
المصدر: unsplash.com
وفقًا لجاكي ستيوارت ، بطل العالم للفورمولا 1 ثلاث مرات ، فإن فهم السيارة قد ساعده على أن يصبح سائقًا أفضل: "لا يجب أن يكون المتسابق مهندسًا ، بل مهتمًا بالميكانيكا ."
قام Martin Thompson (منشئ LMAX Disruptor ) بتطبيق هذا المفهوم على البرمجة. باختصار ، سيؤدي فهم الأجهزة الأساسية إلى تحسين مهاراتك عندما يتعلق الأمر بتصميم الخوارزميات وهياكل البيانات وما إلى ذلك.
قام فريق Mail.ru Cloud Solutions بترجمة مقالة تعمقت أكثر في تصميم المعالج ونظر في كيف يمكن أن يساعدك فهم بعض مفاهيم وحدة المعالجة المركزية في اتخاذ قرارات أفضل.
أساسيات
تعتمد المعالجات الحديثة على مفهوم المعالجة المتعددة المتماثلة (SMP). تم تصميم المعالج بطريقة تشترك فيه نوى أو أكثر في ذاكرة مشتركة (تسمى أيضًا ذاكرة الوصول الرئيسية أو العشوائية).
بالإضافة إلى ذلك ، لتسريع الوصول إلى الذاكرة ، يحتوي المعالج على العديد من مستويات التخزين المؤقت: L1 و L2 و L3. تعتمد البنية الدقيقة على الشركة المصنعة وطراز وحدة المعالجة المركزية وعوامل أخرى. في معظم الأحيان ، تعمل مخابئ L1 و L2 محليًا لكل نواة ، بينما يتم مشاركة L3 عبر جميع النوى.

بنية SMP
كلما اقتربت ذاكرة التخزين المؤقت من قلب المعالج ، انخفض وقت الوصول وحجم التخزين المؤقت:
| مخبأ | تأخير | دورات وحدة المعالجة المركزية | الحجم |
| لام 1 | ~ 1.2 نانوثانية | ~ 4 | بين 32 و 512 كيلوبايت |
| لام 2 | ~ 3 نانوثانية | ~ 10 | بين 128 كيلو بايت و 24 ميجا بايت |
| لام 3 | ~ 12 نانوثانية | ~ 40 | بين 2 و 32 ميغابايت |
مرة أخرى ، تعتمد الأرقام الدقيقة على طراز المعالج. للحصول على تقدير تقريبي ، إذا استغرق الوصول إلى الذاكرة الرئيسية 60 نانوثانية ، فإن الوصول إلى L1 أسرع بحوالي 50 مرة.
في عالم المعالج ، هناك مفهوم مهم لمحلية الارتباط . عندما يصل المعالج إلى موقع ذاكرة معين ، فمن المحتمل جدًا أن:
- سيشير إلى نفس موقع الذاكرة في المستقبل القريب - هذا هو مبدأ المكان المحلي .
- سوف يشير إلى خلايا الذاكرة الموجودة في مكان قريب - وهذا هو مبدأ التجمع عن بعد .
المنطقة الزمنية هي أحد أسباب ذاكرة التخزين المؤقت لوحدة المعالجة المركزية. ولكن كيف تستخدم موقع المسافة؟ الحل - بدلاً من نسخ خلية ذاكرة واحدة إلى ذاكرة التخزين المؤقت لوحدة المعالجة المركزية ، يتم نسخ سطر ذاكرة التخزين المؤقت هناك. خط التخزين المؤقت هو جزء متجاور من الذاكرة.
يعتمد حجم خط التخزين المؤقت على مستوى التخزين المؤقت (ومرة أخرى على طراز المعالج). على سبيل المثال ، إليك حجم سطر ذاكرة التخزين المؤقت L1 على جهازي:
$ sysctl -a | grep cacheline
hw.cachelinesize: 64
بدلاً من نسخ متغير واحد إلى ذاكرة التخزين المؤقت L1 ، يقوم المعالج بنسخ مقطع 64 بايت متجاور هناك. على سبيل المثال ، بدلاً من نسخ عنصر int64 واحد لشريحة Go ، فإنه ينسخ هذا العنصر بالإضافة إلى سبعة عناصر int64 أخرى.
استخدامات محددة لخطوط التخزين المؤقت في الذهاب
دعونا نلقي نظرة على مثال ملموس يوضح فوائد ذاكرة التخزين المؤقت للمعالج. في الكود التالي ، نضيف مصفوفتين مربعتين لعناصر int64:
func BenchmarkMatrixCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[i][j]
}
}
}
}
إذا كان
matrixLengthيساوي 64 كيلو ، فإنه ينتج النتيجة التالية:
BenchmarkMatrixSimpleCombination-64000 8 130724158 ns/op
الآن ، بدلاً من ذلك ،
matrixB[i][j]سنضيف matrixB[j][i]:
func BenchmarkMatrixReversedCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[j][i]
}
}
}
}
هل سيؤثر ذلك على النتائج؟
BenchmarkMatrixCombination-64000 8 130724158 ns/op
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
نعم ، لقد فعلت ذلك ، وبشكل جذري للغاية! كيف يمكن تفسير هذا؟
دعونا نحاول رسم ما يحدث. تشير الدائرة الزرقاء إلى المصفوفة الأولى وتشير الدائرة الوردية إلى الثانية. عندما نضع
matrixA[i][j] = matrixA[i][j] + matrixB[j][i]، يكون المؤشر الأزرق في الموضع (4.0) والوردي في الموضع (0.4):
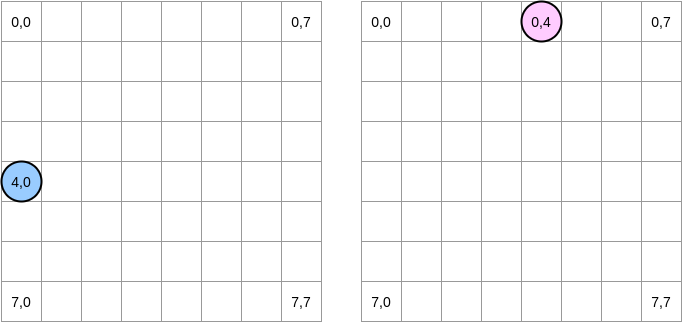
ملاحظة . في هذا الرسم البياني ، يتم عرض المصفوفات في شكل رياضي: مع وجود إحداثي وإحداثيات ، والموضع (0،0) في المربع العلوي الأيسر. في الذاكرة ، يتم ترتيب جميع صفوف المصفوفة بالتسلسل. ومع ذلك ، من أجل الوضوح ، دعونا نلقي نظرة على التمثيل الرياضي. علاوة على ذلك ، في الأمثلة التالية ، يكون حجم المصفوفة مضاعفًا لحجم خط التخزين المؤقت. لذلك ، لن "يلحق" سطر ذاكرة التخزين المؤقت في الصف التالي. يبدو الأمر معقدًا ، لكن الأمثلة ستوضح كل شيء.
كيف سنكرر المصفوفات؟ يتحرك المؤشر الأزرق إلى اليمين حتى يصل إلى العمود الأخير ثم ينتقل إلى الصف التالي في الموضع (5،0) وهكذا. على العكس ، يتحرك المؤشر الوردي لأسفل ثم ينتقل إلى العمود التالي.
عندما يصل المؤشر الوردي إلى الموضع (0.4) ، يقوم المعالج بتخزين الخط بالكامل (في مثالنا ، حجم خط التخزين المؤقت هو أربعة عناصر). لذا عندما يصل المؤشر الوردي إلى الموضع (0.5) ، يمكننا أن نفترض أن المتغير موجود بالفعل في L1 ، أليس كذلك؟
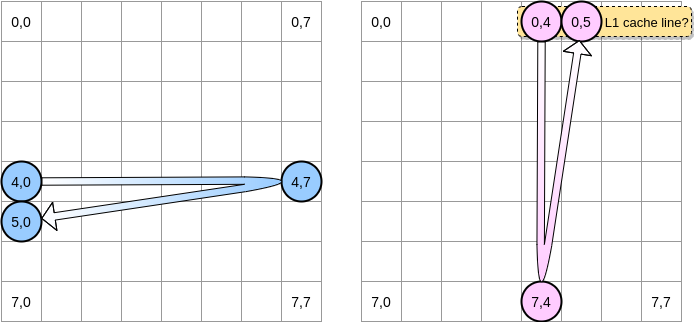
يعتمد الجواب على حجم المصفوفة :
- إذا كانت المصفوفة صغيرة بما يكفي مقارنة بحجم L1 ، فبالتأكيد سيتم تخزين العنصر (0.5) مؤقتًا.
- وإلا ، سيتم إزالة خط التخزين المؤقت من L1 قبل أن يصل المؤشر إلى الموضع (0.5). لذلك ، ستنشئ ذاكرة تخزين مؤقت مفقودة وسيتعين على المعالج الوصول إلى المتغير بطريقة مختلفة ، على سبيل المثال عبر L2. سنكون في هذه الحالة:
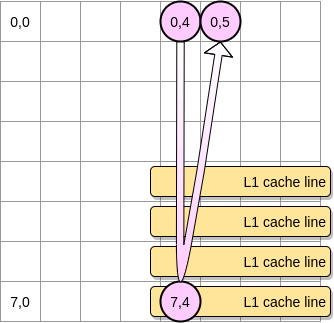
إلى أي مدى يجب أن تكون المصفوفة صغيرة للاستفادة من L1؟ دعنا نحسب قليلا. أولاً ، تحتاج إلى معرفة حجم ذاكرة التخزين المؤقت L1:
$ sysctl hw.l1dcachesize
hw.l1icachesize: 32768
على جهازي ، ذاكرة التخزين المؤقت L1 هي 32،768 بايت بينما يكون خط ذاكرة التخزين المؤقت L1 64 بايت. بهذه الطريقة ، يمكنني تخزين ما يصل إلى 512 سطرًا من ذاكرة التخزين المؤقت في L1. ماذا لو قمنا بتشغيل نفس المعيار مع 512 عنصر مصفوفة؟
BenchmarkMatrixCombination-512 1404 718594 ns/op
BenchmarkMatrixReversedCombination-512 1363 850141 ns/opp
على الرغم من أننا أصلحنا الفجوة (في مصفوفة 64 كيلو كان الفرق حوالي 4 مرات) ، لا يزال بإمكاننا ملاحظة فرق طفيف. ماذا يمكن أن يكون الخطأ؟ في المعايير ، نعمل مع مصفوفتين. وبالتالي ، يجب على المعالج الاحتفاظ بخطوط التخزين المؤقت لكليهما. في عالم مثالي (لا توجد تطبيقات أخرى قيد التشغيل وما إلى ذلك) ، يتم تخزين ذاكرة التخزين المؤقت L1 بنسبة 50٪ بالبيانات من المصفوفة الأولى و 50٪ من الثانية. ماذا لو قللنا حجم المصفوفة بمقدار النصف للعمل مع 256 عنصر:
BenchmarkMatrixCombination-256 5712 176415 ns/op
BenchmarkMatrixReversedCombination-256 6470 164720 ns/op
أخيرًا ، وصلنا إلى النقطة التي تكون فيها النتيجتان متكافئتين (تقريبًا).
. ? , Go. - LEA (Load Effective Address). , . LEA .
, int64 , LEA , 8 . , . , . , () .
الآن - كيفية الحد من تأثير أخطاء التخزين المؤقت في حالة مصفوفة أكبر؟ هناك طريقة تسمى تحسين الحلقات المتداخلة (تحسين عش الحلقة). لتحقيق أقصى استفادة من خطوط ذاكرة التخزين المؤقت ، يجب علينا التكرار فقط داخل كتلة معينة.
دعونا نحدد كتلة في مثالنا كمربع من 4 عناصر. في المصفوفة الأولى نتكرر من (4.0) إلى (4.3). ثم انتقل إلى الصف التالي. وفقًا لذلك ، فإننا نكرر المصفوفة الثانية فقط من (0.4) إلى (3.4) قبل الانتقال إلى العمود التالي.
عندما يمر المؤشر الوردي فوق العمود الأول ، يقوم المعالج بتخزين خط التخزين المؤقت المقابل. وبالتالي ، فإن تجاوز بقية الكتلة يعني الاستفادة من L1:
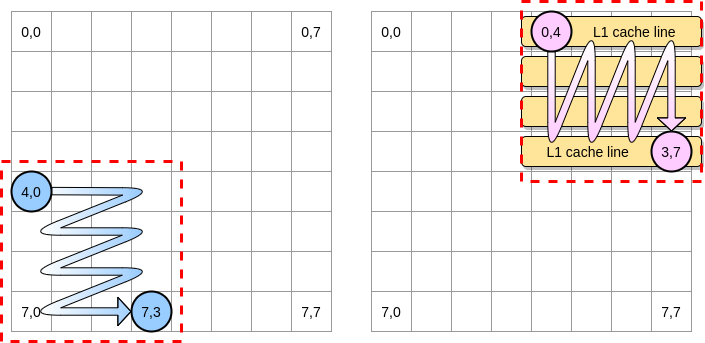
دعنا نكتب تنفيذًا لهذه الخوارزمية في Go ، ولكن يجب علينا أولاً اختيار حجم الكتلة بعناية. في المثال السابق ، كان يساوي سطر ذاكرة التخزين المؤقت. يجب ألا يكون أصغر ، وإلا فإننا سوف نقوم بتخزين العناصر التي لن تكون متاحة.
في معيار Go الخاص بنا ، نقوم بتخزين عناصر int64 (8 بايت لكل منها). يبلغ حجم ذاكرة التخزين المؤقت 64 بايت ، لذا يمكنه استيعاب 8 عناصر. ثم يجب أن تكون قيمة حجم الكتلة 8 على الأقل:
func BenchmarkMatrixReversedCombinationPerBlock(b *testing.B){
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
blockSize := 8
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i += blockSize {
for j := 0; j < matrixLength; j += blockSize {
for ii := i; ii < i+blockSize; ii++ {
for jj := j; jj < j+blockSize; jj++ {
matrixA[ii][jj] = matrixA[ii][jj] + matrixB[jj][ii]
}
}
}
}
}
}
أصبح تنفيذنا الآن أكثر من 67٪ أسرع مما كان عليه عندما قمنا بالتكرار عبر الصف / العمود بأكمله:
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
BenchmarkMatrixReversedCombinationPerBlock-64000 6 185375690 ns/op
كان هذا هو المثال الأول لإثبات أن فهم ذاكرة التخزين المؤقت لوحدة المعالجة المركزية يمكن أن يساعد في تصميم خوارزميات أكثر كفاءة.
مشاركة كاذبة
نحن نفهم الآن كيف يدير المعالج ذاكرة التخزين المؤقت الداخلية. كموجز سريع:
- يجبر مبدأ المكان عن بعد المعالج على أخذ ليس فقط عنوان ذاكرة واحد ، ولكن خط ذاكرة التخزين المؤقت.
- ذاكرة التخزين المؤقت L1 محلية لمعالج واحد.
الآن دعنا نناقش مثال مع تماسك ذاكرة التخزين المؤقت L1. تخزن الذاكرة الرئيسية متغيرين
var1و var2. يصل خيط واحد على نواة واحدة var1، بينما يصل خيط آخر على نواة أخرى var2. بافتراض أن كلا المتغيرين متواصلين (أو متواصلين تقريبًا) ، فإننا ننتهي في حالة يكون فيها var2موجودًا في كلا المؤقتين.
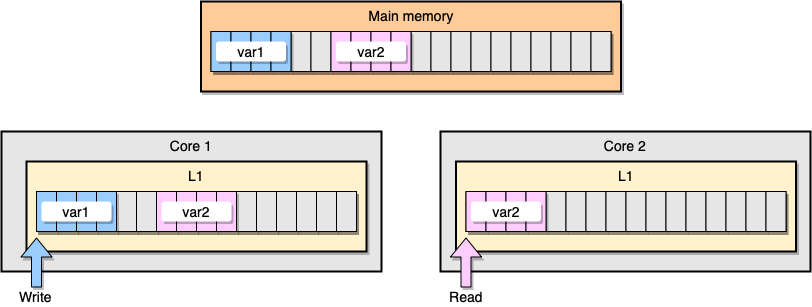
مثال على ذاكرة التخزين المؤقت L1
ماذا يحدث إذا قام مؤشر الترابط الأول بتحديث خط ذاكرة التخزين المؤقت؟ من المحتمل أن يقوم بتحديث أي مكان في سلسلته بما في ذلك
var2. ثم ، عندما يقرأ مؤشر الترابط الثاني var2، قد لا تكون القيمة متناسقة.
كيف يحافظ المعالج على ذاكرة التخزين المؤقت متماسكة؟ إذا كان هناك خطان لذاكرة التخزين المؤقت يحتويان على عناوين مشتركة ، فإن المعالج يميزهما على أنهما مشتركان. إذا قام أحد مؤشرات الترابط بتعديل خط مشترك ، فإنه يشير إلى أنهما معدّلان. التنسيق بين النوى مطلوب لضمان تماسك المخازن المؤقتة ، مما قد يؤدي إلى تدهور كبير في أداء التطبيق. هذه المشكلة تسمى المشاركة الزائفة .
لنفكر في تطبيق Go محدد. في هذا المثال ، نقوم بإنشاء هيكلين واحدًا تلو الآخر. لذلك ، يجب أن تكون هذه الهياكل متسلسلة في الذاكرة. ثم نقوم بإنشاء اثنين من الغوروتينات ، يشير كل منهما إلى هيكله الخاص (M هو ثابت يساوي مليون):
type SimpleStruct struct {
n int
}
func BenchmarkStructureFalseSharing(b *testing.B) {
structA := SimpleStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
في هذا المثال ، المتغير n للهيكل الثاني متاح فقط للغروتين الثاني. ومع ذلك ، نظرًا لأن الهياكل متلاصقة في الذاكرة ، فسيكون المتغير موجودًا على كلا خطي التخزين المؤقت (بافتراض أن كلا من الغوروتين يتم جدولتهما على خيوط على نوى منفصلة ، وهذا ليس هو الحال بالضرورة). هذه هي النتيجة المعيارية:
BenchmarkStructureFalseSharing 514 2641990 ns/op
كيف تمنع مشاركة المعلومات الخاطئة؟ حل واحد هو الذاكرة الكاملة (حشو الذاكرة). هدفنا هو التأكد من وجود مساحة كافية بين متغيرين بحيث تنتمي إلى خطوط ذاكرة التخزين المؤقت المختلفة.
أولاً ، دعنا ننشئ بديلاً للهيكل السابق عن طريق ملء الذاكرة بعد تعريف المتغير:
type PaddedStruct struct {
n int
_ CacheLinePad
}
type CacheLinePad struct {
_ [CacheLinePadSize]byte
}
const CacheLinePadSize = 64
ثم نقوم بإنشاء هيكلين ونستمر في الوصول إلى هذين المتغيرين في غوروتينات منفصلة:
func BenchmarkStructurePadding(b *testing.B) {
structA := PaddedStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
من منظور الذاكرة ، يجب أن يبدو هذا المثال وكأن المتغيرين جزء من خطوط ذاكرة التخزين المؤقت المختلفة:
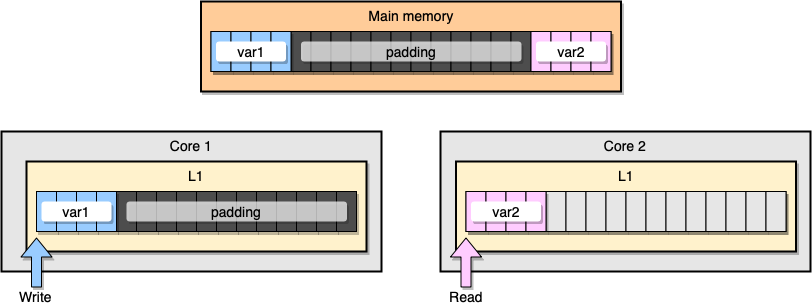
ملء الذاكرة
دعونا نلقي نظرة على النتائج:
BenchmarkStructureFalseSharing 514 2641990 ns/op
BenchmarkStructurePadding 735 1622886 ns/op
المثال الثاني لملء الذاكرة أسرع بحوالي 40٪ من التنفيذ الأصلي. ولكن هناك أيضًا جانب سلبي. تعمل الطريقة على تسريع الرمز ، ولكنها تتطلب المزيد من الذاكرة.
ميكانيكا الإعجاب هي مفهوم مهم عندما يتعلق الأمر بتحسين التطبيقات. في هذه المقالة ، رأينا أمثلة على كيف ساعدنا فهم وحدة المعالجة المركزية في تحسين سرعة البرنامج.
ماذا تقرأ: