 مرحبا سكان! لقد نشرنا دليلاً عمليًا لمعالجة نصوص اللغة الطبيعية وتوليدها. الكتاب مجهز بجميع الأدوات والتقنيات اللازمة لإنشاء أنظمة معالجة اللغات الطبيعية المطبقة من أجل ضمان تشغيل المساعد الافتراضي (روبوت الدردشة) ، أو مرشح البريد العشوائي ، أو برنامج منسق المنتدى ، أو محلل المشاعر ، أو برنامج بناء قاعدة المعرفة ، أو محلل نصوص اللغة الطبيعية الذكي ، أو تقريبًا أي تطبيق NLP آخر يمكن تخيله.
مرحبا سكان! لقد نشرنا دليلاً عمليًا لمعالجة نصوص اللغة الطبيعية وتوليدها. الكتاب مجهز بجميع الأدوات والتقنيات اللازمة لإنشاء أنظمة معالجة اللغات الطبيعية المطبقة من أجل ضمان تشغيل المساعد الافتراضي (روبوت الدردشة) ، أو مرشح البريد العشوائي ، أو برنامج منسق المنتدى ، أو محلل المشاعر ، أو برنامج بناء قاعدة المعرفة ، أو محلل نصوص اللغة الطبيعية الذكي ، أو تقريبًا أي تطبيق NLP آخر يمكن تخيله.
الكتاب موجه لمطوري بايثون المتوسطين والمتقدمين. سيكون جزء كبير من الكتاب مفيدًا لأولئك القراء الذين يعرفون بالفعل كيفية تصميم أنظمة معقدة وتطويرها ، حيث يحتوي على العديد من الأمثلة للحلول الموصى بها ويكشف عن إمكانات خوارزميات البرمجة اللغوية العصبية الأكثر حداثة. بينما يمكن أن تساعدك معرفة البرمجة الشيئية في بايثون على بناء أنظمة أفضل ، فليس مطلوبًا استخدام المعلومات الواردة في هذا الكتاب.
ماذا ستجد في الكتاب
I . , . , , , , , . -, , 2–4, . , 90%- 1990- — .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
الشبكات العصبية الراجعة: الشبكات العصبية المتكررة
يوضح الفصل 7 إمكانيات تحليل جزء أو جملة كاملة باستخدام شبكة عصبية تلافيفية ، وتتبع الكلمات المتجاورة في الجملة عن طريق تطبيق مرشح أوزان مشتركة (إجراء التفاف) عليها. يمكن أيضًا العثور على الكلمات التي تحدث في مجموعات في حزمة. يقاوم الويب أيضًا التحولات الصغيرة في مواضع هذه الكلمات. في الوقت نفسه ، يمكن أن تؤثر المفاهيم المجاورة بشكل كبير على الشبكة. ولكن إذا كنت بحاجة إلى إلقاء نظرة على الصورة الكبيرة لما يحدث ، فخذ في الاعتبار العلاقات على مدى فترة زمنية أطول ، نافذة تغطي أكثر من 3-4 رموز من التوكن؟ كيف يتم إدخال مفهوم الأحداث الماضية في الشبكة؟ ذاكرة؟
لكل مثال تدريبي (أو مجموعة من الأمثلة المضطربة) والإخراج (أو مجموعة المخرجات) لشبكة التغذية العصبية الأمامية ، يجب تعديل أوزان الشبكة العصبية للخلايا العصبية الفردية بناءً على طريقة الانتشار العكسي. لقد أظهرنا هذا بالفعل. لكن نتائج مرحلة التدريب للمثال التالي مستقلة في الغالب عن ترتيب بيانات الإدخال. تحاول الشبكات العصبية التلافيفية التقاط علاقات النظام هذه من خلال التقاط العلاقات المحلية ، ولكن هناك طريقة أخرى.
في الشبكة العصبية التلافيفية ، يتم تمرير كل مثال تدريب إلى الشبكة كمجموعة مجمعة من الرموز المميزة للكلمات. يتم تجميع متجهات الكلمة في مصفوفة بالشكل (طول متجه الكلمة × عدد الكلمات في المثال) ، كما هو موضح في الشكل. 8.1

لكن هذا التسلسل من متجهات الكلمات يمكن نقله بسهولة إلى الشبكة العصبية الأمامية الطبيعية من الفصل 5 (الشكل 8.2) ، أليس كذلك؟
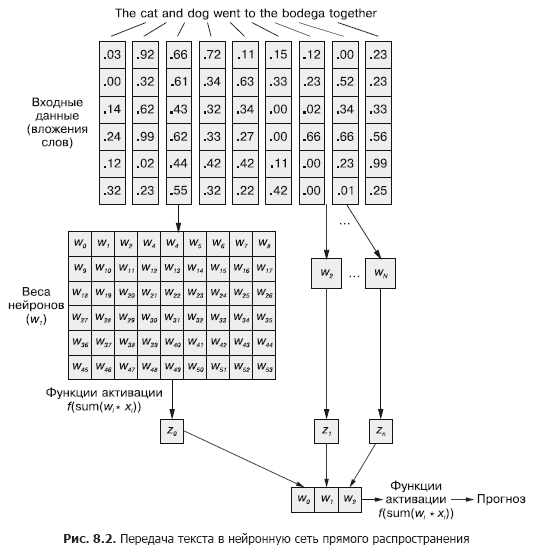
بالطبع ، هذا نموذج عملي تمامًا. باستخدام طريقة تمرير بيانات الإدخال هذه ، ستكون الشبكة العصبية المغذية قادرة على الاستجابة للتكرار المشترك للرموز ، وهو ما نحتاجه. ولكن في الوقت نفسه ، سيتفاعل مع جميع التكرارات المشتركة بنفس الطريقة ، بغض النظر عما إذا كان مفصولاً بنص طويل ، أو أنهما بجوار بعضهما البعض. بالإضافة إلى ذلك ، الشبكات العصبية المغذية ، مثل CNNs ، ضعيفة في التعامل مع المستندات ذات الطول المتغير. يتعذر عليهم معالجة النص في نهاية المستند إذا تجاوز عرض الويب.
تعمل الشبكات العصبية المغذية بشكل أفضل في نمذجة علاقة عينة البيانات ككل مع التسمية المقابلة لها. الكلمات الموجودة في بداية الجملة وفي نهايتها لها نفس التأثير تمامًا على إشارة الخرج كما في المنتصف ، على الرغم من حقيقة أنه من غير المحتمل أن تكون مرتبطة ببعضها البعض ارتباطًا معنويًا.
من الواضح أن هذا التوحيد (توحيد التأثير) يمكن أن يسبب مشاكل في حالة ، على سبيل المثال ، رموز النفي القاسية ومعدلات (الصفات والظروف) مثل "لا" أو "جيد". في الشبكة العصبية المغذية ، تؤثر كلمات النفي على معنى كل الكلمات في الجملة ، حتى لو كانت بعيدة عن المكان الذي يجب أن تؤثر فيه بالفعل.
تعد التلافيف أحادية البعد طريقة لحل هذه العلاقات بين الرموز عن طريق تحليل كلمات متعددة عبر النوافذ. تم تصميم طبقات الاختزال التي تمت مناقشتها في الفصل 7 خصيصًا لاستيعاب التغييرات الصغيرة في ترتيب الكلمات. في هذا الفصل ، سنلقي نظرة على نهج مختلف سيساعدنا على اتخاذ الخطوة الأولى نحو مفهوم ذاكرة الشبكة العصبية. بدلاً من تفكيك اللغة على أنها جزء كبير من البيانات ، سنبدأ في النظر إلى تشكيلها المتسلسل ، رمزًا برمز ، بمرور الوقت.
8.1 الحفظ في الشبكات العصبية
بالطبع ، نادرًا ما تكون الكلمات في الجملة مستقلة تمامًا عن بعضها البعض ؛ حدوثها يتأثر أو يتأثر بحدوث كلمات أخرى في المستند. على سبيل المثال: انطلقت السيارة المسروقة إلى الحلبة واندفعت سيارة المهرج إلى الحلبة.
قد يكون لديك انطباعات مختلفة تمامًا عن الجملتين عندما تقرأ حتى النهاية. بناء العبارة فيها هو نفسه: الصفة ، والاسم ، والفعل ، وعبارة الجر. لكن استبدال الصفة فيها يغير جذريًا جوهر ما يحدث من وجهة نظر القارئ.
كيف تحاكي مثل هذه العلاقة؟ كيف نفهم أن الساحة وحتى السرعة يمكن أن يكون لها دلالات مختلفة قليلاً إذا كانت هناك صفة أمامهم في الجملة التي لا تمثل تعريفًا مباشرًا لأي منهم؟
إذا كانت هناك طريقة لتذكر ما حدث في وقت سابق (تذكر على وجه الخصوص ما حدث في الخطوة t في الخطوة t + 1) ، سيكون من الممكن تحديد الأنماط التي تنشأ عند ظهور رموز معينة في سلسلة من الأنماط المرتبطة بالرموز المميزة الأخرى. تتيح الشبكات العصبية المتكررة (RNNs) للشبكة العصبية حفظ الكلمات السابقة للتسلسل.
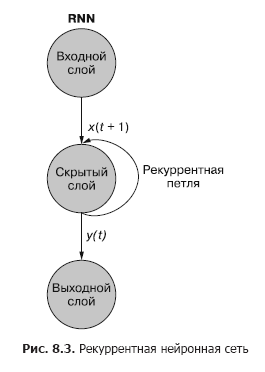
كما ترون في الشكل. في الشكل 8.3 ، تضيف خلية عصبية متكررة منفصلة من الطبقة المخفية حلقة متكررة إلى الشبكة "لإعادة استخدام" إخراج الطبقة المخفية في الوقت t. تتم إضافة الإخراج في الوقت t إلى الإدخال التالي في الوقت t + 1. تعالج الشبكة هذا الإدخال الجديد في الخطوة الزمنية t + 1 لإنتاج مخرجات طبقة مخفية في الوقت t + 1. هذا الإخراج في الوقت t + 1 ثم يتم إعادة استخدامه بواسطة الشبكة ويتم تضمينه في إشارة الإدخال في خطوة زمنية t + 2 ، إلخ.
بينما تبدو فكرة التأثير على دولة عبر الزمن مربكة بعض الشيء ، فإن المفهوم الأساسي بسيط. تُستخدم نتائج كل إشارة عند إدخال شبكة عصبية تقليدية في خطوة زمنية t كإشارة إدخال إضافية إلى جانب القطعة التالية من البيانات التي يتم تغذيتها لمدخل الشبكة في خطوة زمنية t + 1. تتلقى الشبكة معلومات ليس فقط حول ما يحدث الآن ، ولكن أيضًا حول ما حدث من قبل ...
. , . , . , . , . , , . . , .
t . , t = 0 — , t + 1 — . () . , . — .
t, — t + 1.
يمكن تصور الشبكة العصبية المتكررة كما هو موضح في الشكل. 8.3: الدوائر تتوافق مع طبقات كاملة من شبكة عصبية متجهة إلى الأمام ، تتكون من خلية عصبية واحدة أو أكثر. يتم توفير إخراج الطبقة المخفية من قبل الشبكة كالمعتاد ، ولكن بعد ذلك تعود كمدخلات خاصة بها (الطبقة المخفية) جنبًا إلى جنب مع بيانات الإدخال المعتادة للخطوة الزمنية التالية. يصور الرسم التخطيطي حلقة التغذية الراجعة هذه على أنها قوس يقود من إخراج الطبقة إلى المدخل.
الطريقة الأبسط (والأكثر استخدامًا) لتوضيح هذه العملية هي استخدام نشر الشبكة. يوضح الشكل 8.4 شبكة مقلوبة مع عمليتي مسح لمتغير الوقت (t) - طبقات للخطوتين t + 1 و t + 2.
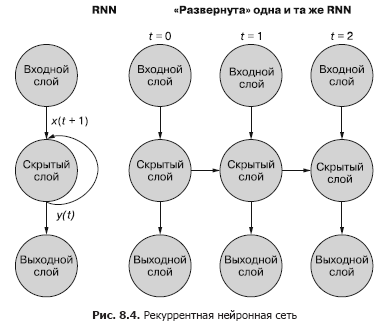
تتوافق كل خطوة من الخطوات الزمنية مع نسخة موسعة من نفس الشبكة العصبية في شكل عمود من الخلايا العصبية. إنه يشبه مشاهدة نص أو إطارات فيديو فردية لشبكة عصبية في أي وقت. تمثل الشبكة الموجودة على اليمين نسخة مستقبلية للشبكة الموجودة على اليسار. يتم إعادة إخراج الطبقة المخفية في الوقت (t) إلى مدخلات الطبقة المخفية مع الإدخال للخطوة الزمنية التالية (t + 1) على اليمين. مرة اخرى. يوضح الرسم التخطيطي تكراريْن لهذا النشر ، ما مجموعه ثلاثة أعمدة من الخلايا العصبية لـ t = 0 و t = 1 و t = 2.
جميع المسارات الرأسية في هذا الرسم البياني متشابهة تمامًا ، فهي تُظهر نفس الخلايا العصبية. إنها تعكس نفس الشبكة العصبية في نقاط زمنية مختلفة. هذا التصور مفيد لتوضيح الحركة الأمامية والخلفية للمعلومات عبر الشبكة أثناء الانتشار الخلفي للخطأ. لكن تذكر عند النظر إلى هذه الشبكات الثلاث المنتشرة: إنها لقطات مختلفة لنفس الشبكة بنفس مجموعة الأوزان.
دعنا نلقي نظرة فاحصة على التمثيل الأصلي للشبكة العصبية المتكررة قبل نشرها ونوضح العلاقة بين إشارات الإدخال والأوزان. تبدو الطبقات الفردية لهذا الشكل RNN كما هو موضح في الشكل. 8.5 و 8.6.

تحتوي جميع الخلايا العصبية للحالة الكامنة على مجموعة من الأوزان المطبقة على كل عنصر من عناصر كل من نواقل الإدخال ، كما هو الحال في شبكة التغذية الأمامية التقليدية. ولكن في هذا المخطط ، ظهرت مجموعة إضافية من الأوزان القابلة للتدريب ، والتي يتم تطبيقها على إشارات الإخراج للخلايا العصبية المخفية من الخطوة الزمنية السابقة. تختار الشبكة ، من خلال التدريب ، الأوزان المناسبة (الأهمية) للأحداث السابقة عند إدخال رمز التسلسل بالرمز.
«», t = 0 t – 1. «» , , . t = 0 . , .
بالعودة إلى البيانات ، تخيل أن لديك مجموعة من المستندات ، كل منها عبارة عن مثال مسمى. وبدلاً من تمرير مجموعة كاملة من متجهات الكلمات إلى الشبكة العصبية التلافيفية لكل عينة ، كما في الفصل السابق (الشكل 8.7) ، نقوم بنقل بيانات العينة إلى RNN ، رمز واحد في كل مرة (الشكل 8.8).

نمرر في متجه الكلمات للرمز الأول ونحصل على ناتج شبكتنا العصبية المتكررة. ثم نقوم بنقل الرمز الثاني ومعه إشارة الخرج من الأول! بعد ذلك نقوم بنقل الرمز الثالث مع إشارة الخرج من الثانية! إلخ. يوجد الآن في شبكتنا العصبية مفاهيم "قبل" و "بعد" ، والسبب والنتيجة ، وبعضها ، وإن كان غامضًا ، مفهوم الوقت (انظر الشكل 8.8).
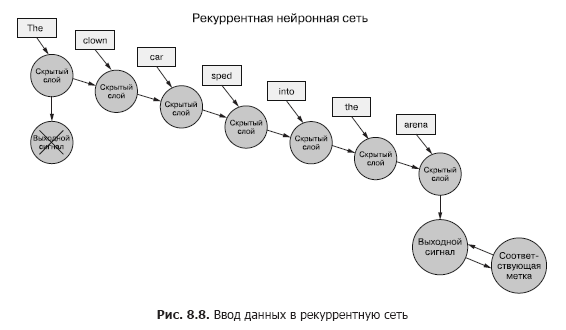
الآن شبكتنا تتذكر شيئًا بالفعل! حسنًا ، إلى حد ما. لا يزال هناك بعض الأشياء المتبقية لمعرفة. أولاً ، كيف يمكن أن يحدث التكاثر العكسي للخطأ في مثل هذه البنية؟
8.1.1. عودة انتشار خطأ في الوقت المناسب
في جميع الشبكات التي تمت مناقشتها أعلاه ، كان هناك تسمية مستهدفة (متغير مستهدف) ، و RNN ليست استثناء. لكن ليس لدينا مفهوم التسمية لكل رمز مميز ، وهناك تسمية واحدة فقط لجميع الرموز لكل من نماذج النص. لدينا ملصقات فقط لعينة من المستندات.
نحن نتحدث عن الرموز المميزة كمدخلات للشبكة في كل خطوة زمنية ، لكن الشبكات العصبية المتكررة يمكنها أيضًا العمل مع أي بيانات سلسلة زمنية. يمكن أن تكون الرموز أي ، منفصلة أو متصلة: قراءات محطة طقس ، ملاحظات ، رموز في جملة ، إلخ.
هنا نقارن أولاً إخراج الشبكة في الخطوة الزمنية الأخيرة مع الإشارة. هذا ما سنسميه (في الوقت الحالي) خطأ ، أي أن شبكتنا تحاول تقليله. لكن هناك اختلاف طفيف عن الفصول السابقة. يتم تقسيم عينة معينة من البيانات إلى أجزاء أصغر يتم إدخالها في الشبكة العصبية بالتتابع. ومع ذلك ، بدلاً من استخدام الإخراج مباشرة لكل من هذه الأمثلة الفرعية ، نقوم بإرسالها مرة أخرى إلى الشبكة.
حتى الآن ، نحن مهتمون فقط بإشارة الخرج النهائية. يتم تغذية كل من الرموز المميزة في التسلسل في الشبكة ، ويتم حساب الخسائر بناءً على ناتج الخطوة الزمنية الأخيرة (الرمز المميز) (الشكل 8.9).
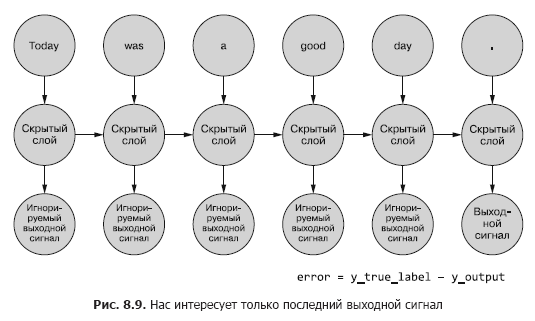
من الضروري تحديد ما إذا كان هناك خطأ لمثال معين ، أي الأوزان يجب تحديثها ومقدارها. في الفصل الخامس ، أوضحنا لك كيفية إعادة نشر خطأ عبر شبكة عادية. ونعلم أن مقدار تصحيح الوزن يعتمد على مساهمته (هذا الوزن) في الخطأ. يمكننا تغذية الرمز المميز من تسلسل العينة إلى إدخال الشبكة ، وحساب الخطأ للخطوة الزمنية السابقة بناءً على إشارة خرجها. هذا هو المكان الذي يبدو فيه أن فكرة تكاثر الخطأ في الوقت المناسب تربك كل شيء.
ومع ذلك ، يمكن للمرء ببساطة أن يفكر في الأمر كعملية محددة زمنياً. في كل خطوة زمنية ، يتم تغذية الرموز المميزة ، بدءًا من الأولى عند t = 0 ، واحدة تلو الأخرى إلى مدخلات الخلايا العصبية المخفية الموجودة في المقدمة - العمود التالي في الشكل. 8.9 في الوقت نفسه ، تتوسع الشبكة ، لتكشف عن العمود التالي من الشبكة ، وهي جاهزة بالفعل لتلقي الرمز المميز التالي في التسلسل. تتكشف الخلايا العصبية الكامنة واحدة تلو الأخرى ، مثل صندوق الموسيقى أو البيانو الميكانيكي. في النهاية ، عندما يتم إدخال جميع عناصر الأمثلة في الشبكة ، لن يكون هناك المزيد لنشره وسنحصل على التسمية النهائية للمتغير المستهدف الذي يهمنا ، والذي يمكن استخدامه لحساب الخطأ وضبط الأوزان. لقد ذهبنا للتو على طول الرسم البياني الحسابي لهذه الشبكة غير المحكومة.
في الوقت الحالي ، نعتبر بيانات الإدخال ثابتة بشكل عام. يمكنك تتبع من خلال الرسم البياني بأكمله إشارة الإدخال التي تدخل أي خلية عصبية. ونظرًا لأننا نعرف كيف تعمل الخلايا العصبية ، يمكننا إعادة نشر الخطأ مرة أخرى على طول السلسلة ، على طول المسار نفسه ، تمامًا كما هو الحال في حالة الشبكة العصبية التقليدية.
لنشر الخطأ مرة أخرى إلى الطبقة السابقة ، سنستخدم قاعدة السلسلة. بدلاً من الطبقة السابقة ، سننشر الخطأ إلى نفس الطبقة في الماضي ، كما لو كانت جميع متغيرات الشبكة المنشورة مختلفة (الشكل 8.10). هذا لا يغير الرياضيات الحسابية.

ينتشر الخطأ مرة أخرى من الخطوة الأخيرة. يتم حساب التدرج اللوني لخطوة زمنية سابقة بالنسبة إلى الخطوة الأحدث. بعد حساب جميع التدرجات القائمة على الرموز الفردية حتى الخطوة t = 0 لهذا المثال ، يتم تجميع التغييرات وتطبيقها على مجموعة واحدة من الأوزان.
8.1.2. متى يتم تحديث ماذا
لقد قمنا بتحويل RNN الغريب إلى شيء مثل شبكة عصبية تلقائية منتظمة ، لذا يجب أن يكون تحديث الأوزان أمرًا بسيطًا. ومع ذلك ، هناك تحذير واحد. الحيلة هي أن الأوزان لا يتم تحديثها في فرع آخر من الشبكة العصبية على الإطلاق. يمثل كل فرع نفس الشبكة في نقاط زمنية مختلفة. الأوزان لكل خطوة زمنية هي نفسها (انظر الشكل 8.10).
أحد الحلول البسيطة لهذه المشكلة هو حساب تصحيحات الأوزان في كل خطوة من خطوات الوقت مع تأخير في التحديث. في شبكة التغذية الأمامية ، يتم حساب جميع تحديثات الأوزان على الفور بعد حساب جميع التدرجات لإشارة إدخال معينة. وهنا هو نفسه تمامًا ، ولكن يتم تأجيل التحديثات حتى نصل إلى الخطوة الزمنية الأولية (صفر) لبيانات عينة إدخال محددة.
يجب أن يعتمد حساب التدرج اللوني على قيم الأوزان التي ساهموا بها في الخطأ. إليك الجزء الأكثر صعوبة: ساهم الوزن في الخطوة الزمنية t بطريقة ما في حدوث الخطأ. ويستقبل الوزن نفسه إشارة إدخال مختلفة في الخطوة الزمنية t + 1 ، مما يعني أنه يقدم مساهمة مختلفة في الخطأ.
يمكنك حساب التغييرات المختلفة في الأوزان في كل خطوة زمنية ، وتلخيصها ، ثم تطبيق التغييرات المجمعة على أوزان الطبقة المخفية كخطوة أخيرة في مرحلة التدريب.
, . , , . , , . , .
سحر حقيقي. عندما ينتشر الخطأ مرة أخرى في الوقت المناسب ، يمكن تصحيح الوزن الفردي في اتجاه واحد في الخطوة الزمنية t (اعتمادًا على استجابته لإشارة الإدخال في الخطوة الزمنية t) ، ثم في الاتجاه الآخر في الخطوة الزمنية t - 1 (وفقًا لـ كيف تفاعلت مع إشارة الإدخال في الخطوة الزمنية t - 1) لعينة بيانات واحدة! تذكر أن الشبكات العصبية بشكل عام تستند إلى تقليل وظيفة الخسارة إلى أدنى حد بغض النظر عن مدى تعقيد الخطوات الوسيطة. بشكل جماعي ، تعمل الشبكة على تحسين هذه الميزة المعقدة. نظرًا لأن تحديث الوزن يتم تطبيقه مرة واحدة فقط على بيانات العينة ، فإن الشبكة (إذا تقاربت على الإطلاق ، بالطبع) تتوقف في النهاية عند الوزن الأمثل بهذا المعنى لإشارة إدخال محددة وخلايا عصبية معينة.
نتائج الخطوات السابقة لا تزال مهمة
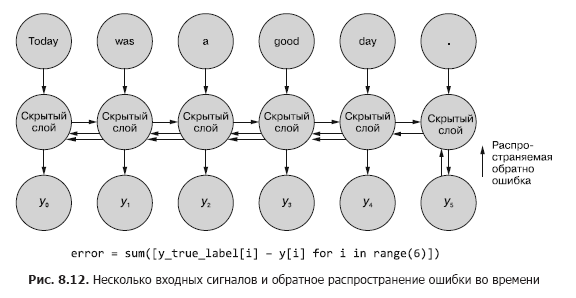
في بعض الأحيان يكون التسلسل الكامل للقيم التي تم إنشاؤها في جميع خطوات الوقت الوسيط مهمًا. في الفصل 9 ، سنقدم أمثلة على المواقف التي يكون فيها ناتج خطوة زمنية معينة t لا يقل أهمية عن ناتج الخطوة الزمنية الأخيرة. في التين. يوضح الشكل 8.11 طريقة لجمع بيانات الخطأ لأي خطوة زمنية وإعادة نشرها لتصحيح جميع أوزان الشبكة.

تشبه هذه العملية الانتشار الخلفي المعتاد لخطأ في الوقت المحدد لعدد n من الخطوات الزمنية. في هذه الحالة ، ننشر الخطأ مرة أخرى من عدة مصادر في نفس الوقت. ولكن ، كما في المثال الأول ، تعد تعديلات الوزن مضافة. ينتشر الخطأ من الخطوة الزمنية الأخيرة في البداية إلى الأولى مع مجموع التغييرات في كل من الأوزان. ثم يحدث نفس الشيء مع الخطأ المحسوب في الخطوة الزمنية قبل الأخيرة ، مع تلخيص جميع التغييرات حتى t = 0. تتكرر هذه العملية حتى نصل إلى الخطوة صفر مع الانتشار الخلفي للخطأ كما لو كان الخطأ الوحيد. ثم يتم تطبيق التغييرات التراكمية مرة واحدة على الطبقة المخفية المقابلة.
في التين. يوضح الشكل 8.12 كيفية انتشار الخطأ من كل إشارة خرج وصولاً إلى t = 0 ، ثم يتم تجميعها قبل التصحيح النهائي للأوزان. هذه هي الفكرة الرئيسية لهذا القسم. كما في حالة الشبكة العصبية التقليدية ، يتم تحديث الأوزان فقط بعد حساب التغيير المقترح في الأوزان لخطوة الانتشار العكسي بأكملها لإشارة إدخال معينة (أو مجموعة من إشارات الإدخال). في حالة RNN ، يتضمن الانتشار الخلفي للخطأ تحديثات حتى الوقت t = 0.
قد يؤدي تحديث الأوزان مسبقًا إلى تشويه حسابات التدرج مع انتشار الخطأ العكسي في نقاط زمنية سابقة. تذكر أنه يتم حساب التدرجات بالنسبة لوزن معين. إذا تم تحديث هذا الوزن مبكرًا جدًا ، على سبيل المثال في الخطوة الزمنية t ، ثم عند حساب التدرج اللوني في الخطوة الزمنية t - 1 ، ستتغير قيمة الوزن (تذكر أن هذا هو نفس موضع الوزن في الشبكة). وعند حساب الانحدار بناءً على إشارة الدخل من الخطوة الزمنية t - 1 ، سيتم تشويه الحسابات. في الواقع ، في هذه الحالة ، سيتم تغريم الوزن (أو مكافأة) على ما هو "عدم اللوم"!
عن المؤلفين
هوبسون لين(هوبسون لين) لديه 20 عامًا من الخبرة في بناء أنظمة مستقلة تتخذ قرارات حاسمة لصالح الناس. في Talentpair ، علم هوبسون الآلات قراءة السير الذاتية وفهمها بطريقة أقل تحيزًا من معظم مديري التوظيف. في Aira ، ساعد في بناء أول روبوت محادثة خاص بهم مصمم لتفسير العالم للمكفوفين. هوبسون معجب شغوف بانفتاح الذكاء الاصطناعي وتوجهه المجتمعي. يقدم مساهمات نشطة لمشاريع مفتوحة المصدر مثل Keras و scikit-Learn و PyBrain و PUGNLP و ChatterBot. يشارك حاليًا في الأبحاث المفتوحة والمشاريع التعليمية لـ Total Good ، بما في ذلك إنشاء مساعد افتراضي مفتوح المصدر. لقد نشر العديد من المقالات ، وألقى محاضرات في AIAA ، PyCon ،PAIS و IEEE وحصل على العديد من براءات الاختراع في مجال الروبوتات والأتمتة.
Hannes Max Hapke هو مهندس كهربائي تحول إلى مهندس تعلم آلي. في المدرسة الثانوية ، أصبح مهتمًا بالشبكات العصبية عندما درس طرق حساب الشبكات العصبية على المتحكمات الدقيقة. في وقت لاحق في الكلية ، طبق مبادئ الشبكات العصبية على الإدارة الفعالة لمحطات الطاقة المتجددة. هانيس شغوف بأتمتة تطوير البرمجيات وخطوط أنابيب التعلم الآلي. وقد شارك في تأليف نماذج التعلم العميق وخطوط أنابيب التعلم الآلي في مجالات التوظيف والطاقة والرعاية الصحية. قدم Hannes عروضًا تقديمية حول التعلم الآلي في مجموعة متنوعة من المؤتمرات بما في ذلك OSCON و Open Source Bridge و Hack University.
كول هوارد(كول هوارد) هو ممارس لتعلم الآلة وممارس في البرمجة اللغوية العصبية وكاتب. باحثًا دائمًا عن الأنماط ، وجد نفسه في عالم الشبكات العصبية الاصطناعية. من بين تطوراته أنظمة التوصية واسعة النطاق للتداول عبر الإنترنت والشبكات العصبية المتقدمة لأنظمة الذكاء الآلي فائقة الأبعاد (الشبكات العصبية العميقة) ، والتي احتلت المرتبة الأولى في مسابقات Kaggle. وقد ألقى محادثات حول الشبكات العصبية التلافيفية والشبكات العصبية المتكررة ودورها في معالجة اللغة الطبيعية في مؤتمرات Open Source Bridge و Hack University.
حول الرسم التوضيحي للغلاف
« -, ». (Balthasar Hacquet) Images and Descriptions of Southwestern and Eastern Wends, Illyrians and Slavs (« - , »), () 2008 . (1739–1815) — , , — , - . .
200 . , , . , . , .
200 . , , . , . , .
»يمكن العثور على مزيد من التفاصيل حول الكتاب على موقع الناشر
» جدول المحتويات
» مقتطفات
للساكنين خصم 25٪ على القسيمة - البرمجة اللغوية العصبية
عند الدفع مقابل النسخة الورقية من الكتاب ، يتم إرسال كتاب إلكتروني إلى البريد الإلكتروني.