نهج التحفيز
النهج المقبول عمومًا لمهام رؤية الكمبيوتر هو استخدام الصور كمصفوفة ثلاثية الأبعاد (الطول والعرض وعدد القنوات) وتطبيق التلافيف عليها. هذا النهج له عدة عيوب:
- لم يتم إنشاء جميع وحدات البكسل على قدم المساواة. على سبيل المثال ، إذا كانت لدينا مهمة تصنيف ، فإن الكائن نفسه أكثر أهمية بالنسبة لنا من الخلفية. من المثير للاهتمام أن المؤلفين لا يقولون أن الانتباه يستخدم بالفعل في مهام رؤية الكمبيوتر ؛
- لا تعمل التلافيفات بشكل جيد مع وحدات البكسل البعيدة. توجد طرق ذات تلافيف متوسعة وتجميع متوسط عالمي ، لكنها لا تحل المشكلة نفسها ؛
- التلافيف ليست فعالة بدرجة كافية في الشبكات العصبية العميقة جدًا.
نتيجة لذلك ، يقترح المؤلفون ما يلي: تحويل الصور إلى نوع من الرموز المرئية وإرسالها إلى المحول.

- أولاً ، يتم استخدام العمود الفقري العادي للحصول على خرائط الميزات
- بعد ذلك ، يتم تحويل خريطة المعالم إلى رموز مرئية
- يتم تغذية الرموز إلى المحولات
- يمكن استخدام خرج المحول لمشاكل التصنيف
- وإذا قمت بدمج ناتج المحول مع خريطة المعالم ، يمكنك الحصول على تنبؤات لمهام التجزئة
من بين الأعمال في اتجاهات مماثلة ، لا يزال المؤلفون يذكرون الانتباه ، لكن لاحظوا أنه عادةً ما يتم تطبيق الاهتمام على البكسل ، وبالتالي ، يزيد بشكل كبير من التعقيد الحسابي. يتحدثون أيضًا عن الأعمال المتعلقة بتحسين كفاءة الشبكات العصبية ، لكنهم يعتقدون أنهم قدموا تحسينات أقل وأقل في السنوات الأخيرة ، لذلك يجب البحث عن أساليب أخرى.
محول بصري
الآن دعونا نلقي نظرة فاحصة على كيفية عمل النموذج.
كما ذكرنا أعلاه ، فإن عمليات جلب العمود الفقري تتميز بخرائط ، ويتم تمريرها إلى طبقات المحولات المرئية.
يتكون كل محول مرئي من ثلاثة أجزاء: رمز مميز ومحول وجهاز عرض.
رمزية

يسترد الرمز المميز الرموز المميزة المرئية. في الواقع ، نحن نأخذ خريطة معالم ونقوم بإعادة تشكيل في (H * W، C) ومن هذا نحصل على الرموز المميزة. يبدو

تصور معاملات الرموز المميزة كما يلي:

ترميز الموضع
كالعادة ، لا تحتاج المحولات إلى الرموز فحسب ، بل تحتاج أيضًا إلى معلومات حول موقعها.

أولاً ، نقوم بإجراء عينة مختزلة ، ثم نضرب في أوزان التدريب ونتسلسل مع الرموز المميزة. لضبط عدد القنوات ، يمكنك إضافة التفاف 1D.
محول
أخيرًا ، المحول نفسه.

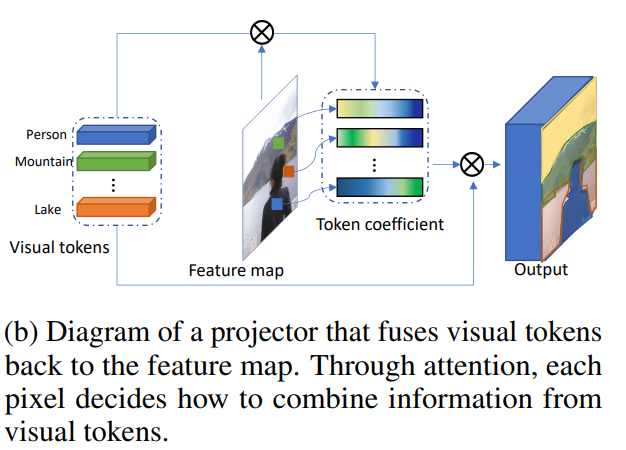
الجمع بين الرموز المرئية وخريطة الميزات
هذا يجعل جهاز العرض.

الترميز الديناميكي
بعد الطبقة الأولى من المحولات ، لا يمكننا فقط استخراج الرموز المرئية الجديدة ، ولكن أيضًا استخدام تلك المستخرجة من الخطوات السابقة. تستخدم الأوزان المدربة للجمع بينها:

استخدام المحولات المرئية لبناء نماذج الرؤية الحاسوبية
علاوة على ذلك ، يصف المؤلفون كيفية تطبيق النموذج على مشاكل رؤية الكمبيوتر. تحتوي كتل المحولات على ثلاثة معلمات تشعبية: عدد القنوات في خريطة الميزة C ، وعدد القنوات في الرمز المرئي Ct ، وعدد الرموز المرئية L.
إذا تبين أن عدد القنوات غير مناسب أثناء الانتقال بين كتل النموذج ، فسيتم استخدام التلافيف 1D و 2 D للحصول على العدد المطلوب من القنوات.
لتسريع العمليات الحسابية وتقليل حجم النموذج ، استخدم التفافات المجموعة.
يُلحق المؤلفون كتل ** الشفرة الزائفة ** في المقالة. وعد بأن يتم نشر الكود الكامل في المستقبل.
تصنيف الصورة
نحن نأخذ ResNet وننشئ محولًا مرئيًا (VT-ResNet) بناءً عليه.
نترك المرحلة 1-4 ، لكن بدلاً من الأخيرة نضع محولات بصرية.
خروج العمود الفقري - خريطة ميزة 14 × 14 ، عدد القنوات 512 أو 1024 اعتمادًا على عمق VT-ResNet. يتم إنشاء 8 رموز مرئية لـ 1024 قناة من خريطة المعالم. يذهب خرج المحول إلى الرأس لتصنيفه.

التجزئة الدلالية
بالنسبة لهذه المهمة ، يتم أخذ الشبكات الهرمية ذات الميزات الشاملة (FPN) كنموذج أساسي.
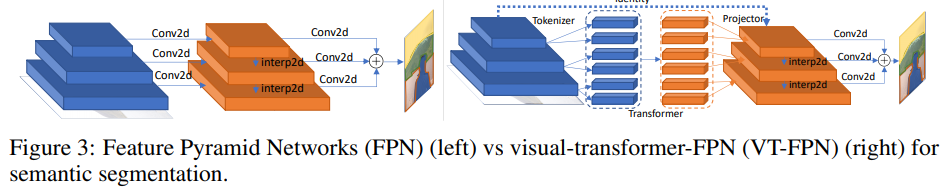
في FPN ، تعمل التلافيفات على صور عالية الدقة ، لذا فإن النموذج ثقيل. استبدل المؤلفون هذه العمليات بالمحول البصري. مرة أخرى ، 8 رموز و 1024 قناة.
التجارب
تصنيف ImageNet
تدريب 400 عصر باستخدام RMSProp. تبدأ بمعدل تعلم 0.01 ، وترتفع إلى 0.16 خلال 5 فترات إحماء ، ثم تضرب كل فترة في 0.9875. تم استخدام تسوية الدُفعة وحجم الدُفعة 2048. تجانس الملصقات ، الزيادة التلقائية ، احتمالية بقاء العمق العشوائي 0.9 ، التسرب 0.2 ، المتوسط المتحرك الأسي 0.99985.
هذا هو عدد التجارب التي اضطررت إلى إجرائها للعثور على كل هذا ...
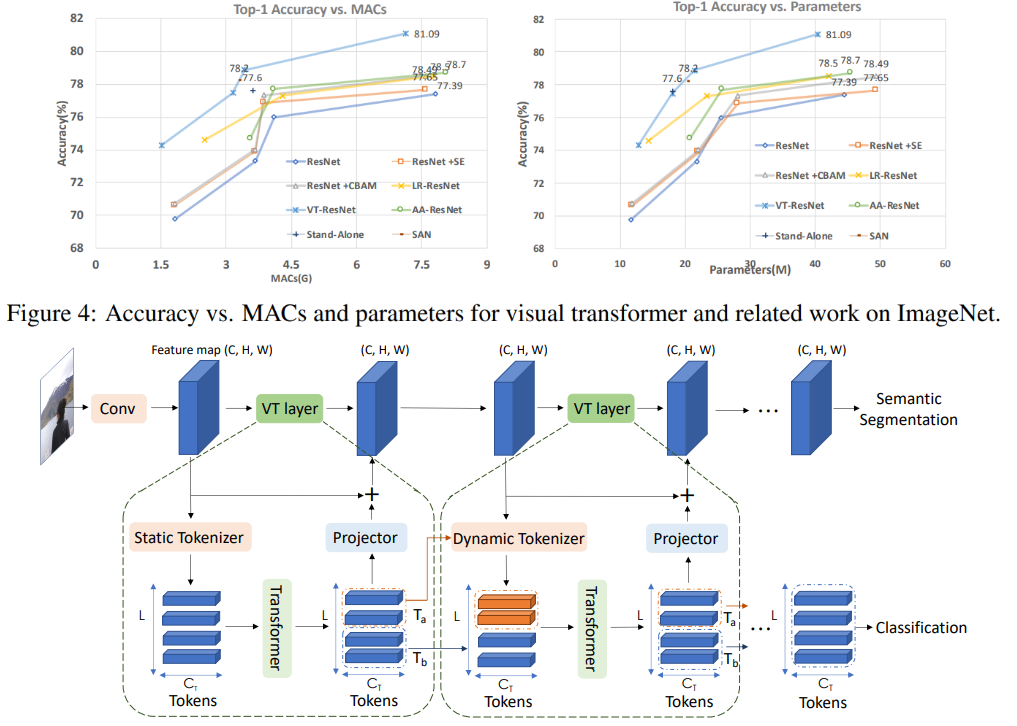
في هذا الرسم البياني يمكنك أن ترى أن الأسلوب يعطي جودة أعلى مع قدر أقل من الحسابات وحجم النموذج.
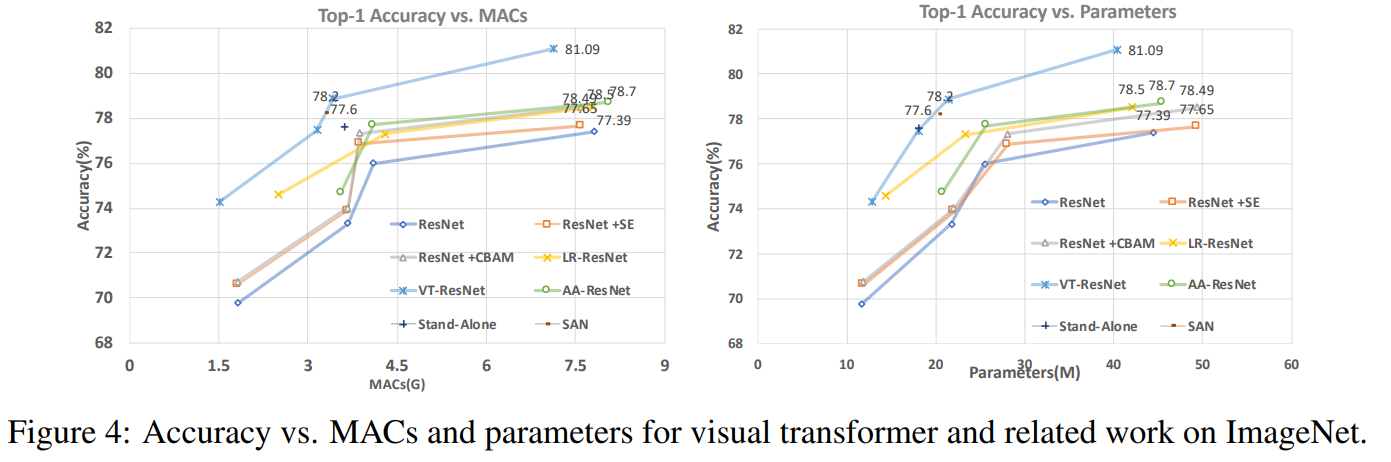
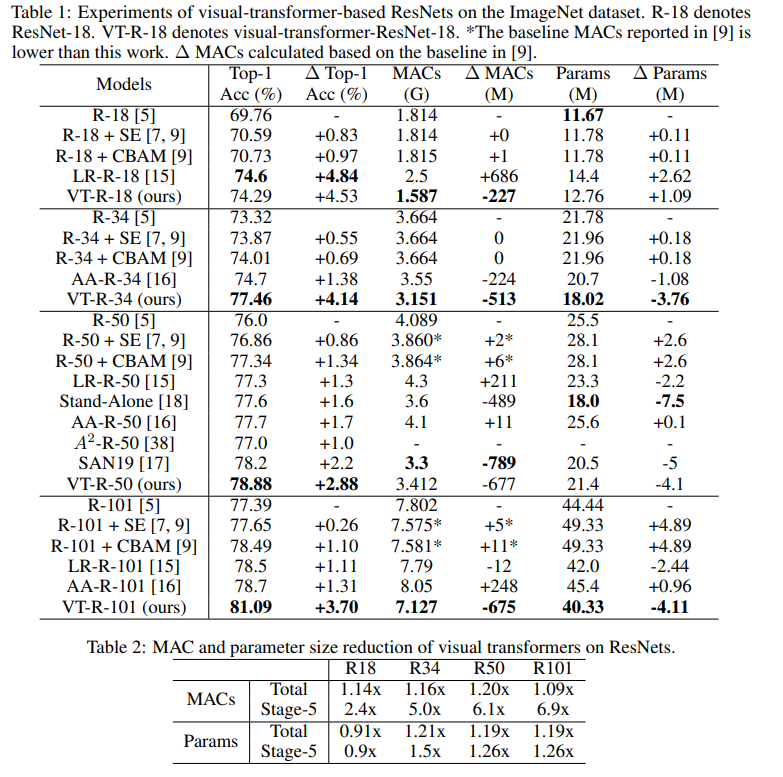
عناوين المقالات للنماذج المقارنة:
ResNet + CBAM - وحدة الانتباه
للكتل التلافيفية ResNet + SE - شبكات الضغط والإثارة
LR-ResNet - شبكات العلاقات المحلية للتعرف على الصور
StandAlone - الاهتمام الذاتي المستقل في نماذج الرؤية
AA-ResNet - الانتباه إلى الشبكات التلافيفية المعززة
SAN - استكشاف الانتباه الذاتي للتعرف على الصور
دراسة الاجتثاث
لتسريع التجارب ، أخذنا VT-ResNet- {18، 34} ودربنا 90 حقبة.
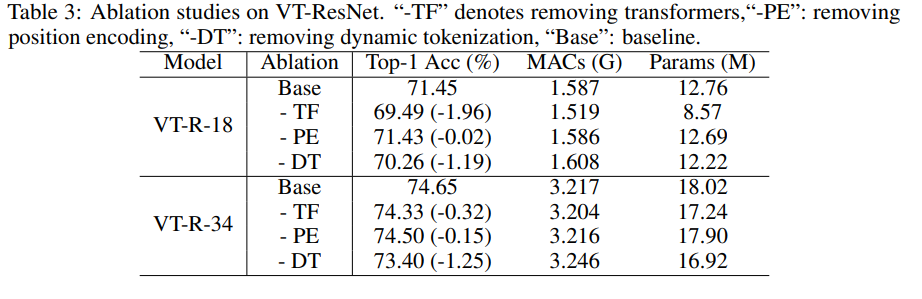
يعطي استخدام المحولات بدلاً من التلافيف أكبر مكاسب. يعطي الترميز الديناميكي بدلاً من الترميز الثابت دفعة كبيرة. يعطي ترميز الموضع تحسنًا طفيفًا فقط.
نتائج التقسيم

كما ترى ، نما المقياس بشكل طفيف فقط ، لكن النموذج يستهلك MAC أقل بمقدار 6.5 مرة.
المستقبل المحتمل للنهج
أظهرت التجارب أن النهج المقترح يسمح للشخص بإنشاء نماذج أكثر كفاءة (من حيث التكاليف الحسابية) ، والتي في نفس الوقت تحقق جودة أفضل. تعمل الهندسة المعمارية المقترحة بنجاح مع المهام المختلفة للرؤية الحاسوبية ، ومن المأمول أن يساعد تطبيقها في تحسين الأنظمة باستخدام رؤية الكمبيوتر - AR / VR ، والسيارات المستقلة ، وغيرها.
أعد المراجعة Andrey Lukyanenko ، المطور الرئيسي لـ MTS.