لذلك ، عندما يحدث استهلاك غير طبيعي للموارد (وحدة المعالجة المركزية ، والذاكرة ، والقرص ، والشبكة ، ...) على واحد من آلاف الخوادم التي يتم التحكم فيها ، فهناك حاجة لمعرفة "من يقع اللوم وماذا يفعل".
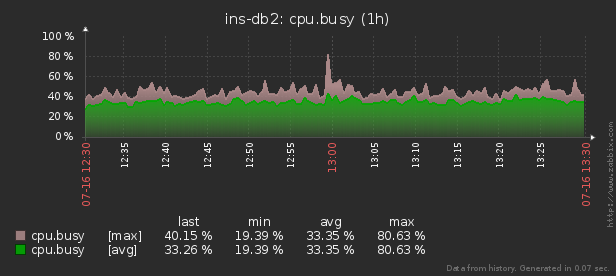
هناك أداة pidstat للمراقبة في الوقت الحقيقي لاستخدام موارد خادم Linux "في الوقت الحالي" . أي ، إذا كانت ذروات التحميل دورية ، فيمكن "تفقيسها" مباشرة في وحدة التحكم. لكننا نريد تحليل هذه البيانات بعد وقوعها ، في محاولة للعثور على العملية التي خلقت الحد الأقصى للحمل على الموارد.
أي ، أود أن أكون قادرًا على إلقاء نظرة على البيانات التي تم جمعها سابقًا ، والتقارير الجميلة المتنوعة مع التجميع والتفاصيل على فترة زمنية مثل هذه:
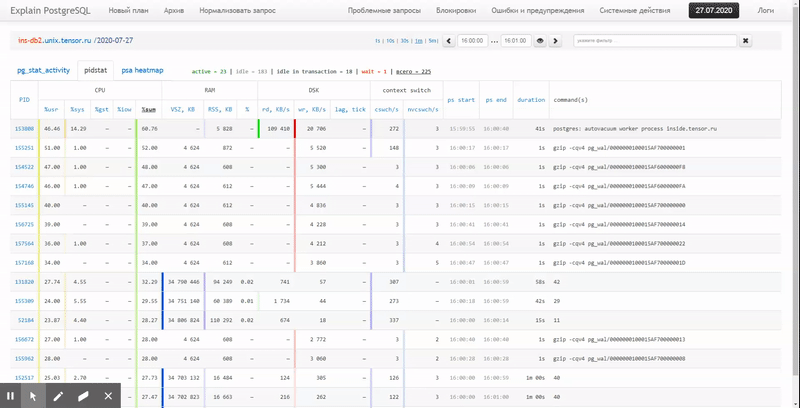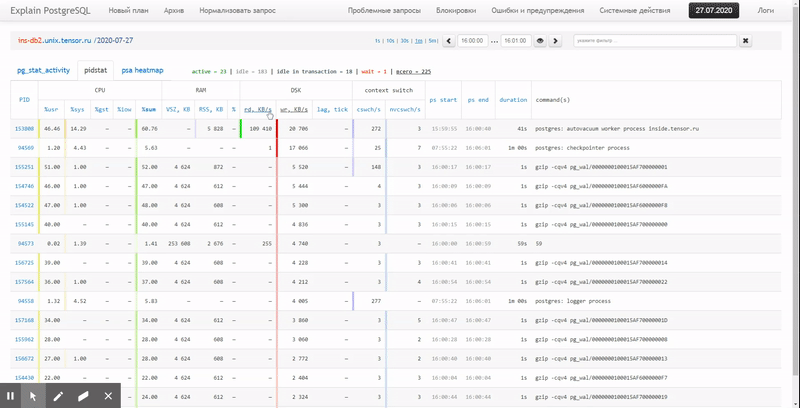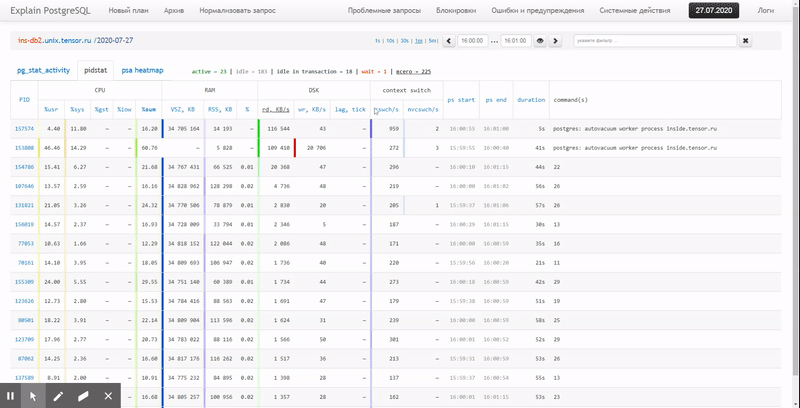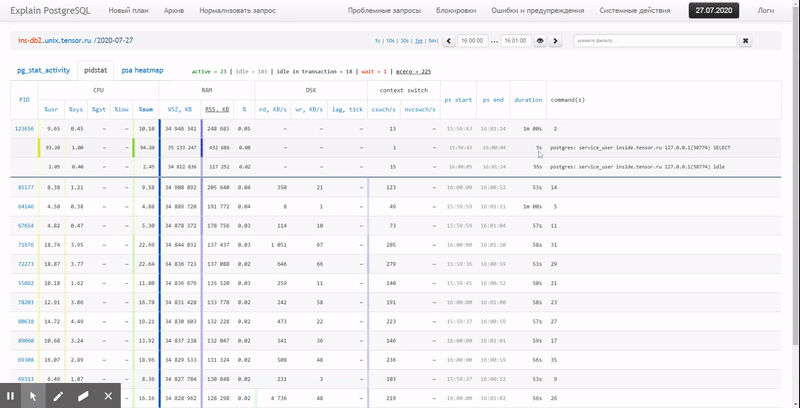
في هذه المقالة ، سننظر في كيفية تحديد كل هذا اقتصاديًا في قاعدة البيانات ، وكيفية جمع تقرير عن هذه البيانات بشكل أكثر فاعلية باستخدام وظائف النافذة و مجموعات التجميع .
أولاً ، دعنا نرى نوع البيانات التي يمكننا استخراجها إذا أخذنا "كل شيء إلى أقصى حد":
pidstat -rudw -lh 1| زمن | UID | PID | ٪ usr | ٪ النظام | ٪ زائر | ٪ وحدة المعالجة المركزية | وحدة المعالجة المركزية | minflt / ثانية | majflt / ثانية | VSZ | RSS | ٪ MEM | kB_rd / ثانية | kB_wr / ثانية | kB_ccwr / ثانية | cswch / ثانية | nvcswch / ثانية | أمر |
| 1594893415 | 0 | 1 | 0.00 | 13.08 | 0.00 | 13.08 | 52 | 0.00 | 0.00 | 197312 | 8512 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7.48 | / usr / lib / systemd / systemd - سويتشيد جذر - نظام - فصل 21 |
| 1594893415 | 0 | تسع | 0.00 | 0.93 | 0.00 | 0.93 | 40 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 350.47 | 0.00 | rcu_sched |
| 1594893415 | 0 | ثلاثة عشر | 0.00 | 0.00 | 0.00 | 0.00 | 1 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 1.87 | 0.00 | الهجرة / 11.87 |
كل هذه القيم مقسمة إلى عدة فئات. يتغير بعضها باستمرار (نشاط وحدة المعالجة المركزية والقرص) ، ونادرًا ما يتغير البعض الآخر (تخصيص الذاكرة) ، والأمر لا يتغير فقط في نفس العملية ، ولكنه يتكرر أيضًا بانتظام على PIDs مختلفة.
الهيكل الأساسي
من أجل البساطة ، دعنا نقصر أنفسنا على مقياس واحد لكل "فئة" سنحفظه:٪ CPU و RSS و Command.
نظرًا لأننا نعلم مسبقًا أن الأمر يتكرر بانتظام ، فسننقله ببساطة إلى قاموس جدول منفصل ، حيث سيعمل تجزئة MD5 كمفتاح UUID:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);وللبيانات نفسها جدول من هذا النوع يناسبنا:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);أود أن ألفت انتباهك إلى حقيقة أنه نظرًا لأن٪ CPU تأتي دائمًا إلينا بدقة 2 منزلين عشريين وبالتأكيد لا تتجاوز 100.00 ، فيمكننا بسهولة ضربها في 100 ووضعها
smallint. من ناحية ، سيوفر لنا هذا مشاكل دقة المحاسبة أثناء العمليات ، ومن ناحية أخرى ، لا يزال من الأفضل تخزين 2 بايت فقط مقارنة بـ 4 بايت realأو 8 بايت double precision.
يمكنك قراءة المزيد حول طرق حزم السجلات بكفاءة في وحدة تخزين PostgreSQL في المقالة "وفر فلسًا جميلًا بكميات كبيرة" ، وحول زيادة إنتاجية قاعدة البيانات للكتابة - في "الكتابة على sublight: مضيف واحد ، يوم واحد ، 1 تيرابايت" .
تخزين "مجاني" للقيم الفارغة
لحفظ أداء النظام الفرعي للقرص لقاعدة البيانات الخاصة بنا والحجم الذي تشغله قاعدة البيانات ، سنحاول تمثيل أكبر قدر ممكن من البيانات في شكل NULL - تخزينها عمليًا "مجاني" ، نظرًا لأنه لا يستغرق سوى القليل في رأس السجل.
يمكن العثور على مزيد من المعلومات حول الآليات الداخلية لتمثيل السجلات في PostgreSQL في حديث نيكولاي شابلوف في PGConf.Russia 2016 "ما بداخلها: تخزين البيانات بمستوى منخفض . " الشريحة رقم 16 مخصصة للتخزين الفارغ .دعنا نلقي نظرة فاحصة على أنواع بياناتنا:
-
يتغير CPU / DSK باستمرار ، ولكن غالبًا ما يتحول إلى الصفر - لذلك من المفيد كتابة NULL بدلاً من 0 إلى القاعدة . -
نادرًا ما يتم إجراء تغييرات على RSS / CMD - لذلك سنكتب NULL بدلاً من التكرار داخل PID نفسه.
اتضح أن صورة مثل هذه ، إذا نظرت إليها في سياق PID معين: من

الواضح أنه إذا بدأت عمليتنا في تنفيذ أمر آخر ، فمن المحتمل أيضًا أن تكون قيمة الذاكرة المستخدمة مختلفة عن السابق - لذلك سنتفق على أنه عند تغيير CMD ، ستكون قيمة RSS أيضًا إصلاح بغض النظر عن القيمة السابقة.
أي أن الإدخال الذي يحتوي على قيمة CMD معبأة له قيمة RSS أيضًا . دعونا نتذكر هذه اللحظة ، ستظل مفيدة لنا.
تجميع تقرير جميل
دعنا الآن نجمع استعلامًا يوضح لنا مستهلكي الموارد لمضيف معين في فترة زمنية محددة.
ولكن لنفعل ذلك على الفور مع الحد الأدنى من استخدام الموارد - على غرار المقالة حول SELF JOIN ووظائف النافذة .
استخدام المعلمات الواردة
من أجل عدم تحديد قيم معلمات التقرير (أو $ 1 / $ 2) في عدة أماكن أثناء استعلام SQL ، نختار CTE من حقل json الوحيد الذي توجد فيه هذه المعلمات بواسطة المفاتيح:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
استرجاع البيانات الأولية
نظرًا لأننا لم نخترع أي تجميعات معقدة ، فإن الطريقة الوحيدة لتحليل البيانات هي قراءتها. لهذا نحتاج إلى فهرس واضح:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
تجميع مفتاح التحليل
لكل PID تم العثور عليه ، حدد الفاصل الزمني لنشاطه وأخذ CMD من السجل الأول في هذه الفترة الزمنية.
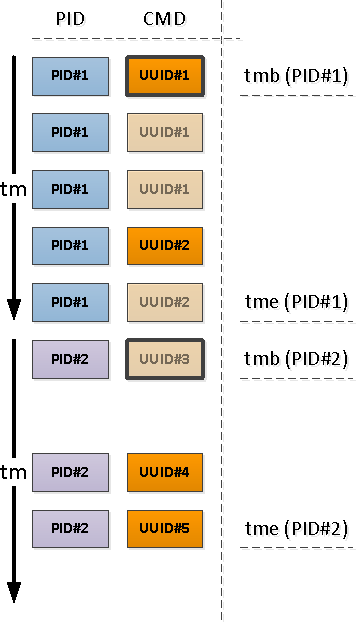
للقيام بذلك ، سوف نستخدم وظائف فريدة من خلال
DISTINCT ONونافذة:
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
حدود نشاط العملية
لاحظ أنه بالنسبة إلى بداية الفاصل الزمني لدينا ، قد يكون السجل الأول الذي يأتي عبر إما واحدًا يحتوي بالفعل على حقل CMD مملوء (PID # 1 في الصورة أعلاه) ، أو مع NULL ، مما يشير إلى استمرار القيمة "أعلاه" في التسلسل الزمني (PID # 2 ).
تلك الخاصة بـ PIDs التي تم تركها بدون CMD نتيجة للعملية السابقة بدأت قبل بداية الفاصل الزمني لدينا ، مما يعني أنه يجب العثور على هذه "البدايات":

نظرًا لأننا نعلم على وجه اليقين أن المقطع التالي من النشاط يبدأ بقيمة CMD معبأة (وهناك RSS معبأ ، مما يعني ) ، سيساعدنا المؤشر الشرطي هنا:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
إذا أردنا (وأردنا) معرفة وقت انتهاء نشاط المقطع ، فسيتعين علينا استخدام "اتجاهين" لكل PID لتحديد الحد الأدنى.
لقد استخدمنا بالفعل أسلوبًا مشابهًا في PostgreSQL Antipatterns: Registry Navigation .

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
تحويل JSON لتنسيقات المنشور
لاحظ أننا اخترنا
precmd/pstcmdفقط تلك الحقول التي تؤثر على الأسطر اللاحقة ، وأي وحدة CPU / DSK تتغير باستمرار - لا. لذلك ، يختلف تنسيق السجلات في الجدول الأصلي و CTE بالنسبة لنا. ليس هناك أى مشكلة!
- row_to_json - حوّل كل سجل يحتوي على حقول إلى كائن json
- array_agg - جمع كل الإدخالات في '{...}' :: json []
- array_to_json - تحويل مصفوفة من JSON إلى مصفوفة JSON '[...]' :: json
- json_populate_recordset - إنشاء مجموعة مختارة من بنية معينة من مصفوفة JSON
هنا نستخدم مكالمة واحدةنلصق "البدايات" و "النهايات" التي تم العثور عليها في كومة مشتركة ونضيفها إلى المجموعة الأصلية من السجلات:json_populate_recordsetبدلاً من مكالمة متعددةjson_populate_record، لأنها مبتذلة أسرع بكثير.
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
ملء الفراغات
دعنا نستخدم النموذج الذي تمت مناقشته في المقالة "SQL HowTo: Build Chains with Window Functions" .أولاً ، لنحدد مجموعات "التكرار":
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
علاوة على ذلك ، وفقًا لـ CMD و RSS ، ستكون المجموعات مستقلة عن بعضها البعض ، لذلك قد تبدو كما يلي:
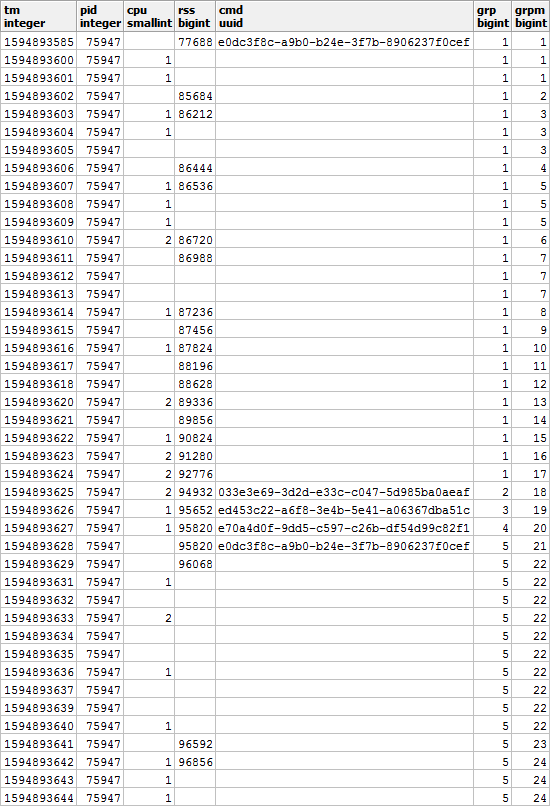
املأ الفجوات في RSS وحساب مدة كل مقطع من أجل مراعاة توزيع الحمل بشكل صحيح بمرور الوقت:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
متعدد المجموعات مع مجموعات التجميع
نظرًا لأننا نريد أن نرى نتيجة كل من المعلومات الموجزة للعملية بأكملها وتفاصيلها حسب قطاعات مختلفة من النشاط ، فسنستخدم التجميع حسب عدة مجموعات من المفاتيح في وقت واحد باستخدام مجموعات المجموعات :
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
(array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]تسمح لنا حالة الاستخدام بالحصول على أول قيمة غير فارغة (حتى لو لم تكن أول قيمة) من المجموعة بأكملها عند التجميع ، بدون إيماءات إضافية .القاموس بدلاً من الانضمام
قم بإنشاء "قاموس" CMD لجميع الأجزاء التي تم العثور عليها:
يمكنك قراءة المزيد عن تقنية "إتقان" في مقالة "PostgreSQL Antipatterns: فلنصل إلى رابط ثقيل باستخدام قاموس" .
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
والآن نستخدمه بدلاً من ذلك
JOIN، للحصول على البيانات "الجميلة" النهائية:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;
أخيرًا ، لنتأكد من أن

استعلامنا بالكامل قد تبين أنه خفيف جدًا عند تنفيذه: [انظر إلى الشرح. tensor.ru]
تمت قراءة 44 مللي ثانية و 33 ميجا بايت فقط من البيانات!