
كيف يمكنني التوفير في تكاليف السحابة عند العمل مع Kubernetes؟ لا يوجد حل واحد مناسب ، لكن هذه المقالة توفر العديد من الأدوات لمساعدتك في إدارة الموارد بشكل أكثر كفاءة وتقليل تكاليف الحوسبة السحابية.
لقد كتبت هذا المقال مع وضع Kubernetes لخدمة AWS في الاعتبار ، ولكنها ستنطبق (تقريبًا) بنفس الطريقة لمقدمي الخدمات السحابية الآخرين. أفترض أن مجموعتك (مجموعاتك) لديها بالفعل تهيئة تلقائية للتحجيم ( الكتلة - autoscaler ). ستوفر لك إزالة الموارد وتقليص عملية النشر الخاصة بك فقط إذا كانت تقلل أيضًا من أسطول العقد العمالية (حالات EC2).
ستغطي هذه المقالة:
- تنظيف الموارد غير المستخدمة ( kube-janitor )
- تصغير خلال ساعات التوقف ( kube-downscaler )
- باستخدام المقياس الذاتي الأفقي (HPA) ،
- الحد من الإفراط في حجز الموارد ( kube-resource-report ، VPA)
- باستخدام الحالات الموضعية
تنظيف الموارد غير المستخدمة
العمل في بيئة سريعة الوتيرة أمر رائع. نريد تسريع المنظمات التقنية . يعني التسليم السريع للبرامج أيضًا المزيد من عمليات نشر العلاقات العامة وبيئات المعاينة والنماذج الأولية وحلول التحليلات. نشر كل شيء على Kubernetes. من لديه الوقت لتنظيف نشرات الاختبار يدويًا؟ من السهل نسيان حذف التجربة قبل أسبوع. سترتفع فاتورة السحابة في النهاية نظرًا لحقيقة نسيان إغلاقها:

(Henning Jacobs:
Zhiza:
(نقلت) Corey Quinn:
أسطورة: حسابك في AWS هو دالة لعدد المستخدمين.
الحقيقة: حسابك في AWS هو وظيفة لعدد
مهندسيك . Ivan Kurnosov (رداً):
حقيقة: حساب AWS الخاص بك هو دالة لعدد الأشياء التي نسيت تعطيلها / حذفها.)
يساعد Kubernetes Janitor (kube-janitor) في تنظيف مجموعتك. تكوين بواب المرنة مرن للاستخدام العالمي والمحلي:
- يمكن للقواعد العامة للمجموعة بأكملها تحديد الحد الأقصى لوقت البقاء (TTL) لعمليات نشر العلاقات العامة / الاختبار.
- يمكن التعليق على الموارد الفردية باستخدام بواب / ttl ، على سبيل المثال ، لإزالة سبايك / النموذج الأولي تلقائيًا بعد 7 أيام.
يتم تحديد القواعد العامة في ملف YAML. يتم تمرير مسارها من خلال المعلمة
--rules-fileإلى kube-janitor. في ما يلي مثال على قاعدة لإزالة جميع مساحات الأسماء -pr-باسم بعد يومين:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dينظم المثال التالي استخدام ملصق التطبيق على لوحات النشر و StatefulSet لجميع عمليات النشر / StatefulSet الجديدة في عام 2020 ، ولكنه يسمح في نفس الوقت بتنفيذ الاختبارات بدون هذا التصنيف لمدة أسبوع:
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dتشغيل عرض توضيحي محدود الوقت لمدة 30 دقيقة على الكتلة حيث يعمل kube-janitor:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mمصدر آخر لارتفاع التكاليف هو الأحجام الثابتة (AWS EBS). لا يؤدي حذف Kubernetes StatefulSet إلى حذف مجلداته الثابتة (PVCs - PersistentVolumeClaim). يمكن أن تؤدي الكميات غير المستخدمة من EBS بسهولة إلى تكاليف مئات الدولارات في الشهر. Kubernetes Janitor لديه ميزة لتنظيف PVC غير المستخدمة. على سبيل المثال ، ستزيل هذه القاعدة جميع PVCs التي لم يتم تركيبها بواسطة الوحدة والتي لم يتم الرجوع إليها بواسطة StatefulSet أو CronJob:
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hيمكن أن يساعدك Kubernetes Janitor في الحفاظ على نظافة المجموعة الخاصة بك ومنع تكاليف الحوسبة السحابية المتراكمة ببطء. للحصول على إرشادات النشر والتكوين ، اتبع README kube-janitor .
تصغير خارج المكتب
عادة ما تكون أنظمة الاختبار والتدريج مطلوبة للعمل فقط خلال ساعات العمل. تتطلب بعض تطبيقات الإنتاج ، مثل أدوات المكتب الخلفي / المشرف ، توفرًا محدودًا وقد يتم تعطيلها ليلاً.
يسمح Kubernetes Downscaler (kube- downscaler ) للمستخدمين والمشغلين بتقليص حجم النظام بعد ساعات. يمكن أن تتدرج عمليات النشر و StatefulSets إلى النسخ المتماثلة صفر. قد يتم إيقاف CronJobs مؤقتًا. تم تكوين Kubernetes Downscaler للمجموعة بأكملها أو مساحة اسم واحدة أو أكثر أو موارد فردية. يمكنك تعيين "وقت الخمول" أو العكس "وقت التشغيل". على سبيل المثال ، لتقليل الحجم قدر الإمكان بين عشية وضحاها وعطلات نهاية الأسبوع:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeفي ما يلي رسم بياني لتغيير حجم عقد عمل المجموعة خلال عطلة نهاية الأسبوع:

من المؤكد أن تغيير الحجم من ~ 13 إلى 4 عقد عمل يُحدث فرقًا كبيرًا في فاتورة AWS.
ولكن ماذا لو كنت بحاجة إلى العمل أثناء "وقت التوقف" عن المجموعة؟ يمكن استبعاد عمليات نشر معينة نهائيًا من القياس عن طريق إضافة أداة تغيير الحجم / الاستبعاد: تعليق توضيحي حقيقي. يمكن استبعاد عمليات النشر مؤقتًا باستخدام التعليق التوضيحي لأسفل / الاستبعاد - حتى مع الطابع الزمني المطلق بتنسيق YYYY-MM-DD HH: MM (UTC). إذا لزم الأمر ، يمكن تحجيم المجموعة بأكملها عن طريق نشر جراب مشروح
downscaler/force-uptime، على سبيل المثال عن طريق تشغيل دمية nginx:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueراجع أداة README kube-downscaler للحصول على تعليمات النشر والخيارات الإضافية.
استخدم مقياس تلقائي أفقي
تتعامل العديد من التطبيقات / الخدمات مع نظام تحميل ديناميكي: أحيانًا تكون وحداتها خاملة ، وأحيانًا تعمل بكامل طاقتها. ليس من الاقتصادي العمل مع أسطول ثابت من المداخن للتعامل مع أقصى حمل ذروة. يدعم Kubernetes النطاق التلقائي الأفقي من خلال مورد HorizontalPodAutoscaler (HPA). غالبًا ما يكون استخدام CPU مقياسًا جيدًا للتحجيم:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: Utilizationأنشأت Zalando مكونًا لتوصيل المقاييس المخصصة بسهولة لتغيير الحجم: Kube Metrics Adapter (kube-metrics-adapter) هو محول مقاييس عالمي لـ Kubernetes يمكنه جمع المقاييس المخصصة والخارجية والحفاظ عليها لتغيير حجم الموقد الأفقي. وهو يدعم القياس بناءً على مقاييس Prometheus وقوائم انتظار SQS والتخصيصات الأخرى. على سبيل المثال ، لتوسيع نطاق النشر لمقياس مخصص يمثله التطبيق نفسه كـ JSON in / metrics ، استخدم:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueيجب أن يكون تكوين المقياس التلقائي أفقيًا باستخدام HPA أحد الإجراءات الافتراضية لتحسين الكفاءة للخدمات عديمة الجنسية. يحتوي Spotify على عرض تقديمي بتجاربهم وأفضل الممارسات لـ HPA: قم بتوسيع عمليات النشر الخاصة بك ، وليس محفظتك .
الحد من تكرار الموارد
تحدد أحمال عمل Kubernetes متطلبات وحدة المعالجة المركزية / الذاكرة من خلال "طلبات الموارد". يتم قياس موارد وحدة المعالجة المركزية في النوى الافتراضية أو في كثير من الأحيان في "مليكور" ، على سبيل المثال ، 500 متر يعني 50٪ vCPU. يتم قياس موارد الذاكرة بالبايت ويمكن استخدام اللاحقات الشائعة ، على سبيل المثال 500 ميغا بايت مما يعني 500 ميغا بايت. طلبات الموارد "تحجب" وحدة التخزين في عقد العمل ، أي أن وحدة مع طلب وحدة المعالجة المركزية 1000m على عقدة مع 4 وحدات معالجة مركزية افتراضية ستترك فقط 3 وحدات معالجة افتراضية متاحة للوحدات الأخرى. [1]
الركود (الاحتياطي الزائد)هو الفرق بين الموارد المطلوبة والاستخدام الفعلي. على سبيل المثال ، تحت ، الذي يطلب 2 غيغابايت من الذاكرة ، ولكنه يستخدم فقط 200 ميغا بايت ، لديه ~ 1.8 غيغابايت من الذاكرة "الزائدة". فائض التكاليف يكلف مالا. يمكن تقدير أن 1 جيجا بايت من الذاكرة الزائدة تكلف ~ 10 دولارات في الشهر. [2]
يعرض تقرير موارد Kubernetes ( تقرير موارد kube) احتياطيات زائدة ويمكن أن يساعدك في تحديد الوفورات المحتملة:

تقرير موارد Kubernetesيظهر الفائض المجمّع حسب التطبيق والفريق. هذا يسمح لك بالعثور على الأماكن حيث يمكن تقليل الطلب على الموارد. يقدم تقرير HTML الذي تم إنشاؤه لقطة من استخدام الموارد فقط. يجب أن تنظر في استخدام وحدة المعالجة المركزية / الذاكرة بمرور الوقت لتحديد طلبات الموارد الكافية. فيما يلي رسم تخطيطي لـ Grafana لخدمة "نموذجية" مع حمل كبير لوحدة المعالجة المركزية: تستخدم جميع الكبلات أقل بكثير من 3 نوى وحدة معالجة مركزية مطلوبة: يؤدي
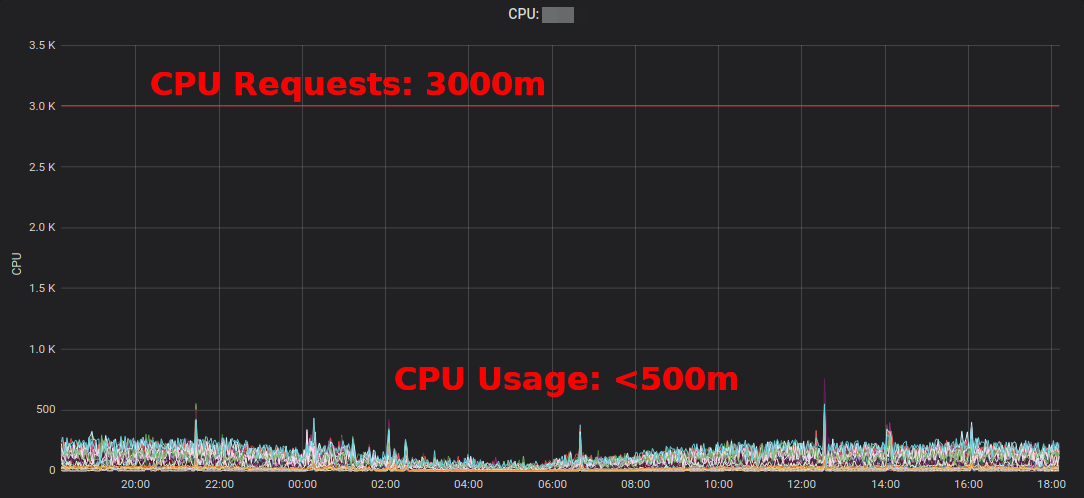
تقليل طلب وحدة المعالجة المركزية من 3000 متر إلى 400 متر إلى توفير الموارد لأحمال العمل الأخرى ويسمح لك بتقليل المجموعة. يكتب Corey Quinn
"متوسط استخدام وحدة المعالجة المركزية لمثيلات EC2 غالبًا ما يتقلب في نطاق النسبة المئوية المكونة من رقم واحد" . في حين أنه بالنسبة لـ EC2 ، قد يكون تقدير الحجم الصحيح قرارًا سيئًايعد تغيير بعض طلبات موارد Kubernetes في ملف YAML أمرًا سهلاً ويمكن أن يحقق وفورات ضخمة.
لكن هل نريد حقًا أن يغير الناس القيم في ملفات YAML؟ لا ، يمكن للآلات القيام بذلك بشكل أفضل! يقوم Kubernetes Vertical Pod Autoscaler (VPA) بذلك فقط: فهو يتكيف مع طلبات الموارد والقيود لتناسب عبء العمل. في ما يلي مثال على رسم بياني لاستعلام Prometheus CPU (خط أزرق رفيع) تم تعديله بواسطة VPA بمرور الوقت:

تستخدم Zalando VPA في كل مجموعاتها لمكونات البنية التحتية. يمكن للتطبيقات غير الحرجة أيضًا استخدام VPA.
المعتدلby Fairwind هي أداة تنشئ VPA لكل عملية نشر في مساحة الاسم ثم تعرض توصية VPA في لوحة المعلومات الخاصة بها. يمكن أن يساعد المطورين في تعيين طلبات وحدة المعالجة المركزية / الذاكرة الصحيحة لتطبيقاتهم:

لقد كتبت منشور مدونة صغير حول VPA في عام 2019 ، ومؤخراً كان هناك نقاش حول VPA في مجتمع المستخدم النهائي لـ CNCF .
استخدام مثيلات EC2 الفورية
أخيرًا وليس آخرًا ، يمكن تقليل تكاليف AWS EC2 باستخدام مثيلات Spot كعقد عمل Kubernetes [3] . تتوافر أمثلة فورية بسعر يصل إلى 90٪ من السعر عند الطلب. يعد تشغيل Kubernetes على EC2 Spot مزيجًا جيدًا: تحتاج إلى تحديد العديد من أنواع المثيلات المختلفة لتوافر أعلى ، مما يعني أنه يمكنك الحصول على عقدة أكبر بنفس السعر أو أقل ، ويمكن استخدام السعة المتزايدة من خلال أحمال عمل Kubernetes في حاويات.
كيف يتم تشغيل Kubernetes على EC2 Spot؟ هناك العديد من الخيارات: استخدم خدمة طرف ثالث مثل SpotInst (تسمى الآن "Spot" ، لا تسألني عن السبب) ، أو فقط أضف Spot AutoScalingGroup (ASG) إلى مجموعتك. على سبيل المثال ، إليك مقتطف CloudFormation لـ Spot ASG "المحسّن للسعة" مع أنواع مثيلات متعددة:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"بعض الملاحظات حول استخدام Spot مع Kubernetes:
- تحتاج إلى معالجة الإكمالات الموضعية ، على سبيل المثال عن طريق تجفيف عقدة عند توقف مثيل
- تستخدم زالاندو مفترق التحجيم التلقائي للمجموعة مع أولويات تجمع العقدة
- يمكن إجبار عقد Spot على قبول تسجيلات عبء العمل للتشغيل على Spot
ملخص
آمل أن تجد بعض الأدوات المعروضة هنا مفيدة في تقليل فاتورة الحوسبة السحابية. يمكنك العثور على معظم محتويات المقالة أيضًا في حديثي في DevOps Gathering 2019 على YouTube وكشرائح .
ما أفضل ممارساتك لتوفير تكاليف السحابة على Kubernetes؟ واسمحوا لي أن أعرف على تويتر (try_except_) .
[1] في الواقع ، ستظل أقل من 3 وحدات معالجة مركزية افتراضية قابلة للاستخدام ، حيث يتم تقليل معدل نقل العقدة بسبب موارد النظام المحجوزة. يميز Kubernetes بين سعة العقدة المادية والموارد "المخصصة" ( Node Allocatable ).
[2] مثال على الحساب: نسخة واحدة من m5.large with 8 GiB of memory هي ~ 84 دولارًا أمريكيًا في الشهر (eu-central-1، On-Demand) ، أي تبلغ عقدة 1/8 حوالي 10 دولارات في الشهر تقريبًا.
[3] هناك العديد من الطرق الأخرى لتقليل حساب EC2 الخاص بك ، مثل المثيلات المحجوزة ، خطة التوفير ، وما إلى ذلك - لن أقوم بتغطية هذه الموضوعات هنا ، ولكن يجب عليك التحقق منها بالتأكيد!
تعلم المزيد عن الدورة.