن المتجر عبر الإنترنت كبيرًا جدًا ، فإنه لا يحتوي على بنية تحتية يتم حجزها بشكل متكرر من حيث الأداء والموقع. قد يكون مثل هذا النشاط جيدًا ، إذا لم تضع المورد بالكامل - فهو ليس مربحًا جدًا للكاشطة ، لأنه في هذه الحالة لن يتلقى بياناته - عندئذٍ تجعل جميع المستخدمين الآخرين منزعجين بشكل خطير.
ولكن إلى جانب DDoS ، فإن التجريف له أيضًا جيران مثيرون للاهتمام في الجرائم الإلكترونية. على سبيل المثال ، تستخدم عمليات تسجيل الدخول باستخدام القوة الغاشمة وكلمات المرور قاعدة تقنية مماثلة ، أي باستخدام نفس البرامج النصية ، يمكن إجراؤها مع التركيز على السرعة والأداء. لحشو بيانات الاعتماد ، يتم استخدام بيانات المستخدم التي تم إلغاؤها من مكان ما ، والتي يتم دفعها إلى حقول النموذج. حسنًا ، هذا المثال لنسخ المحتوى ونشره على مواقع مماثلة هو عمل تحضيري جاد لتخطي روابط التصيد الاحتيالي وجذب المشترين المطمئنين.

لفهم كيف يمكن أن تؤثر المتغيرات المختلفة من الكشط ، من وجهة نظر فنية ، على المورد ، دعنا نحاول حساب مساهمة العوامل الفردية في هذه المهمة. لنقم ببعض العمليات الحسابية.

لنفترض أن لدينا مجموعة من البيانات على اليمين نحتاج إلى جمعها. لدينا مهمة أو طلب لاسترداد 10000000 سطر من عناصر السلع ، على سبيل المثال علامات الأسعار أو عروض الأسعار. وعلى الجانب الأيسر ، لدينا ميزانية زمنية ، لأنه غدًا أو بعد أسبوع لن يحتاج العميل إلى هذه البيانات - ستصبح قديمة وسيتعين جمعها مرة أخرى. لذلك ، تحتاج إلى الالتزام بإطار زمني معين ، واستخدام مواردك الخاصة ، قم بذلك بالطريقة المثلى. لدينا عدد من الخوادم - الآلات وعناوين IP التي توجد خلفها ، والتي من خلالها سننتقل إلى المورد الذي يهمنا. لدينا عدد من حالات المستخدم التي نتظاهر بوجودها - هناك مهمة لإقناع متجر عبر الإنترنت أو قاعدة عامة أن هؤلاء أشخاص مختلفون أو أجهزة كمبيوتر مختلفة يذهبون لبعض البيانات ، بحيثمن سيحلل السجلات ، لم يكن هناك شك. ولدينا بعض الأداء ، معدل الطلب ، من مثال واحد.
من الواضح أنه في حالة بسيطة - جهاز مضيف واحد ، طالب لديه جهاز كمبيوتر محمول ، يمر عبر الواشنطن بوست ، سيتم تقديم عدد كبير من الطلبات بنفس العلامات والمعايير. سيكون هذا ملحوظًا جدًا في السجلات ، إذا كان هناك الكثير من هذه الطلبات - مما يعني أنه من السهل العثور على عنوان IP وحظره في هذه الحالة.
نظرًا لأن البنية التحتية للتخليص تصبح أكثر تعقيدًا ، يظهر عدد أكبر من عناوين IP ، ويبدأ استخدام الوكلاء ، بما في ذلك الوكلاء المنزليون - المزيد عنها لاحقًا. ونبدأ في إجراء عمليات متعددة على كل جهاز - لاستبدال معاملات الاستعلام ، العلامات التي تميزنا ، من أجل جعل كل شيء يشوه في السجلات ولا يكون واضحًا جدًا.
إذا استمررنا في نفس الاتجاه ، فستتاح لنا الفرصة ، في إطار نفس المعادلة ، لتقليل كثافة الطلبات من كل حالة - مما يجعلها أكثر ندرة ، وتناوبها بشكل أكثر كفاءة بحيث لا تنتهي الطلبات الواردة من نفس المستخدمين في السجلات القريبة. دون إثارة الشكوك والتشابه مع المستخدمين النهائيين (الشرعيين).
حسنًا ، هناك حالة متطرفة - لقد كانت لدينا مثل هذه الحالة في الممارسة العملية ، عندما أتى مكشطة إلى عميل من عدد كبير من عناوين IP بسمات مستخدم مختلفة تمامًا وراء هذه العناوين ، وقدم كل مثيل طلبًا واحدًا بالضبط للمحتوى. لقد قمت بعمل GET لصفحة المنتج المطلوبة ، وقمت بتحليلها وغادرت - ولم تظهر مرة أخرى. مثل هذه الحالات نادرة جدًا ، لأنها تتطلب المزيد من الموارد (التي تكلف المال) لاستخدامها في نفس الفترة الزمنية. لكن في الوقت نفسه ، يصبح من الصعب تعقبهم وفهم أن شخصًا ما قد جاء إلى هنا وقام بتقطيعهم. تصبح أدوات البحث عن حركة المرور مثل التحليل السلوكي - بناء نمط سلوك مستخدم معين - معقدة للغاية. بعد كل شيء ، كيف يمكنك إجراء تحليل سلوكي إذا لم يكن هناك سلوك؟ لا يوجد سجل لإجراءات المستخدم ،لم يظهر من قبل ، ومن المثير للاهتمام أنه لم يأت مرة أخرى منذ ذلك الحين. في مثل هذه الظروف ، إذا لم نحاول القيام بشيء ما عند الطلب الأول ، فسوف تتلقى بياناتها وتغادر ، ولن يتبقى لنا أي شيء - لم نحل مشكلة مواجهة التجريف هنا. لذلك ، فإن الفرصة الوحيدة هي التخمين عند الطلب الأول أن الشخص الخطأ قد جاء ، والذي نريد رؤيته على الموقع ، وإعطائه خطأ أو التأكد من أنه لا يتلقى بياناته.من نريد رؤيته على الموقع ، وإعطائه خطأ أو التأكد من عدم استلامه لبياناته.من نريد رؤيته على الموقع ، وإعطائه خطأ أو التأكد من عدم استلامه لبياناته.
لفهم كيف يمكنك التحرك على هذا النطاق من التعقيد في بناء مكشطة ، دعنا نلقي نظرة على الترسانة التي يمتلكها منشئو الروبوت والتي يتم استخدامها غالبًا - وما هي الفئات التي يمكن تقسيمها إلى.

الفئة الأساسية والأبسط التي يعرفها معظم القراء هي تجريف النص ، واستخدام نصوص بسيطة بما يكفي لحل المشكلات المعقدة نسبيًا.

وربما تكون هذه الفئة هي الأكثر شهرة وتوثيقًا. من الصعب حتى التوصية بما تقرأه بالضبط ، لأنه في الواقع ، هناك الكثير من المواد. تمت كتابة الكثير من الكتب بهذه الطريقة ، وهناك الكثير من المقالات والمنشورات - من حيث المبدأ ، يكفي قضاء 5/4/3/2 دقيقة (اعتمادًا على وقاحة مؤلف المادة) لتحليل موقعك الأول. هذه خطوة أولى منطقية للعديد من الذين بدأوا في تجريف الويب. غالبًا ما تكون "حزمة البداية" لمثل هذا النشاط هي Python ، بالإضافة إلى مكتبة يمكنها إجراء الطلبات بمرونة وتغيير معلماتها ، مثل الطلبات أو urllib2. ونوع من محلل HTML ، وغالبًا ما يكون حساءًا جميلًا. هناك أيضًا خيار لاستخدام libs التي تم إنشاؤها خصيصًا للكشط ، مثل scrapy ، والتي تتضمن كل هذه الوظائف بواجهة سهلة الاستخدام.
بمساعدة الحيل البسيطة ، يمكنك التظاهر بأنك أجهزة مختلفة ، ومستخدمون مختلفون ، حتى دون أن تكون قادرًا على توسيع نطاق أنشطتك بطريقة ما حسب الأجهزة وعناوين IP ومنصات الأجهزة المختلفة.

من أجل التخلص من رائحة الشخص الذي يتفقد السجلات على جانب الخادم الذي يتم جمع البيانات منه ، يكفي استبدال المعلمات المهمة - وهذا ليس بالأمر الصعب وليس لفترة طويلة. لنلقِ نظرة على مثال لتنسيق سجل مخصص لـ nginx - نسجل عنوان IP ومعلومات TLS والرؤوس التي تهمنا. هنا ، بالطبع ، ليس كل شيء يتم جمعه عادةً ، لكننا نحتاج إلى هذا التقييد كمثال - للنظر إلى مجموعة فرعية ، ببساطة لأن كل شيء آخر أسهل في "رمي".
لكي لا يتم حظرنا عن طريق العناوين ، سنستخدم وكلاء محليين ، كما يطلق عليهم في الخارج - أي ، وكلاء من أجهزة مستأجرة (أو مخترقة) في الشبكات المنزلية لمقدمي الخدمة. من الواضح أنه من خلال حظر عنوان IP هذا ، هناك فرصة لحظر عدد معين من المستخدمين الذين يعيشون في هذه المنازل - وقد يكون هناك زوار لموقعك ، لذلك في بعض الأحيان يكون القيام بذلك أكثر تكلفة بالنسبة لك.
ليس من الصعب أيضًا تغيير معلومات TLS - خذ مجموعات التشفير للمتصفحات الشائعة واختر ما تفضله - الأكثر شيوعًا ، أو قم بتدويرها بشكل دوري لتقديم نفسها كأجهزة مختلفة.
أما بالنسبة للرؤوس ، فبمساعدة القليل من الدراسة ، يمكنك تعيين المُحيل إلى ما يحبه الموقع المسروق ، ونأخذ وكيل المستخدم من Chrome ، أو Firefox ، بحيث لا يختلف بأي شكل عن عشرات الآلاف من المستخدمين الآخرين.
بعد ذلك ، من خلال التلاعب بهذه المعلمات ، يمكنك التظاهر بأنك أجهزة مختلفة وتستمر في التجريف دون الخوف من أن يتم ملاحظتك بطريقة أو بأخرى للعين المجردة التي تسير عبر السجلات. بالنسبة للعين المسلحة ، لا يزال هذا الأمر أكثر صعوبة إلى حد ما ، لأن مثل هذه الحيل البسيطة يتم تحييدها بنفس الإجراءات المضادة البسيطة إلى حد ما.

تتيح لك مقارنة معلمات الطلب والرؤوس وعناوين IP مع بعضها البعض ومع تلك المعروفة للجمهور التقاط أكثر أدوات الكشط غطرسة. مثال بسيط - جاء إلينا روبوت بحث ، ولكن لسبب ما لم يكن عنوان IP الخاص به من شبكة محرك البحث ، ولكن من مزود خدمة سحابية. حتى Google نفسها على الصفحة التي تصف Googlebot توصي بإجراء بحث عكسي عن سجلات DNS من أجل التأكد من أن هذا الروبوت جاء بالفعل من google.com أو من موارد Google الصالحة الأخرى.
هناك العديد من هذه الشيكات ، وغالبًا ما تكون مصممة لأولئك الذين لا يهتمون بالضيق ، نوع من الاستبدال. للحالات الأكثر تعقيدًا ، هناك طرق أكثر موثوقية وأثقل ، على سبيل المثال ، انزلاق Javascript على هذا الروبوت. من الواضح أنه في مثل هذه الظروف يكون الصراع غير متكافئ بالفعل - لن يكون نص بايثون الخاص بك قادرًا على تنفيذ وتفسير كود JS. ولكن يمكن أن يتم ذلك بواسطة مؤلف البرنامج النصي - إذا كان لدى مؤلف الروبوت الوقت والرغبة والموارد والمهارة الكافية للذهاب ومعرفة ما تفعله Javascript في المتصفح.
يتمثل جوهر عمليات التحقق في أنك تقوم بدمج النص في صفحتك ، ومن المهم بالنسبة لك ليس فقط أن يتم تنفيذه - ولكن أيضًا أنه يوضح نوعًا من النتائج ، والتي يتم عادةً إرسالها بالبريد POST إلى الخادم قبل أن يحصل العميل على قسط كافٍ من النوم المحتوى ، وسيتم تحميل الصفحة نفسها. لذلك ، إذا قام مؤلف الروبوت بحل اللغز الخاص بك والأكواد الثابتة الإجابات الصحيحة في نص Python الخاص به ، أو ، على سبيل المثال ، يفهم أين يحتاج إلى تحليل أسطر البرنامج النصي نفسه بحثًا عن المعلمات الضرورية والأساليب المسماة ، وسيقوم بحساب الإجابة بمفرده ، فسيكون قادرًا على وضع دائرة حولك حول إصبعك. هنا مثال.

أعتقد أن بعض المستمعين سيتعرفون على هذا الجزء من جافا سكريبت - هذا هو التحقق الذي اعتاد أحد أكبر مزودي الخدمات السحابية في العالم على إجرائه قبل الوصول إلى الصفحة المطلوبة ، مضغوطًا وبسيطًا للغاية ، وفي نفس الوقت ، دون تعلمه ، من السهل جدًا الموقع لا يخترق. في الوقت نفسه ، بعد بذل القليل من الجهد ، يمكننا أن نسأل الصفحة بحثًا عن طرق JS التي تهمنا والتي سيتم استدعاؤها ، منها ، العد ، والعثور على القيم التي تهمنا والتي يجب حسابها ، وإلصاق الحسابات في الكود. بعد ذلك ، لا تنسى النوم لبضع ثوان بسبب التأخير ، وفويلا.

وصلنا إلى الصفحة ومن ثم يمكننا تحليل ما نحتاج إليه ، مع عدم إنفاق موارد أكثر من إنشاء مكشطة خاصة بنا. أي ، من وجهة نظر استخدام الموارد ، لا نحتاج إلى أي شيء إضافي لحل مثل هذه المشاكل. من الواضح أن سباق التسلح في هذا السياق - كتابة تحديات JS وتحليلها والالتفاف عليها بواسطة أدوات طرف ثالث - يقتصر فقط على وقت ورغبة ومهارات مؤلف الروبوتات ومؤلف الشيكات. يمكن أن يستمر هذا السباق لفترة طويلة ، ولكن في مرحلة ما تصبح معظم أدوات الكشط غير مثيرة للاهتمام ، لأن هناك خيارات أكثر إثارة للاهتمام للتعامل معها. لماذا تجلس وتحلل كود JS في Python بينما يمكنك فقط الحصول على متصفح وتشغيله؟

نعم ، أنا أتحدث بشكل أساسي عن المتصفحات الخالية من الرأس ، لأن هذه الأداة ، التي تم إنشاؤها في الأصل للاختبار والأسئلة والأجوبة ، أصبحت مثالية لمهام تجريف الويب في الوقت الحالي.
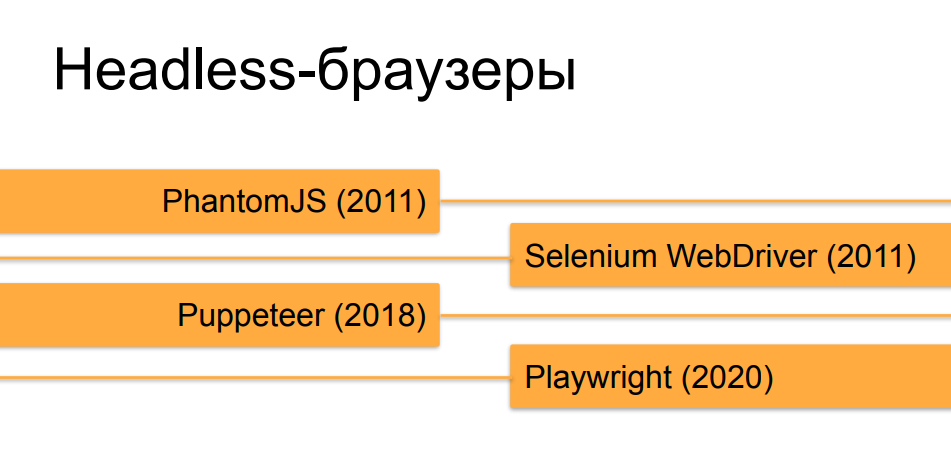
لن ندخل في تفاصيل حول المتصفحات بدون رأس ، أعتقد أن معظم المستمعين يعرفون عنها بالفعل. خضع Orchestrators ، الذين يقومون بأتمتة المتصفحات بدون رأس ، لتطور سريع للغاية على مدار السنوات العشر الماضية. في البداية ، في وقت PhantomJS والإصدارات الأولى من Selenium 2.0 و Selenium WebDriver ، لم يكن من الصعب على الإطلاق تمييز متصفح بدون رأس يعمل تحت جهاز آلي عن المستخدم المباشر. ولكن ، بمرور الوقت وظهور أدوات مثل Puppeteer لمتصفح Chrome بدون رأس والآن ، إنشاء السادة من Microsoft - Playwright ، الذي يفعل نفس الشيء مثل Puppeteer ، ولكن ليس فقط لمتصفح Chrome ، ولكن لجميع إصدارات المتصفحات الشائعة ، فهي أكثر وأكثر وتقريب المتصفحات بدون رأس من المتصفحات الحقيقية من حيثكيف يمكن صنعها بمساعدة تنسيق مماثل في السلوك وفي علامات وخصائص مختلفة لمتصفح الشخص السليم.

من أجل التعامل مع التعرف بدون رأس على خلفية المتصفحات العادية التي يجلس عليها الناس ، كقاعدة عامة ، يتم استخدام نفس عمليات التحقق من جافا سكريبت ، ولكن بشكل أعمق وتفصيلي يجمع سحابة من المعلمات. يتم إرسال نتيجة هذه المجموعة إما إلى أداة الحماية أو إلى الموقع الذي أرادت أداة الكشط جمع البيانات منه. تسمى هذه التقنية بالبصمة لأنها تجمع بصمة رقمية حقيقية للمتصفح والجهاز الذي يعمل عليه.
هناك عدد غير قليل من الأشياء التي يتحقق منها JS عند النظر في بصمات الأصابع - يمكن تقسيمها إلى بعض الكتل الشرطية ، حيث يمكن أن يستمر الحفر في كل منها. هناك بالفعل الكثير من الخصائص ، بعضها يسهل إخفاءه ، والبعض الآخر أقل سهولة. وهنا ، كما في المثال السابق ، يعتمد الكثير على مدى دقة تعامل الكاشطة مع مهمة إخفاء "ذيول" الجاحظ من انعدام الرأس. هناك خصائص للكائنات في المتصفح ، والتي يستبدلها المنسق افتراضيًا ، هناك الخاصية ذاتها (navigator.webdriver) ، والتي يتم تعيينها بدون رأس ، ولكنها في الوقت نفسه غير موجودة في المتصفحات العادية. يمكن إخفاؤها ، ويمكن الكشف عن محاولة الإخفاء عن طريق التحقق من طرق معينة - يمكن أيضًا إخفاء ما يتحقق من هذه الفحوصات وإخراج الإخراج الوهمي إلى وظائف تقوم بطرق الطباعة ، على سبيل المثال ،ويمكن أن تستمر إلى أجل غير مسمى.
مجموعة أخرى من الشيكات ، كقاعدة عامة ، هي المسؤولة عن دراسة معلمات النافذة والشاشة ، والتي لا تحتوي على متصفحات بدون رأس: التحقق من الإحداثيات ، والتحقق من الأحجام ، وما هو حجم الصورة المكسورة التي لم يتم رسمها. هناك الكثير من الفروق الدقيقة التي يمكن لأي شخص يعرف جهاز المتصفحات جيدًا أن يتنبأ بها ويتخلى عن نتيجة معقولة (ولكن ليست حقيقية) لكل منها ، والتي ستنتقل بعيدًا في فحوصات بصمات الأصابع إلى الخادم الذي سيحللها. على سبيل المثال ، في حالة عرض بعض الصور ، ثنائية وثلاثية الأبعاد ، عن طريق WebGL و Canvas ، يمكنك تجهيز المخرجات بالكامل بالكامل ، وتزويرها ، وإصدارها بطريقة ما ، وجعل شخص ما يعتقد أن شيئًا ما مرسوم بالفعل.
هناك المزيد من عمليات التحقق الصعبة التي لا تحدث في وقت واحد ، ولكن لنفترض أن كود JS سوف يدور لعدد معين من الثواني على الصفحة ، أو أنه سيتوقف باستمرار وينقل بعض المعلومات إلى الخادم من المتصفح. على سبيل المثال ، تتبع موضع وسرعة حركة المؤشر - إذا نقر الروبوت فقط في الأماكن التي يحتاجها ويتبع الروابط بسرعة الضوء ، فيمكن تتبع ذلك من خلال حركة المؤشر ، إذا كان مؤلف الروبوت لا يفكر في تسجيل شيء يشبه الإنسان ، على نحو سلس ، عوض.
وهناك غابة تمامًا - فهذه معلمات خاصة بالإصدار وخصائص لنموذج الكائن ، وهي محددة من متصفح إلى آخر ، ومن إصدار إلى آخر. ولكي تعمل هذه الفحوصات بشكل صحيح ولا يتم تزويرها ، على سبيل المثال ، على المستخدمين المباشرين الذين يستخدمون بعض المتصفحات القديمة ، يجب أن تأخذ في الاعتبار مجموعة من الأشياء. أولاً ، تحتاج إلى مواكبة إصدار الإصدارات الجديدة ، وتعديل الشيكات الخاصة بك بحيث تأخذ في الاعتبار حالة الأمور على الجبهات. من الضروري الحفاظ على التوافق مع الإصدارات السابقة بحيث يمكن لشخص ما أن يأتي إلى موقع محمي بواسطة مثل هذه الفحوصات على متصفح غير نمطي وفي نفس الوقت لا يتم اكتشافه مثل الروبوت والعديد من الآخرين.
هذا عمل شاق ومعقد إلى حد ما - عادة ما يتم تنفيذ مثل هذه الأشياء من قبل الشركات التي توفر اكتشاف الروبوتات كخدمة ، والقيام بذلك بمفردها بموردها الخاص ليس استثمارًا مربحًا للغاية للوقت والمال.
ولكن ما يجب فعله - نحتاج حقًا إلى التخلص من الموقع ، معلقًا بسحابة من فحوصات الرأس هذه وحساب بعض الكروم مقطوع الرأس مع محرك الدمى ، على الرغم من كل شيء ، بغض النظر عن مدى صعوبة المحاولة.
استطراد غنائي صغير - بالنسبة لأولئك الذين يرغبون في القراءة بمزيد من التفاصيل حول تاريخ وتطور الشيكات ، على سبيل المثال ، من أجل بلا رأس Chrome ، هناك مبارزة رسائلي مضحكة بين مؤلفين. لا أعرف الكثير عن أحد المؤلفين ، والآخر يُدعى أنطوان فاستل ، وهو شاب من فرنسا يحتفظ بمدونة حول الروبوتات واكتشافها والتعتيم على عمليات التحقق والعديد من الأشياء الأخرى المثيرة للاهتمام. ولذلك ظلوا ونظرائهم يتجادلون لمدة عامين حول ما إذا كان من الممكن اكتشاف Chrome مقطوع الرأس.
وسنمضي قدمًا ونفهم ما يجب فعله إذا لم نتمكن من اجتياز الفحوصات بدون رأس.

هذا يعني أننا لن نستخدم متصفحات بلا رأس ، ولكننا سنستخدم متصفحات حقيقية كبيرة ترسم لنا النوافذ وجميع أنواع العناصر المرئية. تسمح أدوات مثل Puppeteer و Playwright ، بدلاً من بدون رأس ، بتشغيل المتصفحات بشاشة معروضة ، وقراءة مدخلات المستخدم من هناك ، والتقاط لقطات شاشة ، وغير ذلك الكثير الذي لا يتوفر للمتصفحات التي لا تحتوي على مكون مرئي.

بالإضافة إلى تجاوز عمليات التحقق من عدم الرأس ، في هذه الحالة ، يمكنك أيضًا التعامل مع المشكلة التالية - عندما يكون لدينا بعض منشئي المواقع الماكرة ، نختبئ من النص في الصور ، ونجعلها غير مرئية دون إجراء نقرات إضافية أو بعض الإجراءات والحركات الأخرى. إنهم يخفون بعض العناصر التي يجب إخفاؤها ، والتي تظهر بلا رأس: لا يعرفون أن هذا العنصر لا يجب عرضه على الشاشة الآن ، ويصادفونه. يمكننا ببساطة رسم هذه الصورة في المتصفح ، وإدخال لقطة الشاشة إلى OCR ، والحصول على النص في الإخراج واستخدامه. نعم ، إنه أصعب ، وأكثر تكلفة من حيث التنمية ، ويستغرق وقتًا أطول ويستهلك المزيد من الموارد. لكن هناك كاشطات تعمل بهذه الطريقة ، وعلى حساب السرعة والأداء ، فإنها تجمع البيانات بهذه الطريقة.

"ماذا عن CAPTCHA؟" - أنت تسأل. بعد كل شيء ، لا يمكن حل captcha (المتقدم) OCR بدون بعض الأشياء الأكثر تعقيدًا. هناك إجابة بسيطة على هذا - إذا لم نتمكن من حل captcha تلقائيًا ، فلماذا لا نستخدم العمالة البشرية؟ لماذا تفصل بين الروبوت والإنسان عندما يمكنك الجمع بين عملهما لتحقيق هدف ما؟
هناك خدمات تتيح لك إرسال كلمة التحقق (captcha) إليهم ، حيث يتم حلها بواسطة أيدي الأشخاص الجالسين أمام الشاشات ، ومن خلال واجهة برمجة التطبيقات يمكنك الحصول على رد على captcha ، وإدخال ملف تعريف ارتباط في الطلب ، على سبيل المثال ، الذي سيتم إصداره ، ثم معالجة المعلومات تلقائيًا من هذا الموقع ... في كل مرة تظهر فيها كلمة التحقق ، نسحب apishka ، ونحصل على إجابة على captcha - ضعها في السؤال التالي ونمضي قدمًا.
من الواضح أن هذا يكلف أيضًا فلسًا كبيرًا - يتم شراء حل captcha بكميات كبيرة. لكن إذا كانت بياناتنا أغلى من تكلفة كل هذه الحيل ، فلماذا لا؟
الآن بعد أن نظرنا في التطور نحو تعقيد كل هذه الأدوات ، دعنا نفكر فيما يجب فعله إذا حدث الكشط على موردنا عبر الإنترنت - متجر على الإنترنت ، قاعدة معرفية عامة ، أو أي شيء آخر.

أول شيء يجب فعله هو العثور على مكشطة. سأخبرك بهذا: ليست كل حالات التجمعات العامة لها آثار سلبية بشكل عام ، كما نظرنا بالفعل في بداية التقرير. كقاعدة عامة ، يمكن للطرق الأكثر بدائية ، والنصوص نفسها بدون قيود على المعدل ، دون الحد من سرعة الطلب ، أن تسبب ضررًا أكبر بكثير (إذا لم يتم منعها عن طريق الحماية) أكثر من أي عملية تجريف معقدة ومتطورة ومتصفح برأس مع طلب واحد في الساعة ، والتي في البداية لا تزال بحاجة إلى العثور عليها بطريقة ما في السجلات.

لذلك ، عليك أولاً أن تفهم أنه يتم كشطنا - لإلقاء نظرة على المعاني التي تتأثر عادةً بهذا النشاط. نحن نتحدث الآن عن المعايير الفنية ومقاييس العمل. تلك الأشياء التي يمكنك رؤيتها في جرافانا ، مع مرور الوقت تراقب الحمل وحركة المرور ، وجميع أنواع الاندفاعات والشذوذ. يمكنك أيضًا القيام بذلك يدويًا إذا كنت لا تستخدم أداة أمان ، ولكن يتم القيام بذلك بشكل أكثر موثوقية من قبل أولئك الذين يعرفون كيفية تصفية حركة المرور ، واكتشاف جميع أنواع الحوادث ومطابقتها مع بعض الأحداث. لأنه بالإضافة إلى تحليل السجلات بعد الحقيقة بالإضافة إلى تحليل كل طلب فردي ، يمكن استخدام بعض الوسائل المتراكمة لحماية قاعدة المعارف هنا ، والتي شهدت بالفعل إجراءات الكاشطات على هذا المورد أو على موارد مماثلة ، ويمكنك بطريقة ما مقارنة أحدهما بالآخر - الكلام حول تحليل الارتباط.
بالنسبة لمقاييس الأعمال ، فقد تذكرنا بالفعل استخدام مثال البرامج النصية التي تسبب ضررًا ماليًا مباشرًا أو غير مباشر. إذا كان من الممكن تتبع ديناميكيات هذه المعلمات بسرعة ، فيمكن ملاحظة التجريف مرة أخرى - وبعد ذلك ، إذا قمت بحل هذه المشكلة بنفسك ، فمرحبًا بك في سجلات الواجهة الخلفية.
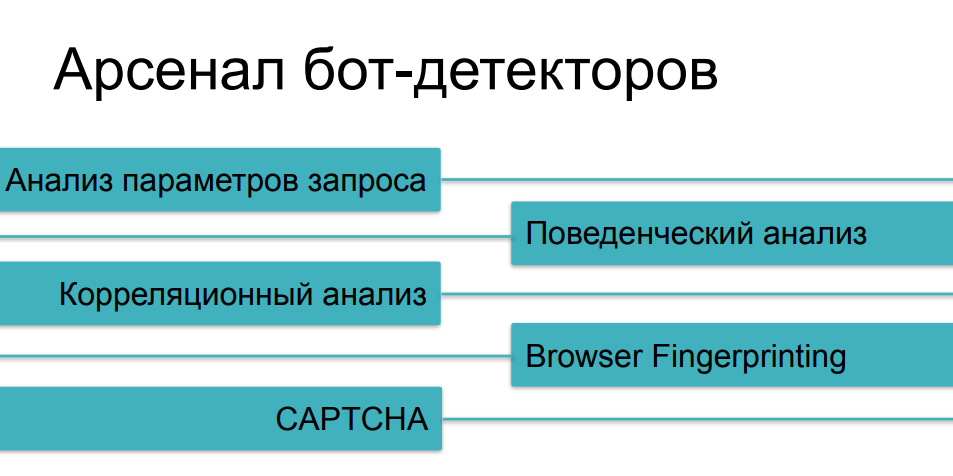
بالنسبة لوسائل الحماية المستخدمة ضد الكشط العدواني ، فقد درسنا بالفعل معظم الطرق ، نتحدث عن فئات مختلفة من الروبوتات. سيساعدنا تحليل حركة المرور من أبسط الحالات ، وسيساعدنا التحليل السلوكي على تتبع أشياء مثل الغموض (استبدال الهوية) والبرامج النصية متعددة الحالات. ضد الأشياء الأكثر تعقيدًا ، سنجمع المطبوعات الرقمية. وبالطبع ، لدينا اختبار CAPTCHA باعتباره الحجة الأخيرة للملوك - إذا لم نتمكن بطريقة ما من التقاط روبوت ماكر على الأسئلة السابقة ، فمن المحتمل أن يتعثر في اختبار CAPTCHA ، أليس كذلك؟
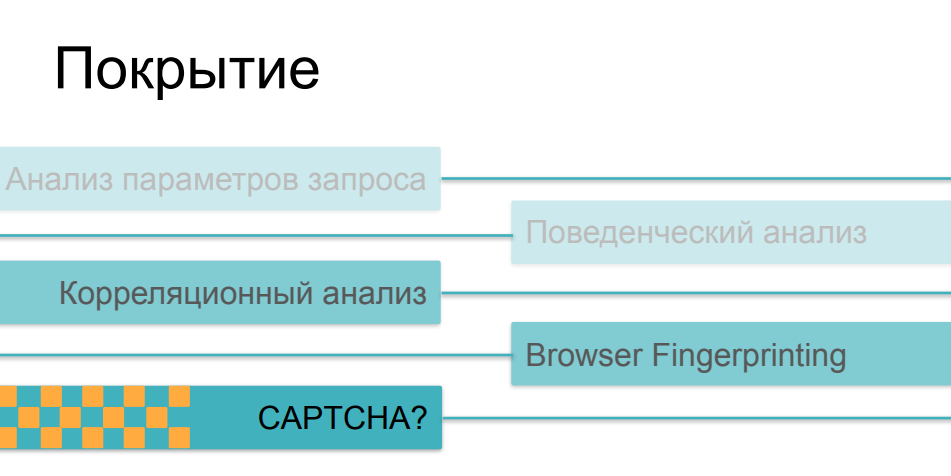
حسنًا ، الأمر أكثر تعقيدًا قليلاً هنا. والحقيقة هي أنه كلما زاد تعقيد وحيلة الشيكات ، أصبحت أكثر تكلفة ، خاصة بالنسبة إلى جانب العميل. إذا كان من الممكن إجراء تحليل حركة المرور والمقارنة اللاحقة للمعلمات مع بعض القيم التاريخية بشكل غير جراحي على الإطلاق ، دون التأثير على وقت تحميل الصفحة وسرعة المورد عبر الإنترنت من حيث المبدأ ، فإن البصمات ، إذا كانت ضخمة بما يكفي وتجري مئات الفحوصات المختلفة على جانب المتصفح ، يمكن تؤثر بشكل خطير على سرعة التنزيل. وقليل من الناس يحبون مشاهدة الصفحات مع عمليات التحقق من الروابط التالية.
عندما يتعلق الأمر بـ CAPTCHA ، فهذه هي الطريقة الأكثر فظاظة والأكثر تدخلاً. هذا شيء يمكن أن يخيف المستخدمين أو المشترين بعيدًا عن المورد. لا أحد يحب الكابتشا ، ولا يلجأون إليه بسبب الحياة الجيدة - يلجأون إليها عندما لا تنجح جميع الخيارات الأخرى. هناك مفارقة أخرى مضحكة هنا ، مشكلة ما في تطبيق هذه الأساليب. الحقيقة هي أن معظم وسائل الحماية في حالة تراكب أو أخرى تستخدم كل هذه الاحتمالات ، اعتمادًا على مدى تعقيد سيناريو نشاط الروبوت الذي واجهته. إذا تمكن مستخدمنا من اجتياز أدوات تحليل حركة المرور ، وإذا كان سلوكه لا يختلف عن سلوك المستخدمين ، وإذا كانت بصمة إصبعه تبدو وكأنها متصفح صالح ، فقد تغلب على كل هذه الفحوصات ، ثم في النهاية نعرض عليه كلمة التحقق - واتضح أنه شخص ... ...نتيجةً لذلك ، يبدأ عرض captcha ليس للروبوتات الشريرة التي نريد قطعها ، ولكن لنسبة جادة إلى حد ما من المستخدمين - الأشخاص الذين قد يغضبون من هذا وقد لا يأتون في المرة القادمة ، ولا يشترون شيئًا من المورد ، ولا يشاركون في تطويره الإضافي.

بالنظر إلى كل هذه العوامل - ماذا يجب أن نفعل في النهاية إذا وصلنا الكشط ، نظرنا إليه وتمكنا بطريقة ما من تقييم تأثيره على أعمالنا ومؤشراتنا الفنية؟ من ناحية أخرى ، ليس من المنطقي محاربة التجريف بحكم التعريف كما هو الحال مع جمع البيانات العامة أو الآلات أو الأشخاص - لقد وافقت أنت بنفسك على أن هذه البيانات متاحة لأي مستخدم يأتي من الإنترنت. وحل مشكلة الحد من التجريف "بعيدًا عن المبدأ" - أي نظرًا لحقيقة أن الروبوتات المتقدمة والموهوبة تأتي إليك ، تحاول حظرها جميعًا - فهذا يعني إنفاق الكثير من الموارد على الحماية ، إما بنفسك ، أو باستخدام حل مكلف ومعقد للغاية ، أو مستضافة ذاتيًا أو قائمة على السحابة في "وضع الأمان الأقصى" ، وسعيًا وراء كل روبوت فردي ، تخاطر بإخافة حصة المستخدمين الصالحين مع مثل هذه الأشياء ،مثل فحوصات جافا سكريبت الثقيلة ، مثل الكابتشا التي تنبثق عند كل انتقال ثالث. كل هذا يمكن أن يغير موقعك بشكل لا يمكن التعرف عليه لصالح زوار موقعك.
إذا كنت تريد استخدام أداة حماية ، فأنت بحاجة إلى البحث عن تلك التي تسمح لك بالتغيير والعثور بطريقة ما على توازن بين نسبة الكاشطات (من البسيط إلى المعقد) التي ستحاول قطعها عن استخدام الموارد الخاصة بك ، وفي الواقع ، سرعة الويب الخاص بك - الموارد. لأنه ، كما رأينا بالفعل ، يتم إجراء بعض الفحوصات ببساطة وبسرعة ، في حين أن بعض عمليات الفحص صعبة وتستغرق وقتًا طويلاً - وفي نفس الوقت تكون ملحوظة جدًا للزوار أنفسهم. لذلك ، فإن الحلول القادرة على تطبيق وتغيير هذه الإجراءات المضادة داخل منصة مشتركة ستسمح لك بتحقيق هذا التوازن بشكل أسرع وأفضل.
حسنًا ، من المهم جدًا أيضًا استخدام ما يسمى بـ "العقلية الصحيحة" في دراسة كل هذه المشكلات بمفردهم أو بأمثلة أخرى. يجب أن نتذكر أن البيانات العامة نفسها ليست في حاجة إلى الحماية - ستظل متاحة عاجلاً أم آجلاً لجميع الأشخاص الذين يريدونها. يجب حماية تجربة المستخدم: تجربة المستخدم لعملائك وعملائك ومستخدميك ، والتي ، على عكس أدوات الكشط ، تحقق لك دخلاً. يمكنك الاحتفاظ بها وزيادتها إذا كنت على دراية أفضل بهذا المجال المثير للاهتمام للغاية.
شكرا جزيلا لكم على اهتمامكم!
